- 第1章 对大型语言模型的介绍
- 第2章 分词和嵌入
- 第3章 解析大型语言模型的内部机制
- 第4章 文本分类
- 第5章 文本聚类与主题建模
- 第6章 提示工程
- 第7章 高级文本生成技术与工具
- 第8章 语义搜索与检索增强生成
- 第9章 多模态大语言模型
- 第10章 构建文本嵌入模型
- 第11章 面向分类任务的表示模型微调
在本章中,我们将以一个预训练文本生成模型为例,详细讲解微调(fine-tuning)的完整流程。微调是生成高质量模型的关键步骤,也是我们工具包中用于将模型适配到特定预期行为的重要工具。通过微调,我们可以让模型适配特定的数据集或领域。
本章将引导您了解两种最常见的文本生成模型微调方法:监督式微调(supervised fine-tuning)和偏好微调(preference tuning)。我们将深入探索微调预训练文本生成模型的变革潜力,帮助您将其转化为更高效的应用工具。
LLM训练的三个步骤:预训练、监督微调与偏好调整
创建高质量大语言模型(LLM)通常需要以下三个关键步骤:
1. 语言建模
创建高质量大语言模型的第一步是在一个或多个大规模文本数据集上对其进行预训练(图12-1)。训练过程中,模型会尝试预测下一个词元(token),以准确学习文本中的语言和语义表征。正如第3章和第11章所述,这一过程被称为语言建模,属于一种自监督学习方法。
此阶段会生成一个基础模型(base model),也常被称为预训练模型或基础模型。基础模型是训练过程的核心产物,但由于其直接使用门槛较高,终端用户往往难以直接应用。因此,接下来的第二步显得尤为重要。

图12-1. 在语言建模过程中,LLM 旨在根据输入预测下一个词元。这是一个无监督学习过程
2.微调1(监督式微调)
若大型语言模型能良好响应指令并尝试遵循指令,则会更具实用性。例如当人类要求模型撰写文章时,期望模型直接生成文章内容,而非像基础模型可能做的那样列出其他指令。
通过监督式微调(SFT),我们可以使基础模型适配指令遵循任务。在此微调过程中,基础模型的参数会被更新以更贴合目标任务(如指令遵循)。与预训练模型类似,它仍通过下一个词预测进行训练,但区别在于其预测是基于用户输入进行的(见图12-2)。

图12-2. 在监督式微调过程中,大语言模型(LLM)会基于附加了标签的输入来预测下一个词元。从某种意义上讲,这里的标签就是用户的输入内容
监督微调(SFT)也可用于其他任务(如分类),但其核心价值在于将基础生成模型转化为具备指令遵循能力(或对话能力)的生成模型。
3.微调 2(偏好调整)
最后一步进一步提升模型质量,使其行为更贴近人工智能安全预期或人类偏好。这一过程称为偏好调整。作为微调的一种形式,它通过训练数据定义的偏好方向对齐模型输出------正如其名称所示,该技术能将模型输出提炼至符合人类偏好的状态。与监督微调(SFT)类似,偏好调整不仅能改进基础模型,还能在训练过程中系统性地凝练输出偏好。这三个步骤如图12-3所示,完整展现了从无训练基础的架构出发,最终获得偏好对齐大语言模型的全过程。

图12-3. 构建高质量大语言模型的三个步骤
在本章中,我们使用一个在大规模数据集上预训练的基础模型,并探索如何通过两种微调策略对其进行微调优化。对于每种方法,我们都将首先阐述其理论基础,然后再将其应用于实践场景。
监督微调(SFT)
在大规模数据集上预训练模型的目的是使其能够理解和生成语言及其含义。在此过程中,模型会学习如何补全输入短语,如图12-4所示。
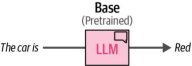
图12-4. 基础或预训练语言模型(LLM)通过训练具备预测后续词语的能力
这个例子还说明了该模型并未经过遵循指令的训练,而是会尝试补全问题而非直接回答(图12-5)。
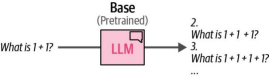
图12-5. 基础大语言模型(LLM)不会遵循指令,而是会尝试逐词预测。它甚至可能生成全新的问题
我们可以通过微调(fine-tuning)这一基础模型,将其适配到遵循指令等特定应用场景。
全 量 微调
最常见的微调过程是全量微调。与预训练大语言模型(LLM)类似,该过程需要更新模型的所有参数以适配目标监督式微调(Supervised Fine-Tuning,SFT)任务。主要区别在于我们现在使用更小但带标签的数据集,而预训练过程是在不带任何标签的大型数据集上完成的(图12-6)。
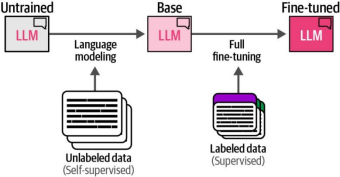
图12-6. 与语言建模(预训练)相比,全量微调使用规模更小但标注过的数据集。
您可以使用任何标注数据进行全量微调,这也使其成为学习领域特定表征的有效方法。为了让大语言模型遵循指令,我们需要构建问答数据------如图12-7所示,这类数据由用户提出的查询及其对应的答案组成。

图12-7. 包含用户指令及其对应答案的指令数据。这些指令可能包含多种不同的任务
在完全微调过程中,模型会接收输入(指令),并对输出(响应)应用下一个token预测。这样,模型将遵循指令,而不是生成新问题。
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)
更新模型的全部参数虽然具有极大的性能提升潜力,但也存在诸多缺点。这不仅会导致高昂的训练成本,还存在训练耗时较长、需要大量存储资源等问题。为解决上述问题,当前研究重点关注参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)替代方案,这类方法能够在保持预训练模型特性的同时,专注于以更高的计算效率进行模型微调.
适配器
适配器是基于参数高效微调(PEFT)技术的核心组件之一。该方法提出在Transformer模型中插入一组额外的模块化组件,通过微调这些组件即可提升模型在特定任务上的性能,而无需对全部模型权重进行微调。这种方式能显著节省时间和计算资源。
适配器的概念源自论文《Parameter-efficient transfer learning for NLP》。该研究表明,针对特定任务仅微调BERT模型3.6%的参数,其性能即可与全参数微调相当1。在GLUE基准测试中,作者证明其性能与全微调结果的差距小于0.4%。论文提出的适配器架构将适配器模块嵌入到单个Transformer块中,具体位置在注意力层(attention layer)和前馈神经网络(feedforward neural network)之后,如图12-8所示。
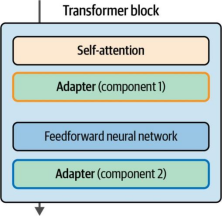
图12-8. 适配器在网络中的特定位置添加少量权重,这些权重可高效微调,同时保持模型大部分权重冻结
1 Neil Houlsby et al. "Parameter--efficient transfer learning for NLP." Interna tional Conference on Machine Learning . PMLR, 2019.
