想象一下,你的手机里住着一个隐形助理:你说"把亮度调到50%",它自动操作;你说"下载最新游戏",它一键完成。这就是GUI智能体 ------一种能"看懂"屏幕并操作的AI。
论文:A Survey on (M)LLM-Based GUI Agents
早期的自动化脚本像"固定剧本",只能按预设步骤运行,一旦界面变化就罢工。而今天的GUI智能体,结合了大语言模型(如GPT)和多模态模型(如图像识别),不仅能理解自然语言指令,还能像人类一样观察屏幕、规划操作步骤,甚至从错误中学习。
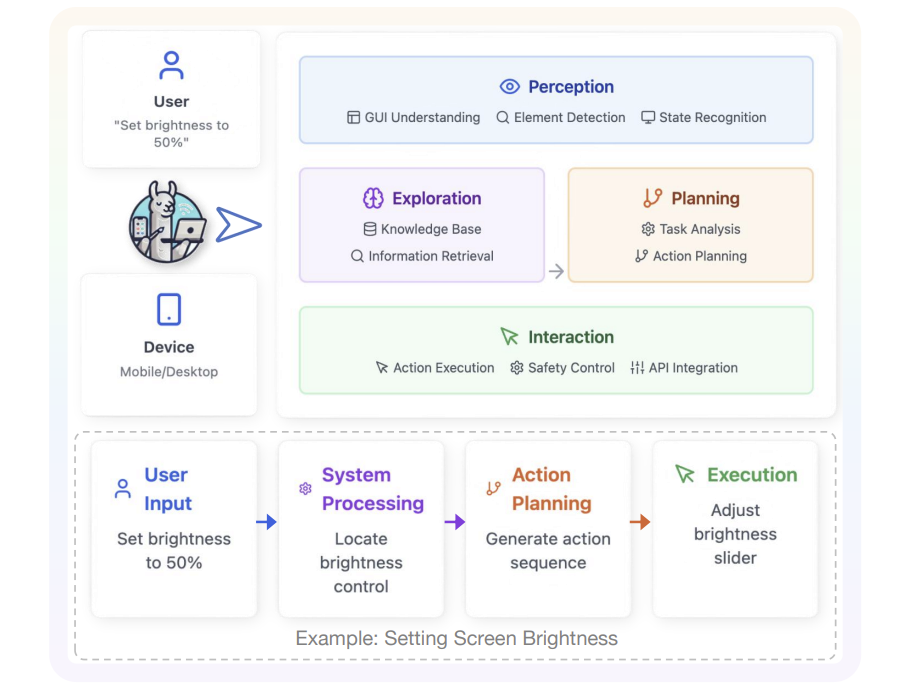
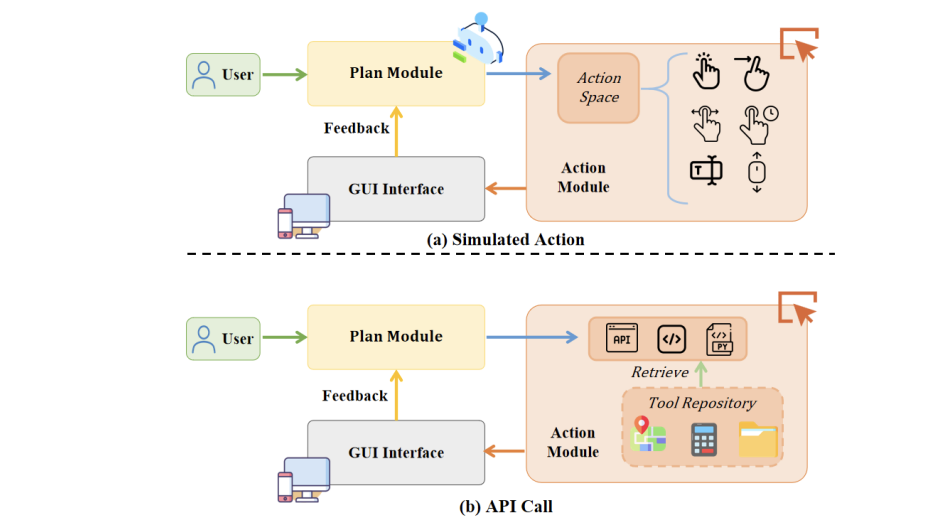
四大核心模块:AI如何看懂屏幕并操作?
