一、大模型概述
1、大模型概念
LLM是指用有大量参数的大型预训练语言模型,在解决各种自然语言处理任务方面表现出强大的能力,甚至可以展现出一些小规模语言模型所不具备的特殊能力
2、语言模型language model
语言建模旨在对词序列的生成概率进行建模,以预测未来tokens的概率,语言模型的发展:
1)统计语言模型SLM: 统计语言模型使用马尔可夫假设(Markov Assumption)来建立语言序列的预测模型,通常是根据词序列中若干个连续的上下文单词来预测下一个词的出现概率,经典的例子是n-gram模型,在此模型中一个词出现的概率只依赖于前面的n-1个词,比如一个3gram模型只考虑前两个词对第三个词出现概率的影响
2)神经语言模型NLM:使用神经网络来预测词序列的概率分布,如RNN包括LSTM和GRU等变体,这样NLM就可以考虑更长的上下文或整个句子的信息,而传统的统计语言模型使用固定窗口大小的词来预测;在该模型中引入分布式词表示,每个单词被编码为实数值向量,即词嵌入(word embeddings)用来捕捉词与词之间的语法关系
3)预训练语言模型PLM: PLM开始在规模无标签语料库上进行预训练任务,学习语言规律知识,并且针对特定任务进行微调(fine-tuning)来适应不同应用场景;而对于大规模的长文本,谷歌提出了transformer--通过自注意力机制(self- attention)和高度并行化能力,可以在处理序列数据时捕捉全局依赖关系,极大提高序列处理任务的效率
4)大语言模型LLM: 当一些研究工作尝试训练更大的预 训练语言模型(例如 175B 参数的 GPT-3 和 540B 参数的 PaLM)来探索扩展语言 模型所带来的性能极限。这些大规模的预训练语言模型在解决复杂任务时表现出 了与小型预训练语言模型(如 330M 参数的 BERT 和 1.5B 参数的 GPT2)不同 的行为,这种大模型具 有但小模型不具有的能力通常被称为"涌现能力"(Emergent Abilities),这些大型的预训练模型就是LLM

3、大模型特点
1)参数数量庞大,数据需求巨大
2)计算资源密集
3)泛化能力强
4)迁移学习效果佳
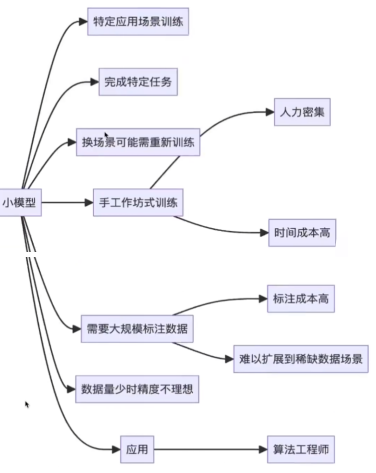
4、小模型vs大模型
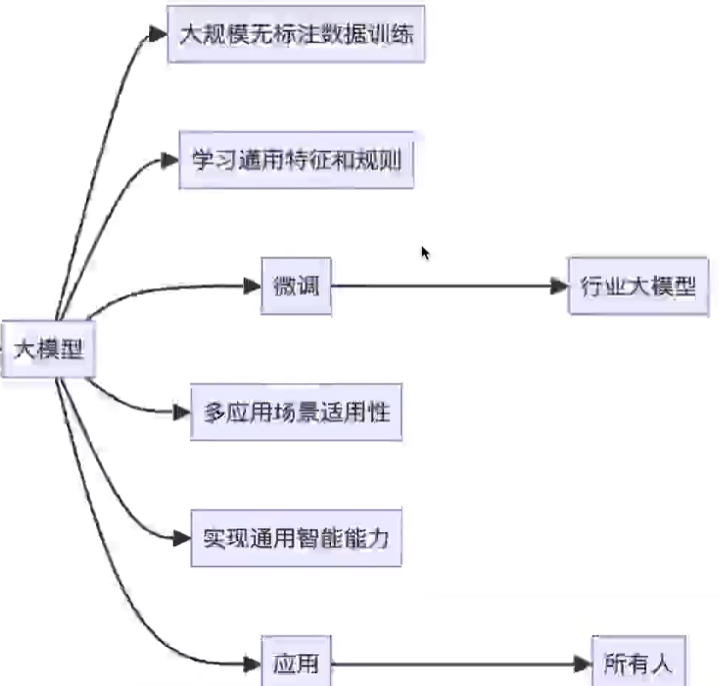
5、大模型企业应用
1)通用大模型

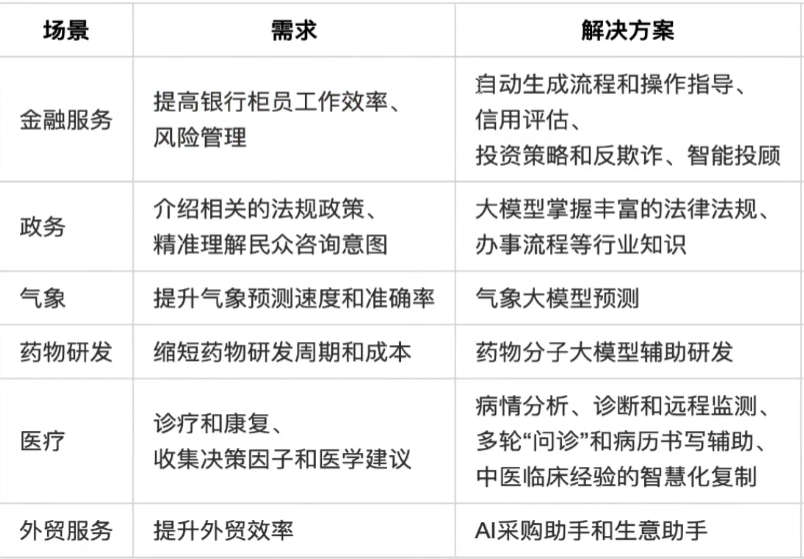
2)行业大模型
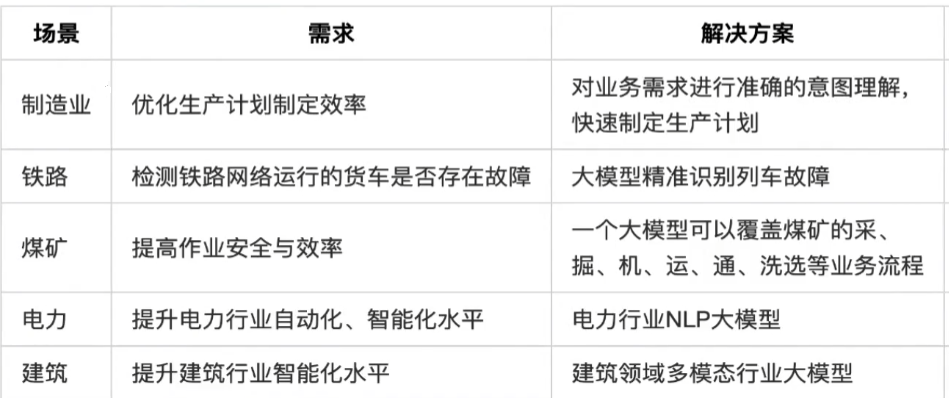
3)产业大模型
二、大模型基础
1、大模型构建过程
1)大规模预训练 (Large-Scale Pre-training)