然而,仅仅修改一个Transformer块是不够的,因此这些组件被应用到了模型中的每一个块中,如图12-9所示。
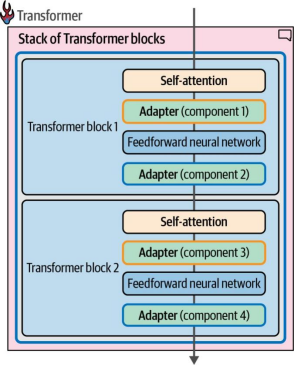
图12-9. 适配器组件跨越模型中的各个Transformer模块
如此一来,我们可以像图12-10展示的那样,将模型中所有适配器组件视为一个整体------该组件集合覆盖了模型的所有模块。例如,适配器1可以专门处理医疗文本分类任务,而适配器2则可专精于命名实体识别(NER)。您可以从以下链接下载这些专用适配器:https://oreil.ly/XraXg。
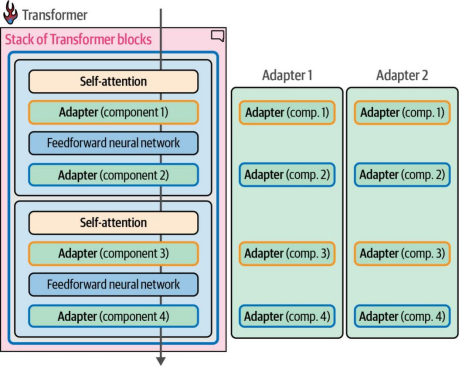
图12-10. 专用于特定任务的适配器可以替换到相同架构中(前提是它们共享相同的原始模型架构和权重)
论文《AdapterHub: A framework for adapting transformers》提出了Adapter Hub作为适配器共享的中央存储库2。早期的适配器更多聚焦于BERT架构,而最近这一概念已被应用于文本生成类Transformer模型,如论文《LLaMA-Adapter: Efficient fine-tuning of language models with zero-init attention》所示3。
低秩自适应(LoRA)
作为适配器的一种替代方案,低秩自适应(Low-Rank Adaptation,LoRA)在撰写本文时已成为参数高效微调(PEFT)领域广泛应用且有效的技术。如图12-11所示,LoRA(与适配器类似)仅需要更新少量参数。该技术通过创建基础模型的一个小型子网络进行微调,而非直接向模型中添加新层4。
2 Jonas Pfeiffer et al. "AdapterHub: A framework for adapting transformers." arXiv preprint arXiv:2007.07779 (2020).
3 Renrui Zhang et al. "Llama-adapter: Efficient fine-tuning of language models with zero-init attention." arXiv preprint arXiv:2303.16199 (2023)
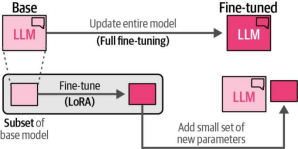
图12-11. LoRA仅需微调一小部分参数,这些参数可与基础大语言模型(LLM)分开独立保存
与适配器类似,这种参数子集允许我们进行更快速的微调,因为只需更新基础模型的一小部分参数。我们通过用较小的矩阵近似原始大语言模型(Large Language Model, LLM)伴随的大型矩阵来创建这个参数子集。然后可以使用这些较小的矩阵作为替代进行微调,而非直接微调原始的大尺寸矩阵。以图12-12所示的10×10矩阵为例说明这种机制。

图12-12. 大型语言模型(LLMs)的一个主要瓶颈是其庞大的权重矩阵。单个此类矩阵可能包含1.5亿个参数,而每个Transformer模块都会拥有自己的这些矩阵变体
4 Edward J. Hu et al. "LoR: Low-Rank Adaptation of large language models." arXiv preprint arXiv:2106.09685(2021).
我们可以将两个较小的矩阵相乘来重构一个10×10的矩阵。这显著提高了效率,因为原本需要使用100个权重参数(10×10),而现在仅需20个权重参数(10+10),如图12-13所示。
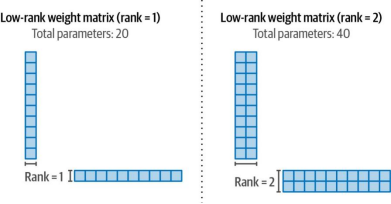
图12-13. 将大型权重矩阵分解为两个较小矩阵后,可得到该矩阵的压缩低秩版本,从而能更高效地进行微调
在训练过程中,我们只需更新这些较小的矩阵,而非完整的权重变化量。随后,如图12-14所示,这些更新后的小矩阵会与冻结的完整权重进行组合。
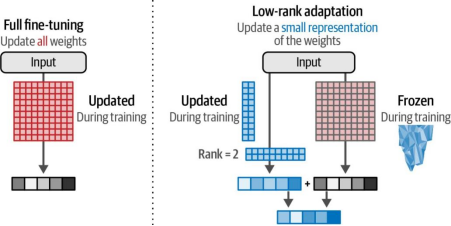
图12-14与全量微调相比,LoRA(低秩自适应)的目标是在训练过程中仅更新原始权重中的低秩矩阵表示部分
但你或许会怀疑性能会因此下降。你的直觉是对的。但这种权衡在什么情况下才有意义呢?
