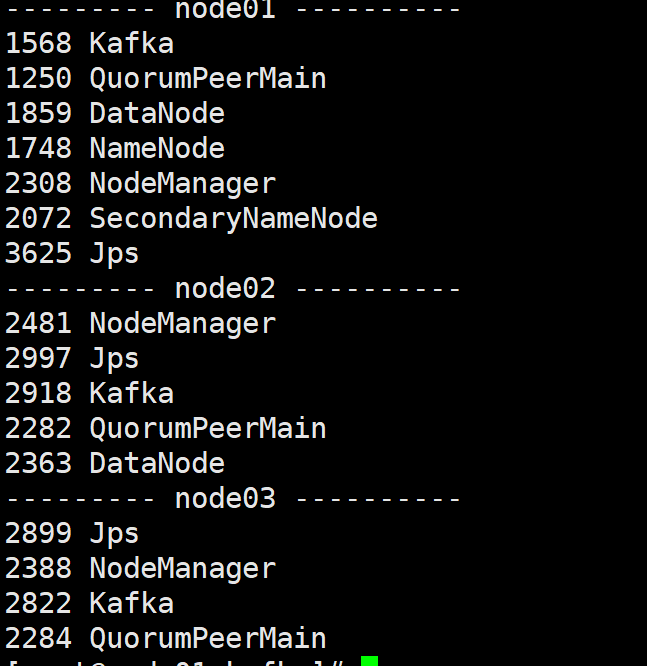
- Kafka数据源的两种API对比
ReceiverAPI:在早期版本中使用,需专门的Executor接收数据再发送给其他Executor计算。由于接收和计算的Executor速度可能不同,当接收速度大于计算速度时,计算节点易出现内存溢出问题,当前版本已不适用。
DirectAPI:由计算的Executor主动消费Kafka数据,速度可自行控制。
- Kafka 0-10 Direct模式实践
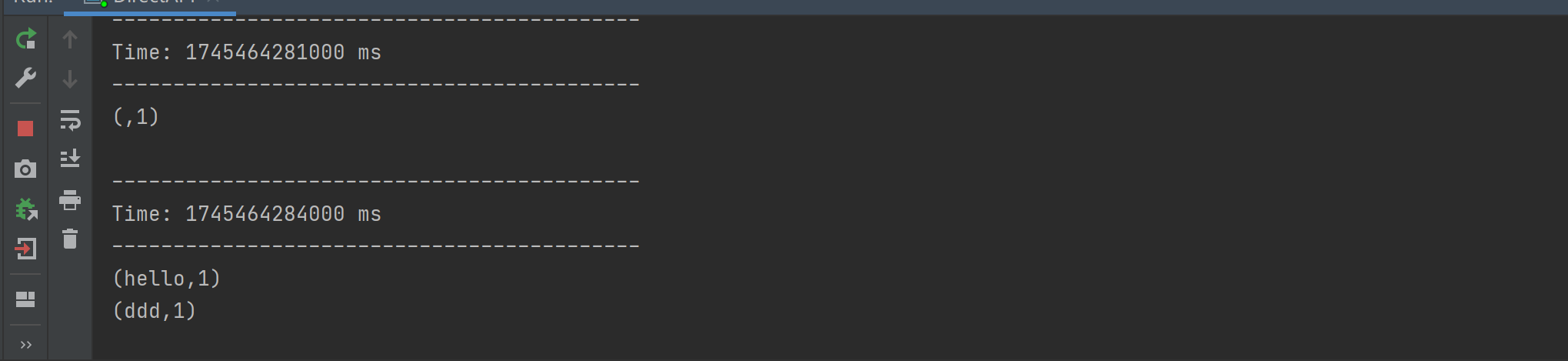
需求:利用SparkStreaming从Kafka读取数据,进行简单计算后打印到控制台。
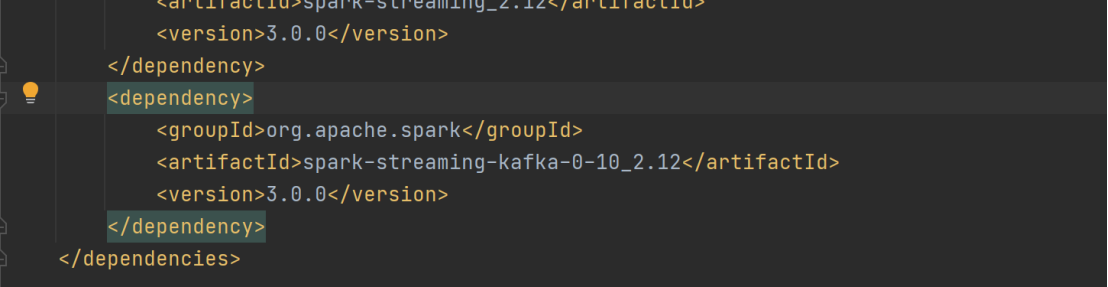
