背景
之前有监督模型案例都做烂了,现在来做一下无监督的模型吧,异常检测模型。
其实这个案例主要目的是为了展示这些异常值的无监督算法怎么使用的,本文是一个无监督算法的总结大全。只是恰巧有同学需要做这个内幕交易的数据,因此才使用这个数据作为展示异常时监测算法的使用罢了。
内部交易不可能是凭借几个数据就能检测出来的,因此本文的这个实际背景经济含义可以看看就行了,没啥真正的作用,主要还是展示怎么使用这些异常值检测算法。
其实大多数时候,异常时检测算法,由于基本是无监督模型,效果肯定是没有有监督好的。
那为什么还是有很多人会用?主要就是因为很多情况下我们都是没有标签的,在你不知道他是不是异常的情况下,你必须用一些方法去给他强行聚类出来,就得使用无监督的算法,将一些异常的点找出来。(虽然可能并不是你想要的异常点)
数据介绍
大体上就是一些公司,然后他们各自的财务数据,这些公司有的是阳性,也就是说他可能存在内幕交易,有的是阴性,那么就不存在内部交易。
特征X就是各种市场的数据,例如换手率,市盈率,市净率,还有一些资产负债表的数据以及上市股东的一些持仓市值等。
本来无监督学习不应该是有y的,也就是说不应该是有响应变量标签的。但是这里为了评估一下这个模型效果好不好,所以说我们还是把标签带上,用无监督方法锯出来的标签和这些真实的标签进行一个对比。
当然本次的数据和全部代码文件获取还是可以参考:内幕异常监测
算法介绍
无监督的方法其实没有有监督用的那么常见,所以知道的人不是很多,但是总体而言还是有不少的,例如下面十几种:
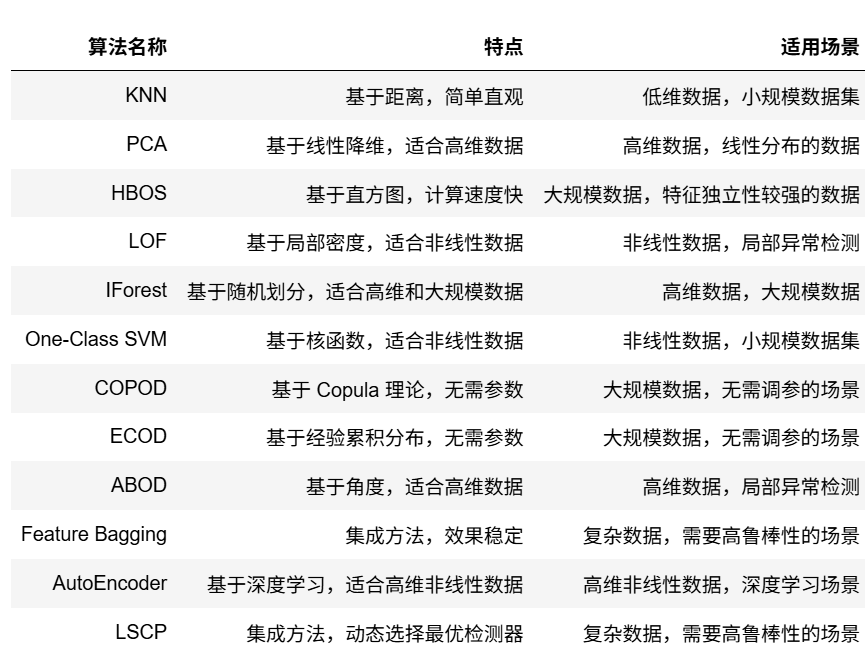
如何选择算法?