诸如《内在维度解释了语言模型微调的有效性》等论文表明,语言模型具有"非常低的内在维度"5。这意味着我们可以找到较小的秩来近似LLM(大型语言模型)的庞大矩阵。以GPT-3这种1750亿参数的模型为例,其每个Transformer模块内部都包含12,288×12,288的权重矩阵。这相当于每个模块有1.5亿个参数。如果我们能成功将这个矩阵压缩到秩8,那么每个模块只需要两个12,288×2的矩阵,参数量骤降至19.7万个。正如LoRA论文所阐述的,这在速度、存储和计算方面都能实现重大优化。
这种紧凑表征的优势在于可以选择性地微调基础模型的特定部分。例如,我们完全可以仅对每个Transformer层中的查询(Query)和值(Value)权重矩阵进行微调。
为了(更)高效地训练模型进行压缩
通过降低原始模型权重的内存需求后再将其投影到更小的矩阵中,我们可以进一步提高LoRA的效率。大型语言模型(LLM)的权重是以特定精度表示的数值,这种精度可以用位数(如float64或float32)来描述。如图12-15所示,若我们减少表示数值所需的位数,结果的精度会降低。然而,位数的减少也意味着模型内存需求的下降。
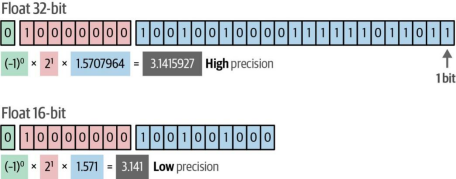
图12-15. 尝试用32位和16位浮点数表示π。注意当比特位数减半时精度会下降
5 Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. "Intrinsic dimensionality explains the effectiveness of language model fine--tuning." arXiv pre print arXiv:2012.13255 (2020).
在量化过程中,我们的目标是在保持准确表示原始权重值的同时降低位数。然而,如图12-16所示,当直接将较高精度值映射到较低精度值时,可能会出现多个较高精度值最终被映射为相同较低精度值的情况。
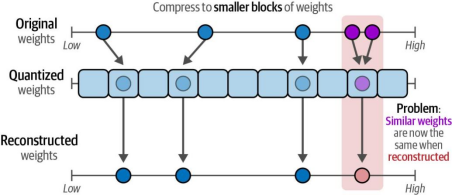
图12-16. 对彼此接近的权重进行量化会导致相同的重构权重,从而消除任何差异因素
相反,QLoRA(LoRA的量化版本)的作者们找到了一种方法,可以在不显著偏离原始权重的情况下,实现从较高比特数到较低比特数的转换(反之亦然)6。
他们采用分块量化技术,将高精度值的特定数据块映射到低精度值。这种方法并非直接进行高低精度转换,而是通过创建额外的数据块,使具有相似特征的权重能够被量化。如图12-17所示,这种技术最终生成的结果能够用较低精度实现精准表达。
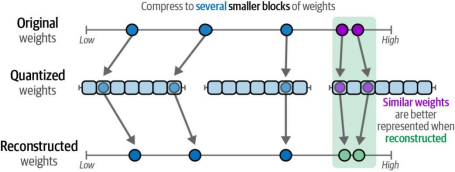
图12-17. 分块量化通过量化块能够以较低精度准确表示权重
神经网络的一个良好特性是其数值通常在-1到1之间呈正态分布。基于权重的相对密度(如图12-18所示),这一特性使我们能够将原始权重分箱至较低比特位。由于考虑了权重的相对频率,权重间的映射效率更高。同时这也减少了异常值问题。
6 Tim Dettmers et al. "QLoRA: Efficient finetuning of quantized LLMs." arXiv preprint arXiv:2305.1431 4 (2023).
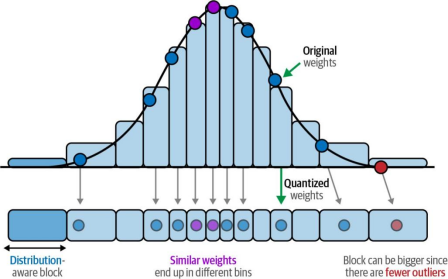
图12-18. 通过使用分布感知型模块,我们可以防止相邻数值被量化为相同的离散值。
结合分块量化技术,这种归一化方法能够通过低精度值实现对高精度值的精准表示,同时仅造成大语言模型(LLM)性能的轻微下降。因此,我们可以将模型从16位浮点表示大幅缩减为4位归一化浮点表示。4位表示方式显著降低了大语言模型在训练期间的内存需求。值得注意的是,大语言模型的量化通常也有助于推理过程,因为量化后的模型体积更小,从而减少了对显存(VRAM)的占用。
若需进一步优化,可采用更先进的方法(如双重量化和分页优化器),这些内容在前文讨论的QLoRA论文中有详细阐述。关于量化的完整可视化指南,建议参考此篇技术博客。
QLoRA指令调优
现在我们已经了解了QLoRA的工作原理,让我们将其付诸实践!在本节中,我们将使用QLoRA方法对完全开源的小型Llama模型------TinyLlama进行微调,使其能够遵循指令。可以将此模型视为基础模型或预训练模型,它虽然经过语言建模训练,但尚不具备遵循指令的能力。
模板指令数据
为了让LLM遵循指令,我们需要准备符合聊天模板的指令数据。该聊天模板(如图12-19所示)对LLM生成的内容和用户生成的内容进行了区分。
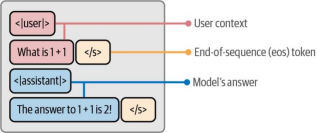
图12-19. 本章贯穿使用的聊天模板
我们选择这种聊天模板作为贯穿所有示例的格式,因为TinyLlama的聊天版本采用了相同格式。我们所使用的数据是UltraChat数据集的一个小子集,该数据集是原始UltraChat数据集的过滤版本,包含近20万组用户与大型语言模型之间的对话。我们创建了一个名为format_prompt的函数,以确保对话严格遵循此模板格式:
python
from transformers import AutoTokenizer
from datasets import load_dataset
# Load a tokenizer to use its chat template
template_tokenizer = AutoTokenizer.from_pretrained(
"TinyLlama/TinyLlama-1.1BChat-v1.0"
)
def format_prompt(example):
"""Format the prompt to using the <|user|> template TinyLLama is using"""
# Format answers
chat = example["messages"]
prompt = template_tokenizer.apply_chat_template(chat, tokenize=False)
return {"text": prompt}
# Load and format the data using the template TinyLLama is using
dataset = (
load_dataset("HuggingFaceH4/ultrachat_200k", split="test_sft").shuffle(seed=42).select(range(3_000))
)
dataset = dataset.map(format_prompt)我们选择了3,000份文档的子集以缩短训练时间,但您可以增加这个数值以获得更准确的结果。通过使用"text"列,我们可以查看这些格式化提示:
# Example of formatted prompt
print(dataset"text"2576)
<|user| >
Given the text: Knock, knock. Who's there? Hike.
Can you continue the joke based on the given text material "Knock, knock.