导入依赖:添加 org.apache.spark:spark - streaming - kafka - 0 - 10_2.12:3.0.0 依赖,为后续代码实现提供支持。
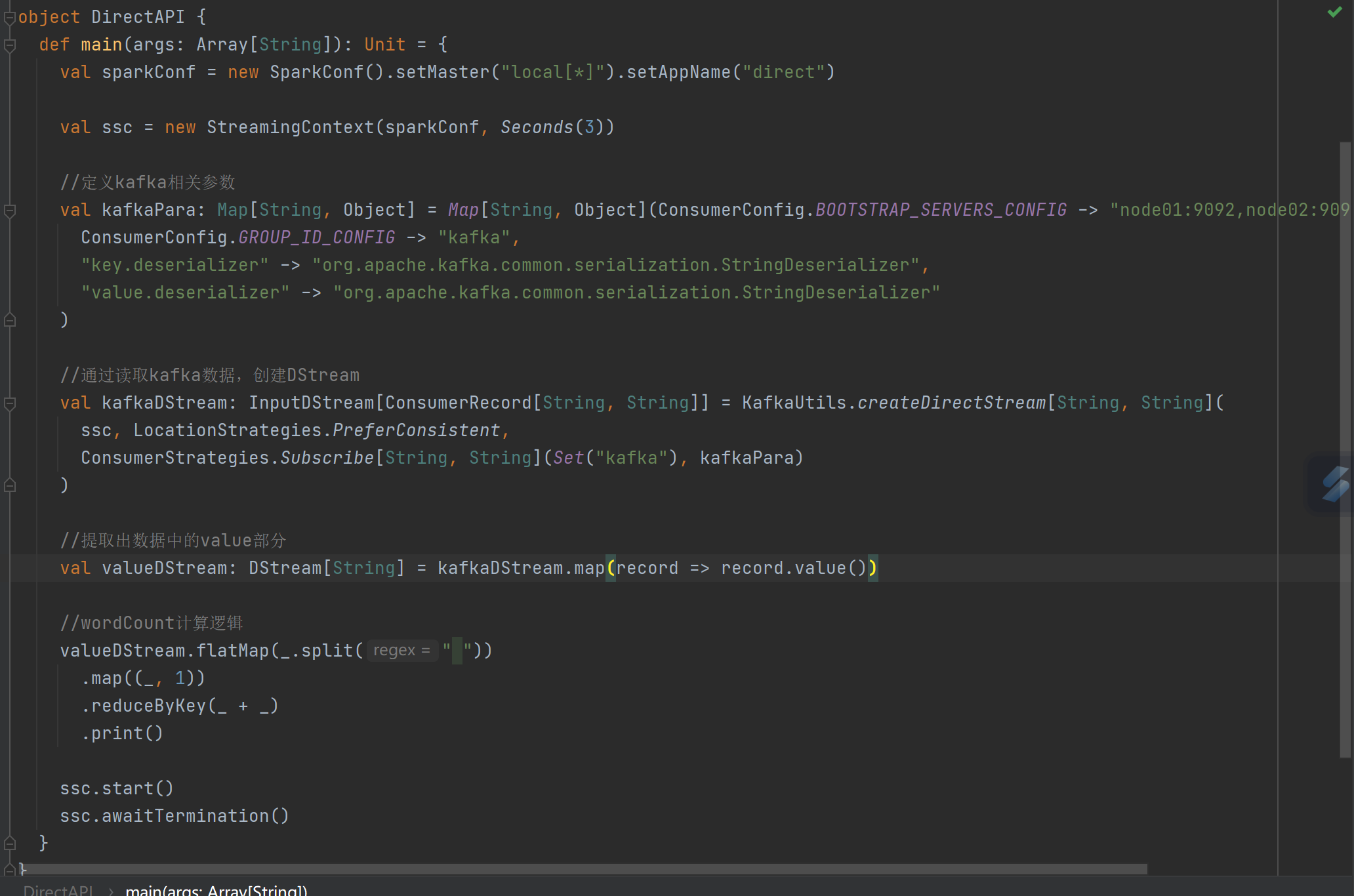
代码编写:创建SparkConf和StreamingContext,设置相关参数。定义Kafka参数,通过KafkaUtils.createDirectStream读取Kafka数据创建DStream,提取数据中的value部分,进行wordCount计算并打印结果,最后启动StreamingContext等待终止。
环境准备与操作流程:开启Kafka集群;使用 kafka - console - producer.sh 启动Kafka生产者并向指定topic发送数据;运行程序处理Kafka生产的数据;通过 kafka - consumer - groups.sh 查看消费进度,可了解数据消费情况。