① 感知系统:AI的「眼睛」
GUI智能体的第一步是"看懂界面"。传统方法依赖解析网页代码(如HTML),但现代AI直接分析屏幕截图,结合OCR文字识别和图标检测,甚至能理解动态弹窗。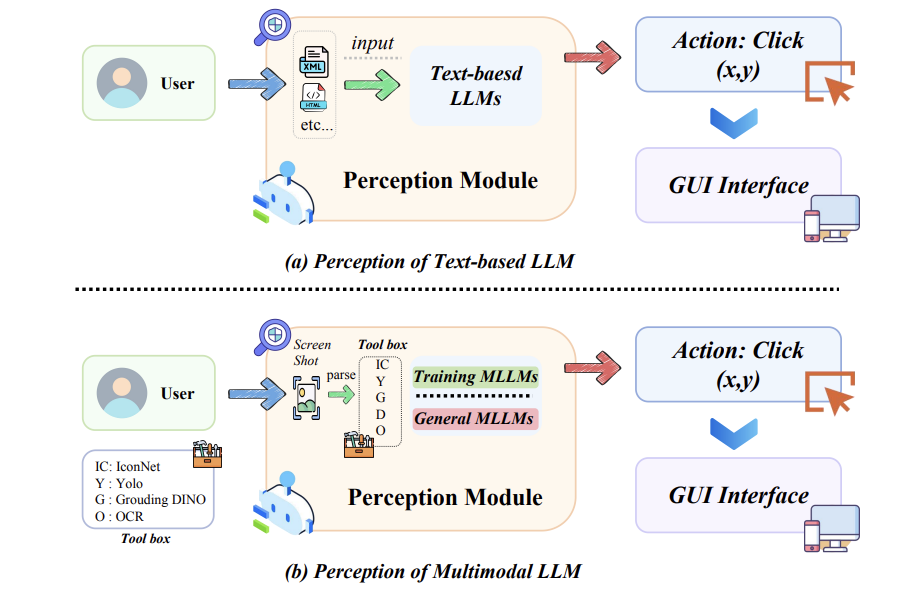 难点:高分辨率下的小图标定位(比如手机设置里的"深色模式"开关),AI容易"看花眼"。
难点:高分辨率下的小图标定位(比如手机设置里的"深色模式"开关),AI容易"看花眼"。
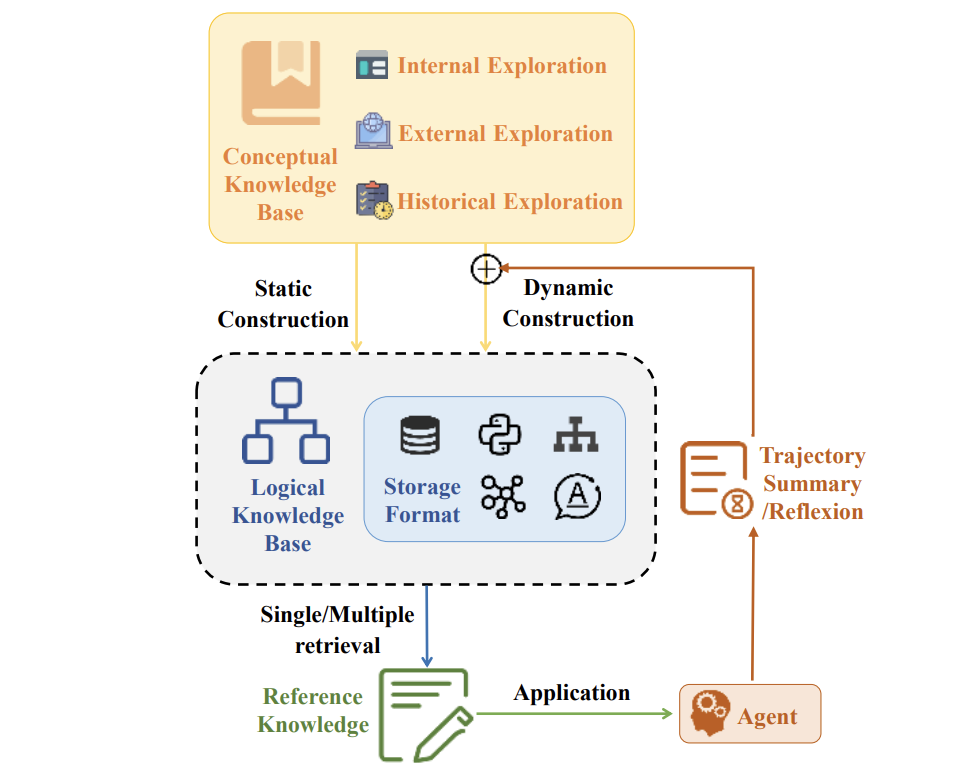
② 知识探索:AI的「经验库」
AI通过三种方式积累知识:
-
内部探索:像新手一样乱点,记录哪些按钮有用。
-
历史经验:记住成功操作路径,下次直接调用。
-
外部搜索:遇到陌生任务时,自动上网查攻略。
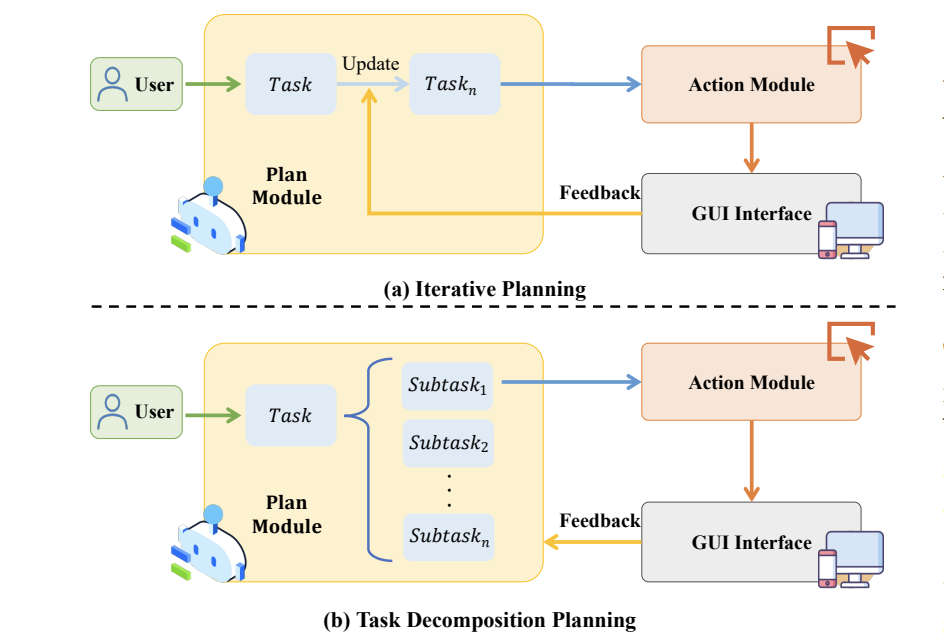
③ 规划框架:分步骤拆解任务
比如用户说"把照片导入PPT并加动画",AI会分解为:
1.打开相册选图 → 2.打开PPT粘贴 → 3.选择动画效果。
过程中若出错(比如找不到粘贴按钮),AI会尝试其他路径。
④ 交互执行:安全第一
AI操作必须"稳如老手":避免误点付费按钮、绕过弹窗广告。部分系统甚至需要用户二次确认敏感操作(如删除文件)。