Who's there? Hike"?</s>
<|assistant| >
Sure! Knock, knock. Who's there? Hike. Hike who? Hike up your pants, it's cold
outside!</s>
<|user| >
Can you tell me another knock-knock joke based on the same text material
"Knock, knock. Who's there? Hike"?</s>
<|assistant| >
Of course! Knock, knock. Who's there? Hike. Hike who? Hike your way over here
and let's go for a walk!</s>
7 Ning Ding et al. "Enhancing chat language models by scaling high-quality instructional conversations." arXiv preprint arXiv:2305.14233 (2023).
模型量化
现在我们已经准备好数据,可以开始加载模型。这就是我们在QLoRA中应用Q(即量化)的环节。我们将使用bitsandbytes库将预训练模型压缩为4位表示。
在BitsAndBytesConfig配置中,您可以定义量化方案。我们遵循原始QLoRA论文采用的方法,通过以下配置加载模型:使用4位加载(load_in_4bit)、采用归一化浮点表示(bnb_4bit_quant_type),并启用双量化技术(bnb_4bit_use_double_quant)。
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T"
# 4-bit quantization configuration - Q in QLoRA
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Use 4-bit precision model loading
bnb_4bit_quant_type="nf4", # Quantization type
bnb_4bit_compute_dtype="float16", # Compute dtype
bnb_4bit_use_double_quant=True, # Apply nested quantization
)
# Load the model to train on the GPU
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
# Leave this out for regular SFT
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = "<PAD>"
tokenizer.padding_side = "left"这种量化方法可以在保留原始模型大部分权重精度的同时减小模型体积。加载模型时仅需约1 GB显存,而未经量化的原始模型则需要约4 GB显存。需要注意的是,在微调过程中需要更多显存,以避免加载模型所需的约1 GB显存出现瓶颈。
LoRA配置
接下来,我们需要使用peft库来定义LoRA配置,该配置包含了微调过程中涉及的超参数:
python
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
# Prepare LoRA Configuration
peft_config = LoraConfig(
lora_alpha=32, # LoRA Scaling
lora_dropout=0.1, # Dropout for LoRA Layers
r=64, # Rank
bias="none",
task_type="CAUSAL_LM",
# Layers to target
target_modules= ["k_proj", "gate_proj", "v_proj", "up_proj", "q_proj", "o_proj", "down_proj"]
)
# Prepare model for training
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config) 有几个参数值得提及:
R
这是压缩矩阵的秩(参见图12-13相关内容)。增大该值会增加压缩矩阵的尺寸,从而降低压缩率并提升表征能力。典型取值范围在4到64之间。
lora_alpha
控制添加到原始权重的变化量大小。本质上,它平衡了原始模型知识与新任务知识的关系。经验法则是选择r值两倍的数值。
target_modules
控制目标作用层。LoRA流程可以选择忽略特定层(如特定投影层),这样既能加快训练速度但可能降低性能,反之亦然。
对参数进行调整是一项值得尝试的实验,这有助于直观理解哪些值有效、哪些无效。在Sebastian Raschka的《Ahead of AI》通讯中,你可以找到关于LoRA微调的宝贵资源
此示例演示了一种高效的模型微调方法。如果您想改为进行完全微调,则可以在加载模型时移除quantization_config参数,并跳过peft_config的创建。通过移除这些配置,我们就从"基于QLoRA的指令调优"转变为"完全指令调优"。
训练配置
最后,我们需要像在第11章中那样配置训练参数:
python
from transformers import TrainingArguments
output_dir = "./results"
# Training arguments
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
learning_rate=2e-4,
lr_scheduler_type="cosine",
num_train_epochs=1,
logging_steps=10,
fp16=True,
gradient_checkpointing=True
)有几个参数值得注意:
num_train_epochs
训练的总轮数。较高的值往往会导致性能下降,因此我们通常建议将其保持在较低水平。
learning_rate
决定每次权重更新迭代时的步长。QLoRA作者发现,对于更大的模型(>33B参数),较高的学习率效果更好。
lr_scheduler_type
基于余弦的调度器,用于动态调整学习率。学习率会从零开始线性增加,直至达到设定值。此后,学习率将按照余弦函数值进行衰减。
Optim
原QLoRA论文中使用的分页优化器
优化这些参数是一项困难的任务,而且没有固定的指导方针可循。这需要通过实验来确定哪些方法对特定的数据集、模型规模和目标任务最为有效。
虽然本节主要介绍指令调优,但我们同样可以使用QLoRA对指令模型进行微调。例如,我们可以微调聊天模型以生成特定的SQL代码,或创建符合特定格式要求的JSON输出。只要拥有包含对应查询-响应条目的可用数据集,QLoRA就能有效引导现有聊天模型向特定应用场景进行适应性优化。
训练
现在我们已经准备好了所有的模型和参数,可以开始对模型进行微调了。我们加载SFTTrainer后,直接运行trainer.train()即可:
python
from trl import SFTTrainer
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
max_seq_length=512,
# Leave this out for regular SFT
peft_config=peft_config,
)
# Train model
trainer.train()
# Save QLoRA weights
trainer.model.save_pretrained("TinyLlama-1.1B-qlora")在训练过程中,loss将根据logging_steps参数每隔10步打印一次。如果您使用的是Google Colab提供的免费GPU(在撰写本文时为Tesla T4),训练可能需要长达一小时的时间。正好可以休息一下!
合并权重
在完成QLoRA权重的训练后,我们需要将其与原始权重进行合并才能实际使用。此时需要以16位精度重新加载模型(而非量化后的4位版本)来完成权重合并操作。虽然分词器在训练过程中未进行更新,我们仍将其与模型保存在同一文件夹下,以便于后续访问:
python
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
"TinyLlama-1.1B-qlora",
low_cpu_mem_usage=True,
device_map="auto",
)
# Merge LoRA and base model
merged_model = model.merge_and_unload()在将适配器与基础模型合并后,我们可以使用之前定义的提示模板来应用它。
python
from transformers import pipeline
# Use our predefined prompt template
prompt = """<|user| >
Tell me something about Large Language Models.</s>
<|assistant| >
"""
# Run our instruction-tuned model
pipe = pipeline(task="text-generation", model=merged_model, tokenizer=tokenizer)
print(pipe(prompt)[0]["generated_text"])Large Language Models (LLMs) are artificial intelligence (AI) models that
learn language and understand what it means to say things in a particular
language. They are trained on huge amounts of text...