|----------|--------------------------------------------------------------------------------------------------------------------------------------------------|
| 目标 | 为模型参数找到好的"初值点",使其编码世界知识 ,具备通用的语言理解和生成能力。可以看作是世界知识的压缩。 |
| 方法 | 使用海量(当前普遍 2~3T tokens 规模,并有扩大趋势)的无标注文本数据 ,通过自监督学习任务(当前主流是"预测下一个词 ")训练解码器架构 (Decoder Architecture) 模型。 |
| 关键要素 | 1. 数据:高质量、多源化数据的收集与严格清洗至关重要,直接影响模型能力。 2. 算力:需求极高(百亿模型需数百卡,千亿模型需数千甚至万卡集群),训练时间长。 3. 技术与人才:涉及大量经验性技术(数据配比、学习率调整、异常检测等),高度依赖研发人员的经验和能力。 |
2)指令微调与人类对齐 (Instruction Fine-tuning & Human Alignment)
|----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 动机 | 预训练模型虽有知识,但不擅长直接按指令解决任务。需要进一步训练以适应人类的使用方式和价值观。 |
| 指令微调 | 目标 :使模型学会通过问答形式解决任务。 方法 :使用"任务输入-输出 "配对数据进行有监督的模仿学习 (Imitation Learning)。 作用 :主要在于激发模型在预训练阶段学到的能力,而非注入新知识。 资源:所需数据量(数十万到百万级)和算力远小于预训练。 |
| 人类对齐 | 目标 :使模型行为符合人类的期望、需求和价值观(如"有用、诚实、无害")。 主流方法 : RLHF (基于人类反馈的强化学习)。 RLHF过程 : 标注员对模型输出进行偏好排序 -> 训练奖励模型 (Reward Model) -> 使用强化学习根据奖励模型优化语言模型。 资源:通常比SFT消耗多,但远小于预训练。也在探索更简化的对齐方法。 |
| 产出 | 一个能够进行良好人机交互 ,能按指令解决问题,并且行为更符合人类期望的最终模型。 |
2、扩展法则
通过增大模型参数量、训练数据量和计算量来提升模型能力,而且这种提升往往比改进模型架构或算法本身带来的提升更显著。 为了量化研究这种规模扩展带来的性能提升,研究人员提出了扩展法则来研究规模扩展与模型性能(通常用损失函数 Loss 来衡量)的关系,可以帮助预测不同资源投入下的模型性能:
1)KM 扩展法则
建立模型性能与三个主要因素模型规模 N (参数量)、数据规模 D (token 数量)、计算算力 C (通常指训练期间的总计算量) 之间的幂律关系
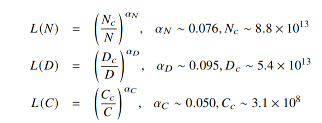