实战应用:手机、电脑、网页、游戏全征服
手机场景
-
AppAgent:自动调节系统设置,甚至学习手动操作技巧。
-
Mobile-Agent:装APP、更新、卸载一条龙,还能处理中文界面。

电脑场景
-
OS-Copilot:写代码控制PPT生成,堪比"办公室秘书"。
-
UFO:专攻Windows系统,连右键菜单都能精准操作。
游戏场景
-
VOYAGER:在《我的世界》里自动挖矿、盖房子,技能库越用越强。
-
Cradle:结合视觉模型玩动作游戏,连BOSS弱点都能分析。
所以说,AI离「真·智能」还有多远?
一些当前痛点
-
定位不准:比如手机截图压缩后,AI可能把"返回键"看成"菜单键"。
-
应变力弱:遇到验证码弹窗或网络中断,AI容易"卡死"。
-
数据隐私:若AI能操作银行APP,如何防止被黑客利用?
未来方向(发论文方向!)
-
强化学习:让AI通过"试错奖励"自我进化(类似AlphaGo)。
-
多模态升级:结合语音指令、手势操作,更像真人。
-
标准化测试:建立跨平台任务库,公平比拼各家AI能力。
备注:**昵称-学校/公司-方向/**会议(eg.ACL)****,进入技术/投稿群

id:DLNLPer,记得备注呦