综合输出结果表明,该模型目前能严格遵循我们的指令,而这是基础模型无法实现的。
评估生成模型
评估生成模型面临重大挑战。生成模型的应用场景极为广泛,这使得依赖单一指标进行评判成为难题。与专用模型不同,生成模型解决数学问题的能力并不能保证其解决编程问题的成功。同时,在需要保持一致性的生产环境中,对这些模型进行评估尤为重要。鉴于生成模型具有概率本质,其输出结果未必稳定一致,因此需要建立稳健的评估方法。
在本节中,我们将探讨一些常见的评估方法,但需要强调的是,目前尚无黄金标准。没有一种指标能完美适用于所有应用场景。
词级指标
比较生成模型的常用指标类别之一是词级评估。这些经典技术通过词元(组)级别对比参考数据集与生成内容。常见的词级指标包括困惑度8、ROUGE9、BLEU10和BERTScore11。
其中值得特别关注的是困惑度(Perplexity),它衡量语言模型对文本的预测能力。给定输入文本时,模型会预测下一个词元的概率。困惑度假设:模型对下一个词元赋予的概率越高,其表现越好。换言之,当面对逻辑清晰的文本时,模型应处于低困惑度状态(即不应感到"困惑")。
如图12-20所示,当输入为"When a measure becomes a"时,模型会被要求评估"target"作为下一个词元的概率高低。

图12-20 下一词预测是许多大型语言模型(LLMs)的核心特征
8 Fred Jelinek et al. "Perplexity---a measure of the difficulty of speech recognition tasks." The Journal of the Acoustical Society of America 62.S1 (1977): S63.
9 Chin-Yew Lin. "ROUGE: A package for automatic evaluation of summaries." Text Summarization Branches Out , 74--81. 2004.
10 Kishore Papineni, et al. "Bleu: a method for automatic evaluation of machine translation." Proceedings of the 40th Annual Meeting of the Association for Computational Linguist ics . 2002.
11 Tianyi Zhang et al. "BERTscore: Evaluating text generation with BERT." arXiv preprint arXiv:1904.09675 (2019).
虽然困惑度和其他词级指标是衡量模型置信度的有效工具,但它们并非完美标准。这些指标无法全面反映生成文本的一致性、流畅性、创造性,甚至正确性。
基准测试
在语言生成和理解任务中评估生成模型的常用方法是在知名公开基准测试上进行,例如MMLU¹²、GLUE¹³、TruthfulQA¹⁴、GSM8k¹⁵和HellaSwag¹⁶。这些基准测试不仅提供了基础语言理解能力的信息,还涉及复杂数学问题等分析性回答能力的评估。
除了自然语言任务外,一些专注于编程等特定领域的模型通常会在不同的基准测试中进行评估,例如包含挑战性编程任务供模型解决的人类评估基准(HumanEval)¹⁷。表12-1概述了生成模型常用的公共基准测试。
|-------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------|
| Benchmark | Description | Resources |
| MMLU | The Massive Multitask Language Understanding (MMLU) benchmark tests the model on 57 different tasks, including classification, question answering, and sentiment analysis. | https://oreil.ly/ nrG_g |
| GLUE | The General Language Understanding Evaluation (GLUE) benchmark consists of language understanding tasks covering a wide degree of difficulty. | https://oreil.ly/ LV_fb |
| TruthfulQA | TruthfulQA measures the truthfulness of a model's generated text. | https://oreil.ly/ i2Brj |
| GSM8k | The GSM8k dataset contains grade-school math word problems. It is linguistically diverse and created by human problem writers. | https://oreil.ly/oOBXY |
| HellaSwag | HellaSwag is a challenge dataset for evaluating common-sense inference. It consists of multiple-choice questions that the model needs to answer. It can select one of four answer choices for each question. | https://oreil.ly/ aDvBP |
| HumanEval | The HumanEval benchmark is used for evaluating generated code based on 164 programming problems. | https://oreil.ly/ dlJIX |
表12-1. 生成模型的常用公共基准
基准测试是了解模型在多种任务上表现如何的重要方法。然而,公开基准测试也存在一些缺点:首先,模型可能会针对这些基准进行过度优化以生成最佳结果;其次,这些基准仍然覆盖面较广,可能无法涵盖某些特定使用场景;最后,部分基准测试需要高性能GPU支持且计算耗时较长(通常需要数小时),这会加大迭代优化的难度。
12 Dan Hendrycks et al. "Measuring massive multitask language understanding." arXiv prepri nt arXiv:2009.0330 0 (2020).
13 Alex Wang et al. "GLUE: A multi-task benchmark and analysis platform for natural language understanding." arXiv preprint arXiv:1804.07461 (2018).
14 Stephanie Lin, Jacob Hilton, and Owain Evans. "TruthfulQA: Measuring how models mimic human false ‐ hoods." arXiv preprint arXiv:2109.07958 (2021).
15 Karl Cobbe et al. "Training verifiers to solve math word problems." arXiv preprint a rXiv:2110.14168 (2021).
16 Roman Zellers et al. "HellaSwag: Can a machine really finish your sentence?" arXiv preprint arXiv:1905.07830 (2019).
17 Mark Chen et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021).
排行榜(Leaderboards)
由于存在众多不同的基准测试(benchmarks),很难选择最适合模型的那一个。每当有新模型发布时,人们通常会看到它在多个基准测试中的表现,以全面展示其性能。
为此,人们开发了整合多个基准测试的排行榜。一个常见的例子是Open LLM Leaderboard,截至本文撰写时,它包含了六个基准测试,包括HellaSwag、MMLU、TruthfulQA和GSM8k等。若模型在排行榜上名列前茅(假设其未针对数据过拟合),通常会被视为"最佳"模型。然而,由于这些排行榜往往依赖公开可用的基准测试,存在因过度适配榜单数据而导致的过拟合风险。
自动评估
评估生成输出质量的一部分在于其文本质量。例如,即使两个模型对同一问题给出了相同的正确答案,它们的推导路径可能截然不同。评估的重点往往不仅在于最终答案本身,还在于其构建方式。类似地,虽然两个摘要可能在内容上相似,但其中一个可能明显更简短------而这对于优质摘要而言通常至关重要。
为了衡量生成文本在上述正确性之外的质量,研究者提出了LLM作为评判工具(LLM-as-a-judge)的方法18。其核心理念是:由另一个独立的大语言模型(LLM)负责评判被测模型的输出质量。该方法的一个有趣变体是成对比较法------两个不同的LLM针对同一问题生成答案后,由第三个LLM担任裁判,判定哪一个答案更优。
这种方法的引入使得开放式问题得以实现自动化评估。其主要优势在于:随着LLM自身的进步,它们评判输出质量的能力也会同步提升。换言之,这种评估方法能够与这一领域共同发展。
人 工 评估
尽管基准测试很重要,但评估的黄金标准通常被认为是人工评估。即使一个大型语言模型(LLM)在广泛的基准测试中表现出色,它在特定领域任务中仍可能表现不佳。此外,基准测试无法完全捕捉人类的偏好,而此前讨论的所有方法都只是这种偏好的近似替代指标。
18 Lianmin Zheng et al. "Judging LLM-as-a-judge with MT-Bench and Chatbot Arena." Advances in Neural Information Processing Sys tems 36 (2024).