数据规模:
- 小规模数据:KNN、LOF、One-Class SVM。
- 大规模数据:HBOS、IForest、COPOD、ECOD。
数据维度:
- 低维数据:KNN、LOF。
- 高维数据:PCA、IForest、COPOD、AutoEncoder。
数据分布:
- 线性分布:PCA。
- 非线性分布:LOF、One-Class SVM、AutoEncoder。
是否需要调参:
- 无需调参:COPOD、ECOD。
- 需要调参:KNN、LOF、One-Class SVM。
而这些方法都可以很便捷的使用pyod进行获取对应写好的类,调包就行了。那些指望看手搓代码的兄弟就不用指望了。手搓这些异常时检测的代码可能搓到明年一个都写出不来.....出来了可能换个数据就会报错。我一直都是实用主义,能用就行了,明明别人已经写好的轮子,明明别人写好的,现成的封装的类更好用,干嘛还要自己手搓?.........98%的人写论文和研究都是掉包的。(当然需要真正创新的大佬当我没说)
普通人安装 pyod库就行了,不会安装可以问AI。反正都是PIP的方法。
代码实现
我们先导入这个现成的异常检测模型的类看一看:
python
# 导入所有常用的 PyOD 模型
from pyod.models.knn import KNN
from pyod.models.pca import PCA
from pyod.models.hbos import HBOS
from pyod.models.lof import LOF
from pyod.models.iforest import IForest
from pyod.models.ocsvm import OCSVM
from pyod.models.copod import COPOD
from pyod.models.ecod import ECOD
from pyod.models.abod import ABOD
from pyod.models.feature_bagging import FeatureBagging
from pyod.models.lscp import LSCP
# 将所有模型类放入一个列表
models_dict = {
"KNN": KNN,
"PCA": PCA,
"HBOS": HBOS,
"LOF": LOF,
"IForest": IForest,
"One-Class SVM": OCSVM,
# "COPOD": COPOD,
# "ECOD": ECOD,
# "ABOD": ABOD,
# "Feature Bagging": FeatureBagging,
}
# 打印模型列表
for model in models_dict.values():
print(model.__name__)我在模型字典里面注释掉了一些模型,主要是因为这些模型需要安装一些别的库,我没有装........
pyod这个库看来也不是自己纯手搓的,也是从别人的库上面建成的。如果需要用到这些被注释掉的方法,那就去看它对应的调用的时候报错,没有哪些库就去装一下好了。
下面开始正式的数据分析过程,数据分析第一步,先导入数据分析四剑客的包。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号再导入一些机器学习常用的预处理的方法
python
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split读取数据
python
df=pd.read_excel('data.xlsx',sheet_name='总表').iloc[:,:].set_index('证券代码').drop(columns='证券简称')
df=df[df['市净率']!='市净率']然后我们需要将阴性,阳性的这种文本型的标签处理为数值型。
python
def check(txt):
if '阳性' in txt:
return 1
elif '阴性' in txt:
return 0
else:
return np.nanapply向量化处理
python
