目录
[1 Hive查询执行架构全景](#1 Hive查询执行架构全景)
[2 SELECT基础查询详解](#2 SELECT基础查询详解)
[2.1 基本查询结构](#2.1 基本查询结构)
[2.2 条件查询流程图](#2.2 条件查询流程图)
[3 聚合函数与GROUP BY实战](#3 聚合函数与GROUP BY实战)
[3.1 聚合执行模型](#3.1 聚合执行模型)
[3.2 GROUP BY数据流](#3.2 GROUP BY数据流)
[4 排序操作深度解析](#4 排序操作深度解析)
[4.1 ORDER BY执行流程](#4.1 ORDER BY执行流程)
[4.2 排序算法对比](#4.2 排序算法对比)
[5 高级技巧与注意事项](#5 高级技巧与注意事项)
[5.1 嵌套查询与CTE](#5.1 嵌套查询与CTE)
[5.2 常见错误排查](#5.2 常见错误排查)
[6 总结](#6 总结)
1 Hive查询执行架构全景

流程说明:
- 解析阶段:将SQL转换为抽象语法树(AST)
- 编译阶段:生成逻辑执行计划
- 优化阶段:应用谓词下推等优化规则
- 执行阶段:转换为物理执行计划并运行
2 SELECT基础查询详解
2.1 基本查询结构
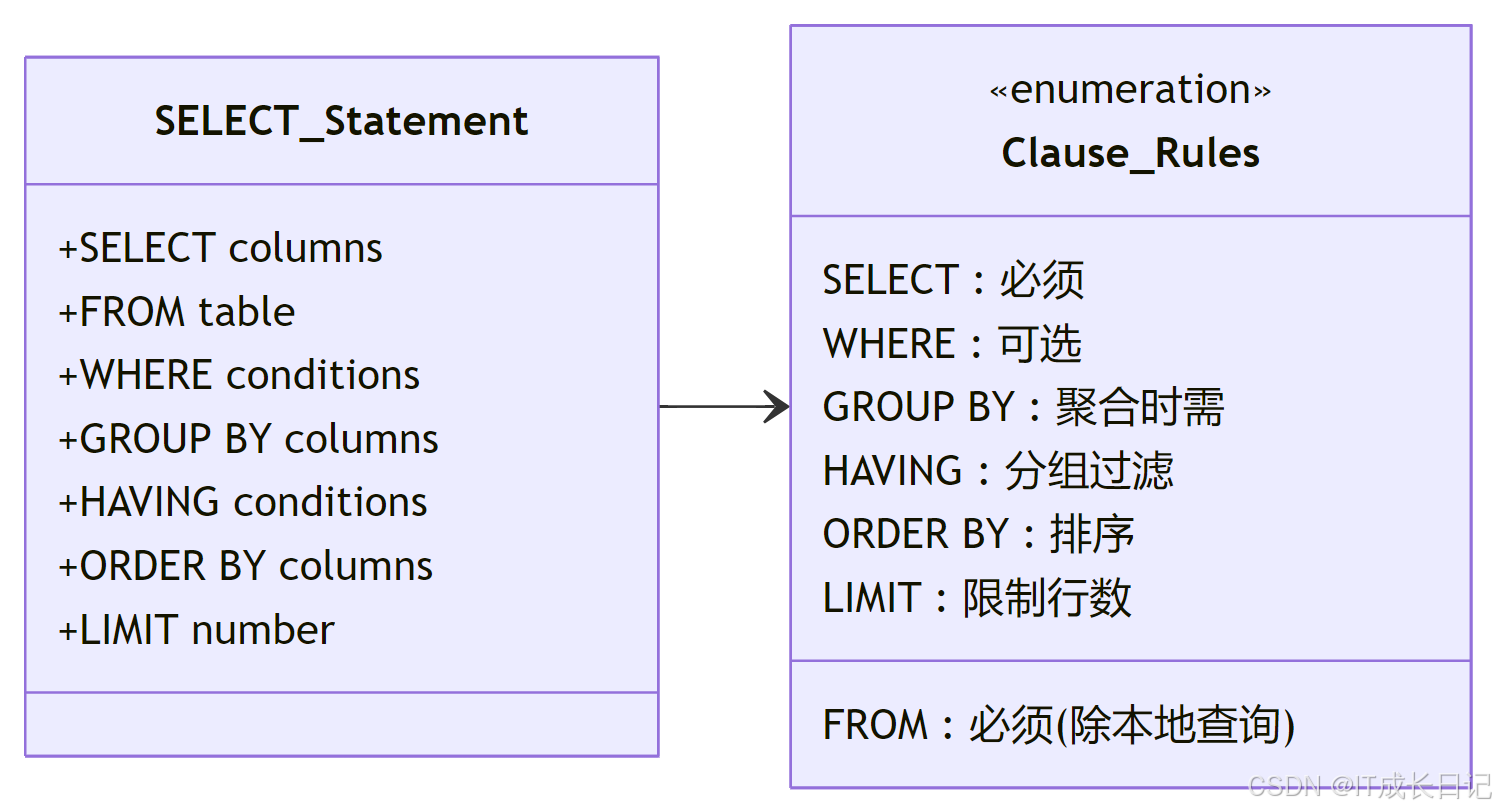
-
基础查询示例
-- 基本结构
SELECT [ALL|DISTINCT] column1, column2...