一种基于人类评估的优秀技术示例是 Chatbot Arena(聊天机器人竞技场)19。当访问该排行榜时,系统会向你展示两个(匿名)大语言模型(LLM),你可以与它们互动。你提出的任何问题或提示都会同时发送给这两个模型,并收到它们的输出结果。随后,你可以选择更偏好的输出。这一过程允许社区在不明确知道模型身份的情况下,通过投票表达对模型的偏好。只有在投票后,你才能看到哪个模型生成了哪段文本。
在撰写本文时,该方法已生成超过80万+的人工投票数据用于计算排行榜。这些投票通过胜率来衡量大语言模型的相对技能水平------例如,如果一个排名较低的LLM击败了排名较高的LLM,其排名会发生显著变化。这种机制类似于国际象棋中的Elo评级系统。
该方法的核心在于采用众包投票,这有助于我们理解LLM的质量。但需注意的是,这种评价反映的是广泛用户群体的综合意见,可能与您的具体使用场景存在偏差。
需要强调的是,不存在完美的LLM评估方法。所有提及的评测手段和基准测试都提供了重要(尽管有限)的评估视角。我们建议根据实际用途评估您的LLM:针对编程任务,HumanEval比GSM8k更具参考价值。
但最重要的是,我们相信您才是最佳评估者。人工评估仍是黄金标准,因为最终应由您判断LLM是否符合预期用途。正如本章案例所示,我们强烈建议您亲自试用这些模型,甚至可以自主设计测试问题。例如,本书作者Jay Alammar(阿拉伯裔)和Maarten Grootendorst(荷兰裔)在与新模型接触时,常会使用母语提出问题进行验证。
关于这一点,我们想引用一句珍视的话:
当一项衡量标准成为目标时,它就不再是一个好标准。
---古德哈特定律 20
在大型语言模型(LLMs)的应用场景中,当我们针对某个特定基准测试进行优化时,往往会不顾后果地追求该指标的最优表现。例如,如果仅专注于优化生成语法正确句子的能力,模型可能学会只输出一个句子:"This is a sentence." 这个句子虽然语法完全正确,却无法展现其语言理解能力的任何维度。因此,模型可能在特定基准测试中表现卓越,但这种优化可能是以牺牲其他实用能力为代价的。
19 Wei-Lin Chiang et al. "Chatbot Arena: An open platform for evaluating LLMs by human preference." arXiv preprint arXiv:2403.04132 (2024).
20 Mafilyn Strathern. "'Improving ratings': audit in the British University system." European Review 5.3 (1997): 305--321.
偏好调优 / 对齐 / 基于人类反馈的强化学习(RLHF)
虽然我们的模型目前已具备指令遵循能力,但通过最终的训练阶段------即将其行为与我们在不同场景下的预期表现对齐,我们还能进一步提升其性能。例如,当被问及"什么是LLM?"时,我们可能期望获得详尽阐释LLM内部运作机制的答案,而非仅以"它是一种大型语言模型"作结。那么,我们究竟如何将对某个答案的人类偏好与LLM的输出结果进行有效对齐?
首先需要明确,如图12-21所示,LLM的工作机制是通过接收提示(prompt)来生成相应的文本内容。

图12-21大型语言模型(LLM)接收输入提示并生成输出内容。
我们可以让一个人(偏好评估者)来评估该模型生成的质量。假设他们给出某个评分,比如4分(见图12-22)。
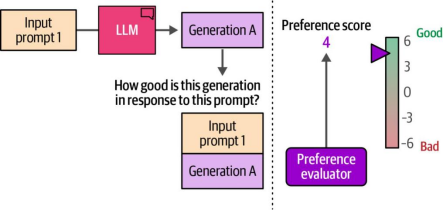
图12-22. 使用偏好评估者(人类或其他方式)评估生成质量
图12-23展示了基于该评分进行模型更新的偏好调优步骤:
如果评分较高:更新模型以鼓励生成更多此类优质内容。
如果评分较低:更新模型以避免生成此类低质内容。
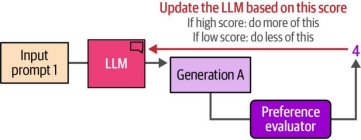
图12-23. 偏好调优方法基于评估分数更新大型语言模型(LLM)
一如既往,我们需要大量的训练样本。那么,我们能否自动化偏好评估呢?是的,我们可以通过训练一个名为奖励模型的不同模型来实现这一点。
利用奖励模型自动化偏好评估
为了实现自动化偏好评估,我们需要在偏好调整步骤之前增加一个环节,即训练奖励模型,如图12-24所示。
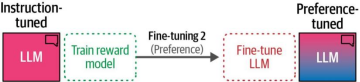
图12-24. 我们在微调大语言模型之前先训练一个奖励模型
图12-25展示了如何创建奖励模型:我们复制一份经过指令微调的模型,并对其进行轻微改造,使其不再生成文本,而是输出单一评分

图12-25. 通过将大语言模型的语言建模头替换为质量分类头,该模型即可转变为奖励模型
奖励模型的输入与输出
该奖励模型的预期工作方式为:向其输入一个提示词(prompt)和对应的生成内容(generation),模型将输出一个单一数值,用于衡量该生成内容针对提示词的偏好性/质量。图12-26展示了奖励模型生成这一单一数值的过程。
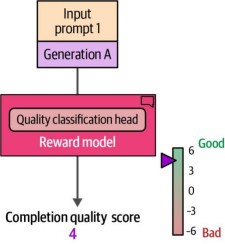
图12-26. 使用基于人类偏好训练的奖励模型来生成完成质量评分
训练奖励模型
我们无法直接使用奖励模型,而是需要先对其进行训练,使其能够正确评估生成内容的质量。为此,我们需要构建一个偏好数据集供模型学习。
奖励模型训练数据集
偏好数据的常见形式是:每个训练样本包含一个提示(prompt)、一个被接受的生成结果和一个被拒绝的生成结果。(注:这并非总是"好"与"坏"的对比,而可能是两个均合理的生成结果中,一个优于另一个的情况。)图12-27展示了一个包含两个训练样本的偏好数据集示例。
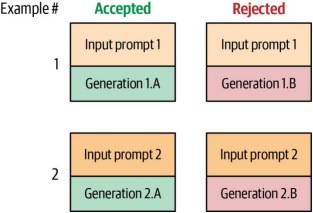
图12-27. 偏好调优数据集通常由包含接受和拒绝生成结果的提示组成.