df['label']=df['[阳性样本]总表'].astype('str').apply(check)
df=df.iloc[:,1:]
df.shape
可以看到数据只有300多条,然后有30列特征以及一个y,总共31列。
查看前五行
python
df.head()
查看数据信息
python
df.info()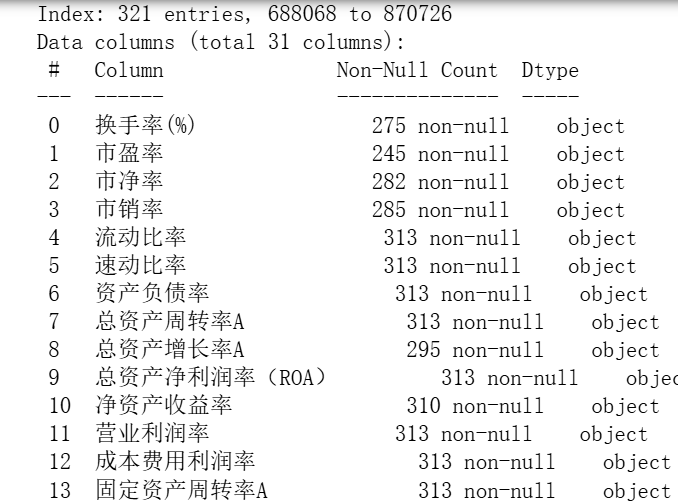
可以看到有些数据存在一定的缺失值,不过没关系,这些都是不重要的,因为pyod里面的类都还是支持缺失数据直接输入的。
特征工程
分离X和y
python
X=df.drop(columns='label')
y=df['label']
X.shape,y.shape查看y的分布比例
python
y.value_counts(normalize=True)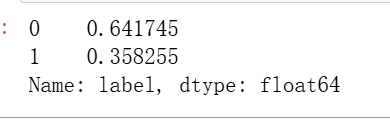
进行数据标准化
python
scaler = StandardScaler()
# 进行标准化
X_s = scaler.fit_transform(X)
# 将标准化后的数据转换为DataFrame
X_s = pd.DataFrame(X_s, columns=X.columns)
X_s=X_s.fillna(X_s.mean())
X_s.shape
无监督 效果对比
自定义一个函数,输入我们的标准化后的数据和标签,还有模型的类,可以自动训练这个模型,然后在这个上面进行预测。得到他这个模型认为的所谓异常的标签之后,再跟真实值去做对比,计算一些评价指标分类问题很常见的一些评价指标,例如准确率,精准率,召回率,F1值,特异度,灵敏度等。
python
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# 定义函数:训练模型、预测并评估
def evaluate_model(model_class, X, y):
"""
训练模型并返回评估指标。
参数:
- model_class: 模型的类(如 KNN, PCA 等)。
- X: 数据特征。
- y: 数据标签。
返回:
- 包含评估指标的字典。
"""
# 初始化模型
model = model_class(contamination=0.358255)
X=np.array(X)
# 训练模型
model.fit(X)
# 预测
y_pred = model.predict(X) # 预测标签(0: 正常, 1: 异常)
y_pred_score=model.decision_function(X)
# 计算评估指标
accuracy = accuracy_score(y, y_pred)
precision = precision_score(y, y_pred)
recall = recall_score(y, y_pred)
f1 = f1_score(y, y_pred)
# 计算特异率(Specificity)
tn, fp, fn, tp = confusion_matrix(y, y_pred).ravel()
specificity = tn / (tn + fp)
# 返回评估指标
return {
'Accuracy': accuracy,
'Precision': precision,
'Recall': recall,
'F1': f1,
'Specificity': specificity
},y_pred_score
# 初始化结果数据框
df_eval = pd.DataFrame(columns=['Accuracy', 'Precision', 'Recall', 'F1', 'Specificity'])遍历模型列表,将所有的模型都进行统一的训练评估,然后将评估结果存在一个数据框里面查看。
python
y_pred_score_dict={}
models=models_dict.values()
for model_class in models:
model_name = model_class.__name__ # 获取模型名称