FROM table_name
[WHERE condition]
[GROUP BY columns]
[HAVING condition]
[ORDER BY columns [ASC|DESC]]
[LIMIT n];-- 实际示例
SELECT employee_id, name, salary
FROM employees
WHERE department = 'IT'
ORDER BY salary DESC
LIMIT 10;
2.2 条件查询流程图

- WHERE条件优化
- 优先使用分区字段过滤
-
避免在WHERE中使用函数
-- 不推荐
SELECT * FROM logs WHERE SUBSTRING(dt, 1, 6) = '202504';
-- 推荐
SELECT * FROM logs WHERE dt LIKE '202504%';
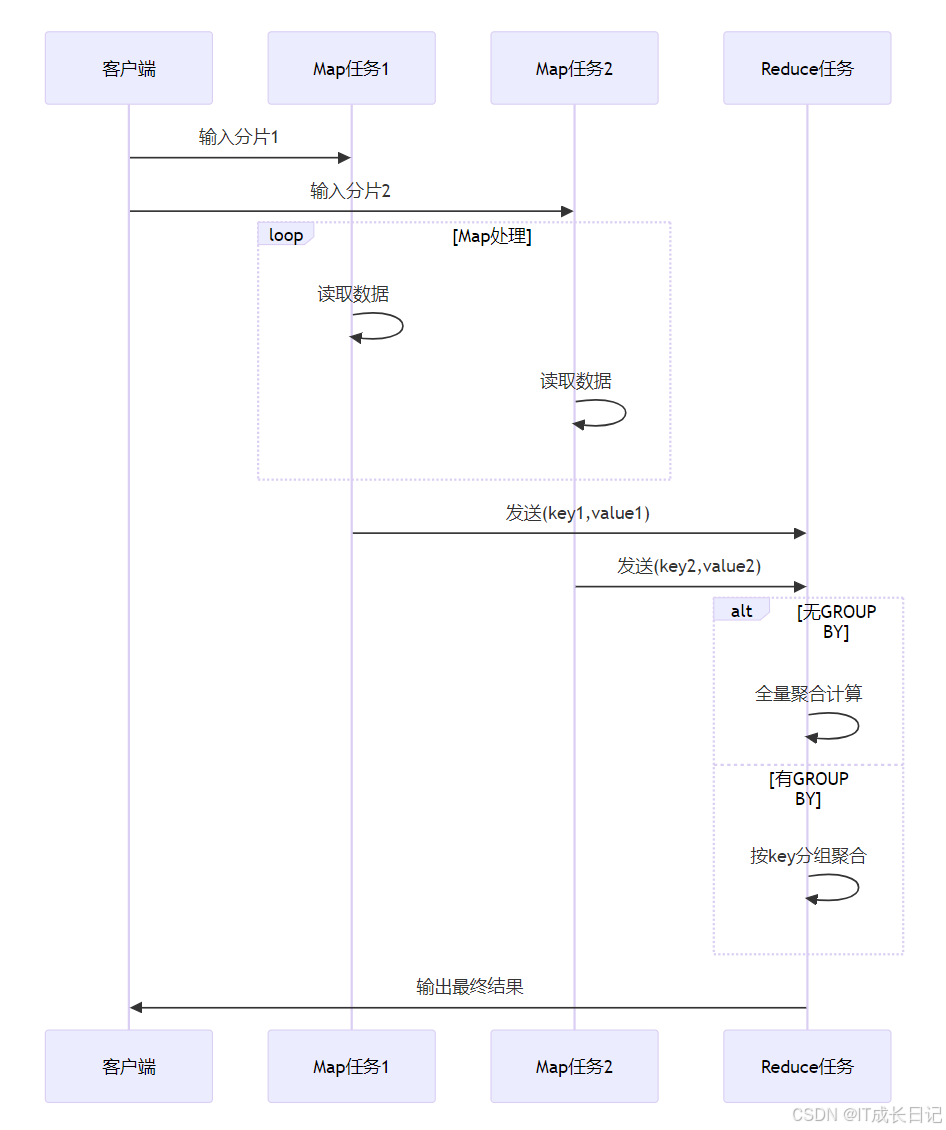
3 聚合函数与GROUP BY实战
3.1 聚合执行模型
- 常用聚合函数
|--------|--------|-------------------------|
| 函数 | 说明 | 示例 |
| COUNT | 计数 | COUNT(DISTINCT user_id) |
| SUM | 求和 | SUM(revenue) |
| AVG | 平均值 | AVG(score) |
| MAX | 最大值 | MAX(temperature) |
| MIN | 最小值 | MIN(price) |
3.2 GROUP BY数据流

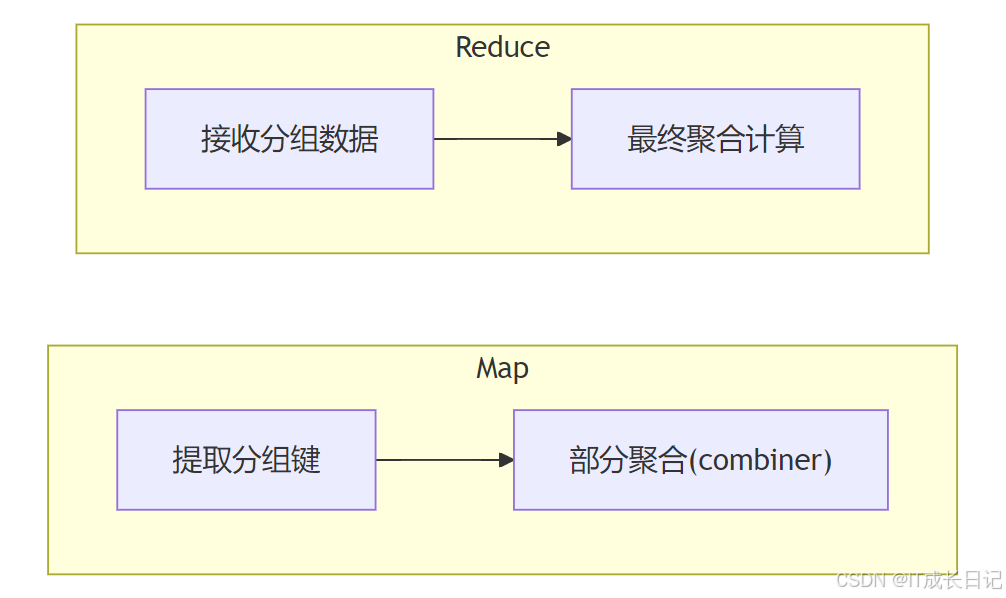
