本文翻译整理自:https://github.com/facebookresearch/sam2
文章目录
-
- [一、关于 SAM 2](#一、关于 SAM 2)
- 二、最新更新
-
- [1、2024-12-11 更新](#1、2024-12-11 更新)
- [2、2024-09-30 更新](#2、2024-09-30 更新)
- 三、安装指南
-
- 系统要求
- 安装步骤
- [Windows 用户注意](#Windows 用户注意)
- 额外依赖(运行示例笔记本)
- 安装注意事项
- 四、快速入门
- [五、从 Hugging Face 加载](#五、从 Hugging Face 加载)
- 六、模型描述
-
- [1、SAM 2.1 检查点(2024-09-29 发布)](#1、SAM 2.1 检查点(2024-09-29 发布))
- [2、SAM 2 检查点(2024-07-29 发布)](#2、SAM 2 检查点(2024-07-29 发布))
一、关于 SAM 2
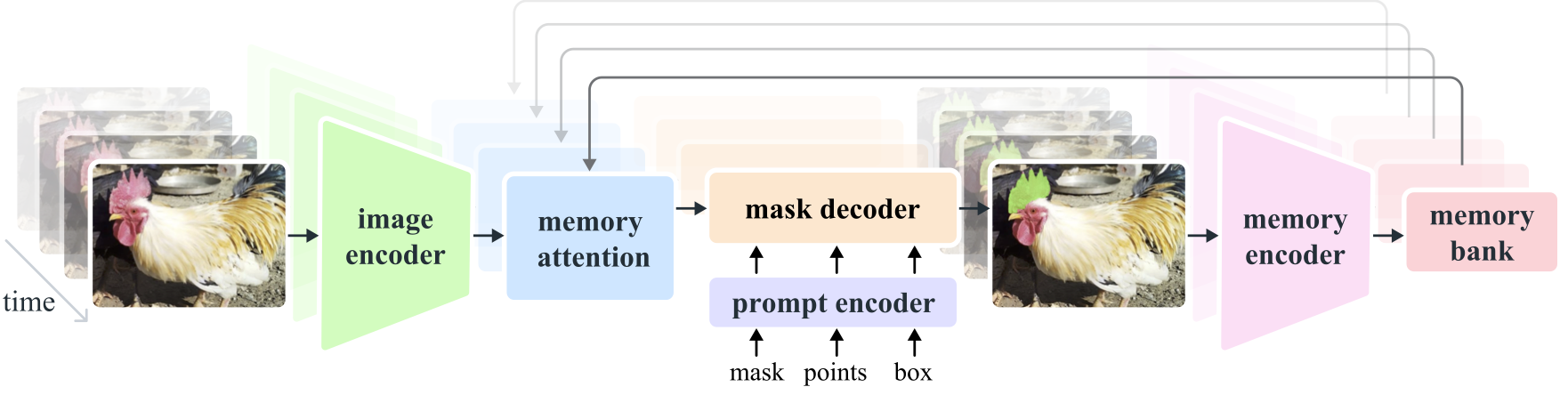
Segment Anything Model 2 (SAM 2) 是一个基础模型,旨在解决图像和视频中的可提示视觉分割问题。
将单帧图像视为视频的特殊形式,从而将 SAM 的能力扩展到视频领域。该模型采用简单的 Transformer 架构,并引入流式内存机制以实现实时视频处理。
构建了一个"模型在环"数据引擎,通过用户交互持续优化模型和数据,最终收集了迄今为止最大的视频分割数据集 SA-V。
基于该数据集训练的 SAM 2 在广泛的任务和视觉领域都展现出强大性能。

相关链接资源
- github : https://github.com/facebookresearch/sam2
- 官网:https://ai.meta.com/sam2
- 官方文档:https://ai.meta.com/research/publications/sam-2-segment-anything-in-images-and-videos/
- Demo/在线试用:https://sam2.metademolab.com/
- SA-V 数据集:https://ai.meta.com/datasets/segment-anything-video
- 训练 SAM 2 : https://github.com/facebookresearch/sam2/blob/main/training/README.md
支持在自定义图像/视频数据集上进行训练和微调 - 本地部署版 Demo 代码参见:https://github.com/facebookresearch/sam2/blob/main/demo/README.md
- Blog : https://ai.meta.com/blog/segment-anything-2
- Hugging Face : https://huggingface.co/models?search=facebook/sam2
- License : Apache 2.0
关键功能特性
1、统一图像与视频分割 :通过将图像视为单帧视频,实现统一处理框架
2、实时视频处理 :采用流式内存的 Transformer 架构,支持实时推理
3、多目标跟踪 :支持视频中多个对象的独立推理与跟踪
4、模型优化 :支持 torch.compile 全模型编译,显著提升推理速度
5、大规模数据集:基于 SA-V 数据集(当前最大视频分割数据集)训练
二、最新更新
1、2024-12-11 更新
- 支持全模型
torch.compile编译,通过设置vos_optimized=True可显著提升视频对象分割(VOS)推理速度 - 更新
SAM2VideoPredictor实现,支持多目标跟踪中独立的对象推理 - 详情查看:<RELEASE_NOTES.md>
2、2024-09-30 更新
- 发布 SAM 2.1 系列改进模型检查点(详见模型描述)
- 开放训练与微调代码:<training/README.md>
- 发布网页版 Demo 代码:<demo/README.md>
三、安装指南
系统要求
- Python ≥ 3.10
- PyTorch ≥ 2.5.1 和 torchvision ≥ 0.20.1
安装步骤
bash