print(f"Evaluating {model_name}...")
# 训练模型并评估
metrics, y_pred_score = evaluate_model(model_class, X_s, y)
y_pred_score_dict[model_name]=y_pred_score
# 将结果添加到数据框
df_eval.loc[model_name,:] = list(metrics.values())
df_eval.shape
查看评价指标
python
df_eval#.style.bar(color='pink')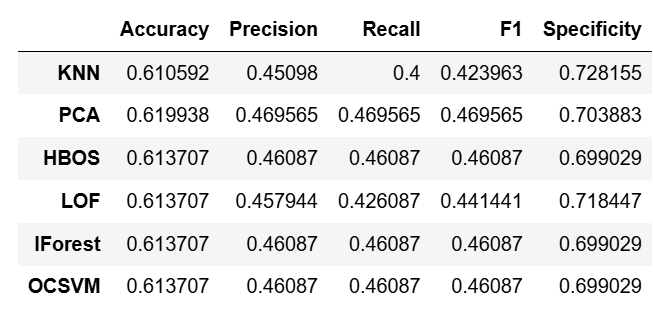
从F1值上来看的话,大概是PCA的效果是最好的。准确率上来说也是如此,大概能有61%的样本能被正确分类。召回率上来看的话,大概只有46.95%的黑样本,也就是所谓的内幕交易能够被检测出来。
评价指标可视化其柱状图
python
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','gold','r']
fig, ax = plt.subplots(2,2,figsize=(8,6),dpi=128)
for i,col in enumerate(df_eval.columns[:-1]):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()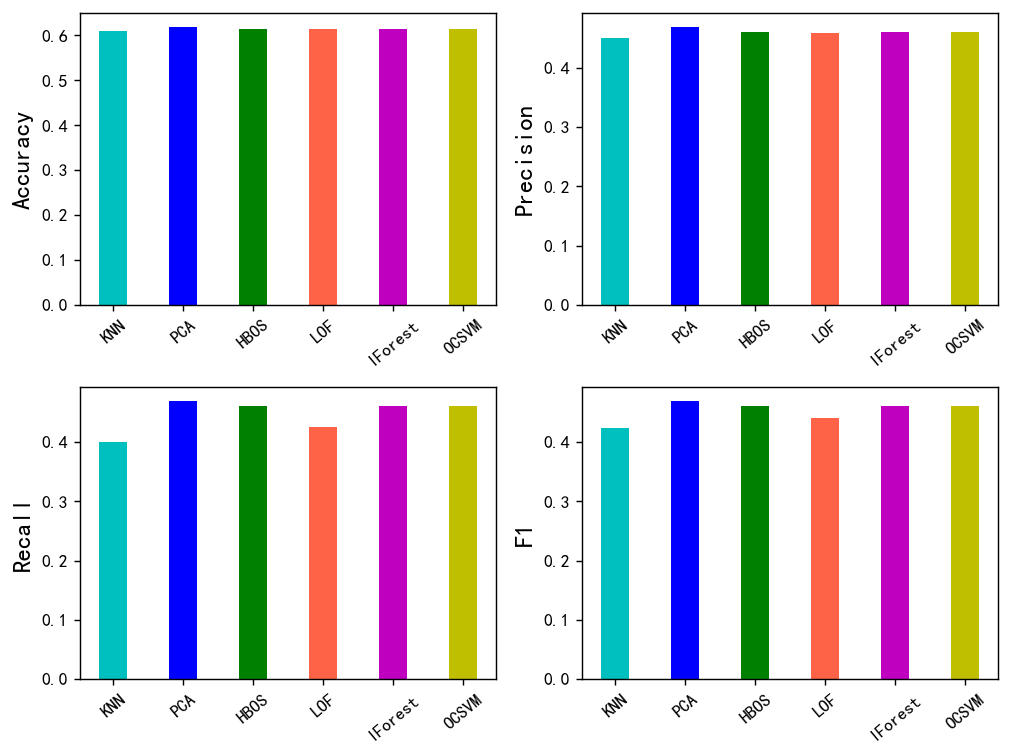
画出ROC曲线图,计算AUC
python
for k,v in y_pred_score_dict.items():
y_pred_score_dict[k]=(v-v.min())/(v.max()-v.min())
python
from sklearn.metrics import roc_curve, auc
plt.figure(figsize=(7, 4.5),dpi=128)
# 遍历每个模型绘制 ROC 曲线
for model_name, y_scores in y_pred_score_dict.items():
fpr, tpr, _ = roc_curve(y, y_scores) # 计算假阳性率和真阳性率
roc_auc = auc(fpr, tpr) # 计算 AUC 值
plt.plot(fpr, tpr, label=f'{model_name} (AUC = {roc_auc:.4f})') # 绘制 ROC 曲线
# 绘制对角线
plt.plot([0, 1], [0, 1], 'k--', label='Random Classifier (AUC = 0.50)')
# 添加图例和标签
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
# 显示图形
plt.show()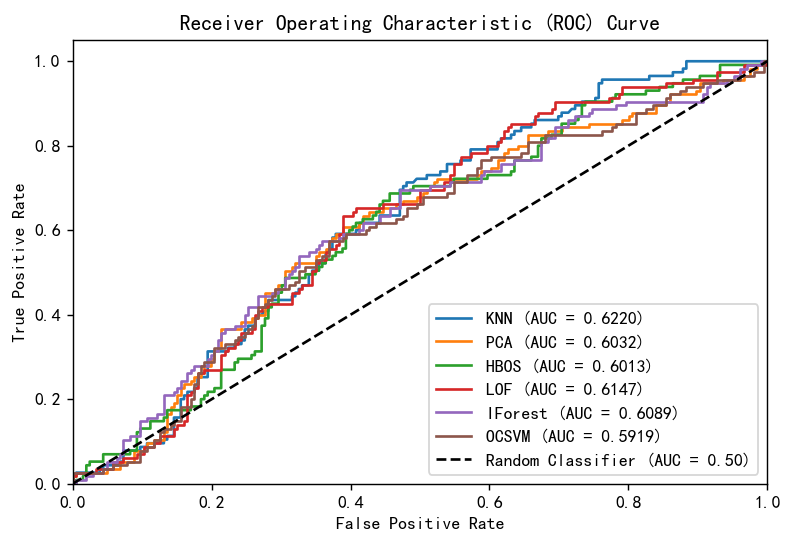
可以看到虽然模型的召回和F1值没有那么高,并且也只有60%的准确率,但是总体上来说比随机猜测效果还是要好一些的。从AUC上来看的话,效果最好的是LOF模型。
也就是说这些模型用来做异常检测的话还是能起到一定的判断效果的。
总结
其实本文具体的数据含义或者说经济业务含义不用太关注,因为本身想从几个数据指标,财务公司指标去判断这个公司有没有内幕交易,本身就是一件很困难的事情,数据决定预测效果质量,模型只是逼进这个上限罢了。如果这个数据本身就对我们的标签没有太多的解释力,那么模型再厉害也不可能能够准确的预测出来。本身这个内幕交易的数据x对y只有这么点解释力,所以说异常检测的模型只有这么点效果也是很正常的,但整体上来说还是比随机猜测要好一些。
由于异常检测是无监督的,其实其检测方式还是和模型算法自身的特性有很强的关系。这个肯定得需要根据特定的数据找特定的异常的时候去设计特定的算法罢了,本文只是对通用的,简便的,能快速使用的,一些异常值检测的方法的一个总结演示。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)