生成偏好数据的一种方法是向LLM提供一个提示,并让其生成两个不同的输出结果。如图12-28所示,我们可以询问人类标注者选择他们更倾向的版本。
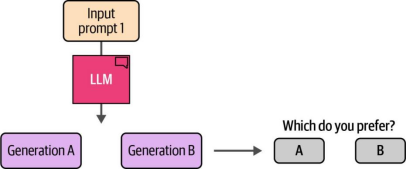
图12-28. 输出两个生成结果,并要求人类标注者选择更偏好哪一个
奖励模型训练步骤
现在我们已经有了偏好训练数据集,就可以开始训练奖励模型了。
一个简单的步骤是使用奖励模型来:
1.对被接受的生成结果进行评分
2.对被拒绝的生成结果进行评分
图12-29展示了训练目标:确保被接受的生成结果的评分高于被拒绝的生成结果。
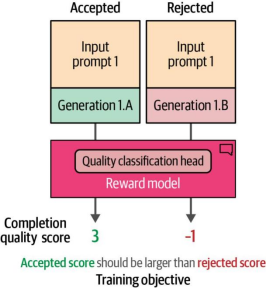
图12-29. 奖励模型旨在评估针对提示生成的回复质量分数
如图12-30所示,将各部分整合后,偏好调优包含三个阶段:
- 收集偏好数据
- 训练奖励模型
- 使用奖励模型微调LLM(作为偏好评估器)
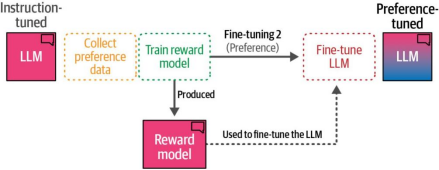
图12-30 偏好调整的三个阶段:收集偏好数据、训练奖励模型,最后对大型语言模型(LLM)进行微调
奖励模型是一个绝佳的思路,具有进一步拓展和发展的潜力。例如,Llama 2 训练了两个奖励模型:一个用于评估有用性(helpfulness),另一个用于评估安全性(safety)(图12-31)。
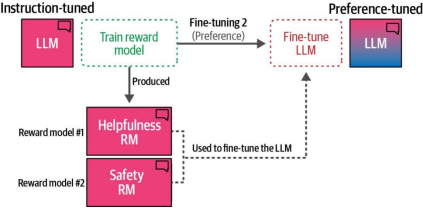
图12-31. 我们可以使用多个奖励模型进行评分
通过训练好的奖励模型微调大型语言模型(LLM)的常用方法是近端策略优化算法(Proximal Policy Optimization, PPO)。PPO是一种流行的强化学习技术,其核心理念是通过确保大型语言模型的输出奖励与预期奖励不过度偏离,从而实现对已具备指令理解能力的LLM的持续优化21。值得一提的是,该算法甚至曾被用于训练2022年11月发布的初代ChatGPT模型。
21 John Schulman et al. "Proximal Policy Optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
无奖励模型训练
PPO(近端策略优化)的一个缺点在于其方法较为复杂,需要至少训练两个模型------奖励模型和大语言模型(LLM),这可能导致成本高于必要水平。
直接偏好优化(DPO)作为PPO的替代方案,摒弃了基于强化学习的过程22。其核心思想是不依赖奖励模型评判生成内容的质量,而是让大语言模型自行完成这一任务。如图12-32所示,DPO通过复制一个大语言模型作为参考模型,评估参考模型与可训练模型在被接受的生成内容与被拒绝的生成内容之间的质量差异。
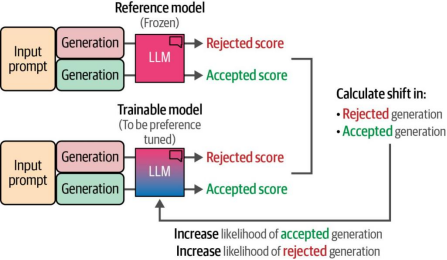
图12-32. 通过比较冻结模型与可训练模型的输出,将LLM本身用作奖励模型
通过在训练过程中计算这种偏移量(shift),我们可以跟踪参考模型与可训练模型之间的差异,从而优化被接受生成结果相对于被拒绝生成结果的可能性。
为了计算这种偏移量及其相关分数,需要从两个模型中提取被拒绝生成结果和被接受生成结果的对数概率。如图12-33所示,这一过程在词元(token)级别进行,通过综合不同词元的概率来计算参考模型与可训练模型之间的偏移量。
22 Rafael Rafailov, et al. "Direct Preference Optimization: Your language model is secretly a reward model." arXiv preprint arXiv:2305.18290 (2023).