-
GROUP BY示例
-- 基础分组
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department;-- 多列分组
SELECT year, month, SUM(sales)
FROM sales_data
GROUP BY year, month;-- 配合HAVING过滤
SELECT product_id, AVG(rating) as avg_rating
FROM product_reviews
GROUP BY product_id
HAVING AVG(rating) > 4.0;
4 排序操作深度解析
4.1 ORDER BY执行流程

-
排序优化技巧
-
使用LIMIT减少排序数据量
-- 只排序前100条
SELECT * FROM users ORDER BY reg_date DESC LIMIT 100; -
分区表排序时先过滤
SELECT * FROM logs
WHERE dt='202504'
ORDER BY click_count DESC;
4.2 排序算法对比
-
排序类型示例
-- 全局排序(单Reducer)
SELECT * FROM employees ORDER BY salary DESC;-- 分区间排序(多Reducer)
SELECT * FROM employees
DISTRIBUTE BY department
SORT BY salary DESC;-- 局部排序(单个Reducer内)
SELECT * FROM employees SORT BY salary DESC;-- 分桶排序(等同于DISTRIBUTE+SORT)
SELECT * FROM employees CLUSTER BY department;
5 高级技巧与注意事项
5.1 嵌套查询与CTE
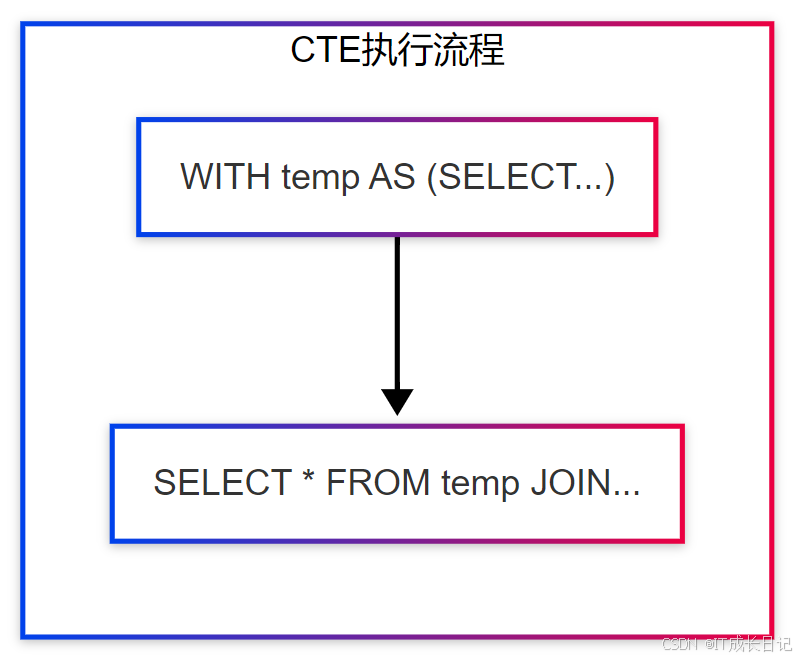
-
CTE示例
WITH high_value_users AS (
SELECT user_id
FROM users
WHERE total_spend > 1000
),
active_users AS (
SELECT DISTINCT user_id
FROM user_actions
WHERE dt > '20230101'
)
SELECT a.user_id, b.order_count
FROM high_value_users a
JOIN (
SELECT user_id, COUNT(1) as order_count
FROM orders
GROUP BY user_id
) b ON a.user_id = b.user_id;
5.2 常见错误排查
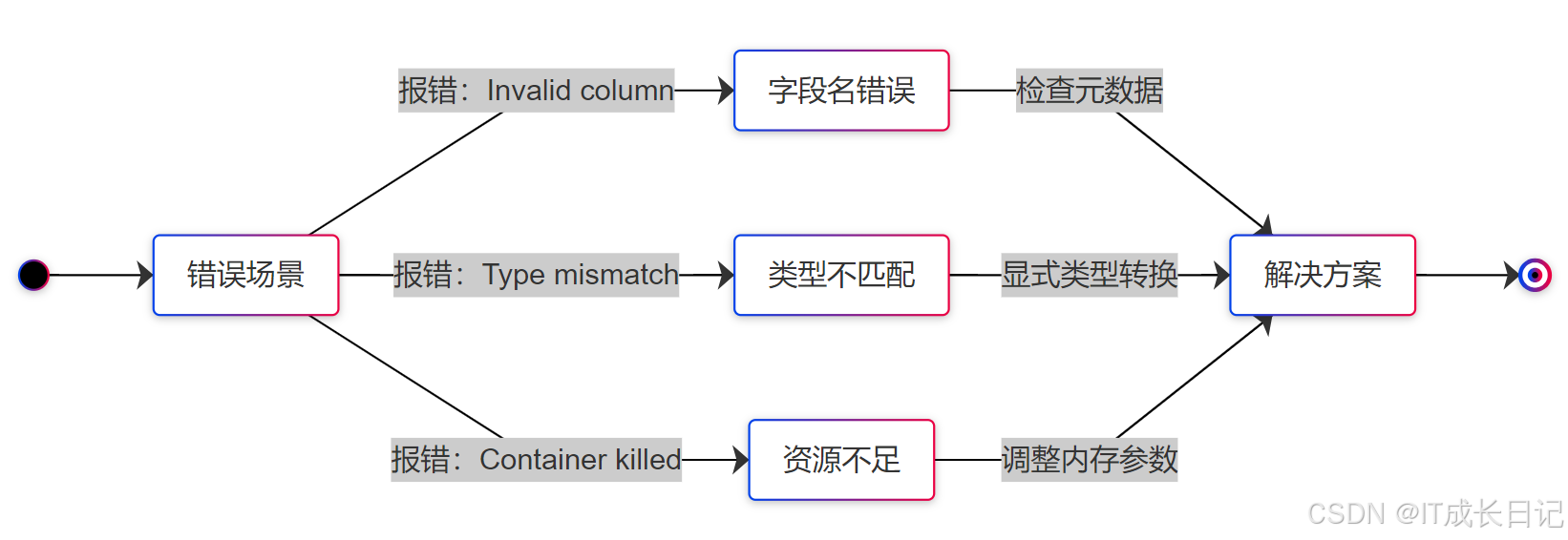
-
错误处理示例
-- 类型转换示例
SELECT CAST(price AS DECIMAL(10,2))
FROM products;-- 内存调整示例
SET mapreduce.map.memory.mb=2048;
SET mapreduce.reduce.memory.mb=4096;
6 总结
通过本指南,我们了解了Hive DQL的核心要点,实际应用中建议:
- 结合EXPLAIN分析执行计划
- 监控长时间运行查询
- 定期收集表统计信息
- 根据数据特点选择最优方案