git clone https://github.com/facebookresearch/sam2.git && cd sam2
pip install -e .Windows 用户注意
强烈建议使用 WSL 配合 Ubuntu 环境安装。
额外依赖(运行示例笔记本)
bash
pip install -e ".[notebooks]"安装注意事项
1、推荐使用 Anaconda 创建新 Python 环境
2、需安装匹配 PyTorch 版本的 CUDA 工具包
3、若出现 Failed to build the SAM 2 CUDA extension 警告可忽略(仅影响部分后处理功能)
4、更多问题参考:INSTALL.md
四、快速入门
1、下载模型检查点
下载所有检查点:
bash
cd checkpoints && ./download_ckpts.sh && cd ..或单独下载:
2、图像分割示例
python
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)更多图像用例参考:
3、视频分割示例
python
import torch
from sam2.build_sam import build_sam2_video_predictor
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# 添加新提示并立即获取当前帧输出
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>)
# 在视频中传播提示以获取连续掩码
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...视频用例详情参考:video_predictor_example.ipynb
五、从 Hugging Face 加载
1、图像预测
python
from sam2.sam2_image_predictor import SAM2ImagePredictor
predictor = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")2、视频预测
python
from sam2.sam2_video_predictor import SAM2VideoPredictor
predictor = SAM2VideoPredictor.from_pretrained("facebook/sam2-hiera-large")六、模型描述
1、SAM 2.1 检查点(2024-09-29 发布)
| 模型 | 参数量(M) | 速度(FPS) | SA-V测试(J&F) | MOSE验证(J&F) | LVOS v2(J&F) |
|---|---|---|---|---|---|
| sam2.1_hiera_tiny | 38.9 | 91.2 | 76.5 | 71.8 | 77.3 |
| sam2.1_hiera_small | 46 | 84.8 | 76.6 | 73.5 | 78.3 |
| sam2.1_hiera_base_plus | 80.8 | 64.1 | 78.2 | 73.7 | 78.2 |
| sam2.1_hiera_large | 224.4 | 39.5 | 79.5 | 74.6 | 80.6 |
2、SAM 2 检查点(2024-07-29 发布)
| 模型 | 参数量(M) | 速度(FPS) | SA-V测试(J&F) | MOSE验证(J&F) | LVOS v2(J&F) |
|---|---|---|---|---|---|
| sam2_hiera_tiny | 38.9 | 91.5 | 75.0 | 70.9 | 75.3 |
| sam2_hiera_small | 46 | 85.6 | 74.9 | 71.5 | 76.4 |
| sam2_hiera_base_plus | 80.8 | 64.8 | 74.7 | 72.8 | 75.8 |
| sam2_hiera_large | 224.4 | 39.7 | 76.0 | 74.6 | 79.8 |
注:速度测试基于 A100 + torch 2.5.1, cuda 12.4,参考 benchmark.py 进行基准测试。
伊织 xAI 2025-04-25(五)