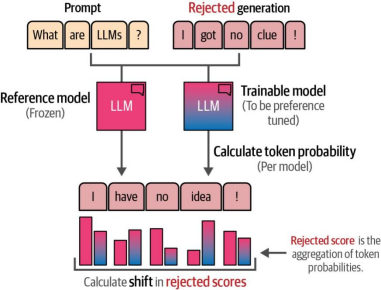
图12-33. 分数通过计算词元级别的生成概率得出。参考模型与可训练模型之间的概率偏移会被优化,被接受的生成样本遵循相同流程
基于这些分数,我们可以优化可训练模型的参数,使其对生成被接受样本更有信心,而对生成被拒绝样本更没信心。与PPO相比,作者发现DPO在训练过程中更稳定且更精准。由于其稳定性,我们将使用DPO作为主要模型,用于对我们此前经过指令微调的模型进行偏好调优。
使用DPO进行偏好调整
当我们使用Hugging Face工具栈时,偏好调整与我们之前介绍的指令微调惊人地相似,但也存在一些细微差异。我们仍将使用TinyLlama模型,但这次是基于指令微调后的版本------该模型首先通过全量微调(full fine-tuning)训练,随后通过DPO(直接偏好优化)进一步对齐。与最初的指令微调模型相比,这个LLM使用了更大的数据集进行训练。
在本节中,我们将展示如何通过DPO结合基于奖励的数据集(reward-based datasets)进一步对齐该模型。
模板化对齐数据
我们将使用一个数据集,其中每个提示词对应一个被接受的生成结果和一个被拒绝的生成结果。该数据集部分由ChatGPT生成,并附有评分以确定哪些输出应被接受,哪些应被拒绝。
python
from datasets import load_dataset
def format_prompt(example):
"""Format the prompt to using the <|user|> template TinyLLama is using"""
# Format answers
system = "<|system|>\n" + example["system"] + "</s>\n"
prompt = "<|user|>\n" + example["input"] + "</s>\n<|assistant|>\n"
chosen = example["chosen"] + "</s>\n"
rejected = example["rejected"] + "</s>\n"
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
# Apply formatting to the dataset and select relatively short answers
dpo_dataset = load_dataset(
"argilla/distilabel-intel-orca-dpo-pairs", split="train"
)
dpo_dataset = dpo_dataset.filter(
lambda r:
r["status"] != "tie" and
r["chosen_score"] >= 8 and
not r["in_gsm8k_train"]
)
dpo_dataset = dpo_dataset.map(
format_prompt, remove_columns=dpo_dataset.column_names
)需要注意的是,我们通过额外的过滤步骤对数据进行了进一步缩减,将原始13,000个样本精简至约6,000个样本。
模型量化
我们加载基础模型并载入先前创建的LoRA。与之前相同,我们对模型进行量化以减少训练所需的显存占用:
python
from peft import AutoPeftModelForCausalLM
from transformers import BitsAndBytesConfig, AutoTokenizer
# 4-bit quantization configuration - Q in QLoRA
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Use 4-bit precision model loading
bnb_4bit_quant_type="nf4", # Quantization type
bnb_4bit_compute_dtype="float16", # Compute dtype
bnb_4bit_use_double_quant=True, # Apply nested quantization
)
# Merge LoRA and base model
model = AutoPeftModelForCausalLM.from_pretrained(
"TinyLlama-1.1B-qlora",
low_cpu_mem_usage=True,
device_map="auto",
quantization_config=bnb_config,
)
merged_model = model.merge_and_unload()
# Load LLaMA tokenizer
model_name = "TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = "<PAD>"
tokenizer.padding_side = "left"接下来,我们使用与之前相同的LoRA配置来进行DPO训练:
python
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
# Prepare LoRA configuration
peft_config = LoraConfig(
lora_alpha=32, # LoRA Scaling
lora_dropout=0.1, # Dropout for LoRA Layers
r=64, # Rank
bias="none",
task_type="CAUSAL_LM",
target_modules= # Layers to target
["k_proj", "gate_proj", "v_proj", "up_proj", "q_proj", "o_proj","down_proj"]
)
# prepare model for training
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)训练配置
为简单起见,我们将使用与之前相同的训练参数,但有一个区别。为了说明目的,我们不是运行单个轮次(可能需要长达两小时),而是改为运行200步。此外,我们添加了warmup_ratio参数,该参数会在前10%的步骤中将学习率从0线性增加到我们设置的learning_rate值。通过在初始阶段保持较小的学习率(即热身阶段),我们允许模型在应用更大的学习率之前适应数据,从而避免有害的发散:
python
from trl import DPOConfig
output_dir = "./results"
# Training arguments
training_arguments = DPOConfig(
output_dir=output_dir,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
learning_rate=1e-5,
lr_scheduler_type="cosine",
max_steps=200,
logging_steps=10,
fp16=True,
gradient_checkpointing=True,
warmup_ratio=0.1
)训练
现在我们已经准备好了所有模型和参数,可以开始微调模型:
python
from trl import DPOTrainer
# Create DPO trainer
dpo_trainer = DPOTrainer(
model,
args=training_arguments,
train_dataset=dpo_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1,
max_prompt_length=512,
max_length=512,
)
# Fine-tune model with DPO
dpo_trainer.train()
# Save adapter
dpo_trainer.model.save_pretrained("TinyLlama-1.1B-dpo-qlora")我们创建了第二个适配器。为了合并这两个适配器,我们通过迭代方式将适配器逐步与基础模型进行融合:
python
from peft import PeftModel
# Merge LoRA and base model
model = AutoPeftModelForCausalLM.from_pretrained(
"TinyLlama-1.1B-qlora",
low_cpu_mem_usage=TΓue,
device_map="auto",
)
sft_model = model.merge_and_unload()
# Merge DPO LoRA and SFT model
dpo_model = PeftModel.from_pretrained(
sft_model,
"TinyLlama-1.1B-dpo-qlora",
device_map="auto",
)
dpo_model = dpo_model.merge_and_unload()SFT+DPO的组合是一种很好的方法,首先可以对模型进行微调以执行基本聊天,然后将其答案与人类偏好对齐。然而,这种方法确实存在成本,因为我们需要执行两次训练循环,并可能需要调整两个过程中的参数。
自DPO发布以来,已经开发出新的偏好对齐方法。值得注意的是优势比偏好优化(Odds Ratio Preference Optimization, ORPO),这一方法将SFT和DPO合并为一个训练过程23。它无需执行两次独立的训练循环,在进一步简化训练过程的同时仍允许使用QLoRA。
本章小结
在本章中,我们探讨了微调预训练大语言模型(LLMs)的不同步骤。我们通过低秩适应(LoRA)技术,利用参数高效微调(PEFT)方法完成了微调。我们还解释了如何通过量化(一种减少模型参数和适配器内存占用的技术)扩展LoRA的应用。
我们所探讨的微调过程包含两个步骤:
第一步: 使用指令数据对预训练LLM进行监督微调(通常称为指令微调),得到一个具有类人对话行为且能严格遵循指令的模型。
第二步: 通过在代表答案偏好的对齐数据上进一步微调,提升模型性能。这一过程称为偏好调优,其目标是将人类偏好提炼到先前经过指令微调的模型中。
总体而言,本章展示了微调预训练LLM的两大核心步骤,并说明了这些步骤如何帮助模型生成更准确、信息量更丰富的输出。
23 Jiwoo Hong, Noah Lee, and James Thorne, "ORPO: Monolithic preference optimization without reference model" . arXiv preprint arXiv:24 03.07691 (2024).