推论:为了达到最低的 Loss,增大模型规模 N 比增大训练数据量 D 更有效。也就是说,分配更多计算资源给模型参数增长,带来的收益更大。
2)Chinchilla 扩展法则
该法则认为 KM 法则可能低估了数据规模 D 的重要性。他们在给定计算预算 C 下,同时调整 N 和 D提出了新的扩展法则
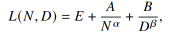
推论:对于给定的计算预算 C,要达到最优性能(最低 Loss),模型规模 N 和数据规模 D 应该按比例同步扩展 。他们的研究表明,最优的 N 和 D 大约与 C 的平方根 成正比,意味着计算预算应该大致平均分配给模型规模增长和数据规模增长
3)局限性
-
扩展法则主要预测的是预训练损失 (Pre-training Loss) ,这与模型在具体下游任务上的表现、涌现能力 (Emergent Abilities, 如推理、遵循复杂指令)以及对齐后 (如 RLFH 后)的实际效果不完全等同。
-
模型性能是多维度的,Loss 只是其中一个指标。扩展法则难以预测模型是否"有用"、"诚实"、"无害"等对齐相关的特性。
-
存在逆向扩展现象 (Inverse Scaling):在某些特定任务或指标上,模型规模增大反而导致性能下降。
-
数据质量的影响难以简单量化进 D 中,但对模型能力至关重要。
3、涌现能力
特征:特定任务的性能在模型规模达到某个阈值后,出现突然的、远超随机水平的性能跃升
1)上下文学习 (In-context Learning, ICL)
模型能根据提示中给出的少量任务示例(Demonstrations)来完成新任务,无需进行模型参数的更新(梯度下降)。
例子: GPT-3 (175B) 展现出强大的ICL能力,而GPT-1/2则不具备。能力也与任务相关,例如13B的GPT-3在简单算术上可以ICL,但175B在波斯语问答上效果不佳。
2)指令遵循 (Instruction Following):
模型能理解并执行自然语言指令来完成任务,即使没有在提示中给出具体示例(零样本泛化)。通常通过指令微调 (Instruction Tuning ),使用大量(任务指令,任务输出)的数据对进行训练。
例子: FLAN-PaLM 在规模达到 62B 及以上时,才在复杂的 BBH 推理基准上展现出较好的零样本能力。但较小模型(如 2B)用高质量数据微调也能掌握一定(尤其是简单任务)指令遵循能力。
3)逐步推理 (Step-by-step Reasoning)
模型能解决需要多个推理步骤的复杂任务(如数学应用题),特别是利用思维链 (Chain-of-Thought, CoT) 提示策略时,即在提示中引导模型生成中间的推理步骤,从而得到更可靠的答案。
例子: CoT 对 PaLM 的 62B 和 540B 模型在算术推理上有提升,但对 8B 模型效果不明显,且在 540B 上提升更显著。提升效果也因任务而异。