目录
前言:
在前文我们介绍了Redis的主从复制有一个最大的缺点就是,主节点挂了之后没有办法迅速重启,毕竟即便主节点挂了,人工干预恢复的话,也要花费许多时间,想必各位程序员也不想在夜深人静的时候突然去公司加班就为了修复一下主节点吧?
所以,Redis引入了另一个进制,即哨兵机制,一般来说只用主从模式的话,可用性不是很高的,所以一般来说式主从模式+哨兵一起使用。
那么我们本文就是围绕哨兵展开一系列的学习了。
引入哨兵
首先我们只是知道主从复制一旦主节点挂了之后的后果还是比较严重的,我们现在就来更加细化一下主节点挂了之后的修复工作。
当我们没有引入哨兵机制的时候,主节点挂了的流程应该是这样的:
1.先看主节点是否容易抢救,好不好抢救
2.如果主节点好抢救,那么也算是万事大吉了
3.如果主节点不好抢救,即短时间找不到原因
i)挑选一个从节点,通过slaveof no one使它成为主节点
ii)把其他的从节点通过命令行slaveof newHostip newHostport的方式连接新的主节点
iii)修改客户端的配置,使得每个客户端能够成功连接上新的主节点,从而完成数据修改的操作
这个过程看起来简单,但是实际上我们知道的是,这一套流程下来,多的不说,至少半个小时就耗进去了吧?
那么在这个时间段内,读的请求无所谓,有其他的从节点支撑着,但是写的请求呢?既然都引入了分布式系统,那么写的请求想必也不会少到哪里去,那么这个事件给整个公司带来的冲击还是比较大的。
所以我们需要一个类似于监管者的角色,用来实时检测每个节点的情况,比如某个节点挂了,这个监管者看到了就要开始干对应的事儿了。
那么,我们将这个监管者,称之为"哨兵"。这样我们就可以舍去对应的人工成本了。但是我们要注意的点是哨兵并不是我们的Redis服务器,它是单独部署在其他服务器的一个Redis sentinel进程。
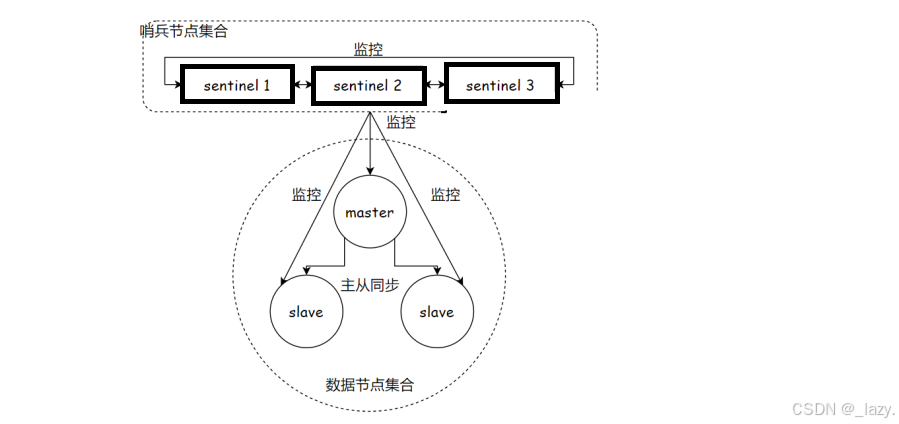
我们现在假定有三个节点,分别一个主节点两个从节点,并且我们引入了三个哨兵,而因为哨兵本质上是一种轻量级服务,所以同时监测多个Redis服务器是完全可以的。
并且我们要清楚,哨兵检测的机制是通过与redis-server建立tcp长连接,定时发送心跳包,如果超过既定的时间没有收到PONG,也就代表了机器挂了。
那么我们就基于主从复制+哨兵机制的情况下,简单概述一下主节点挂了的情况下,整个体系是如何运作的。
首先,某个节点挂了,那么哨兵会判断是主节点还是从节点,如果是从节点,那么哨兵的一致想法都是:哦。
其次,如果是主节点挂了,那么首先监测到的哨兵会给该节点标志位s_down(主观下线),如果多个哨兵节点都认为它下线了,那么它的标志就会变成o_down(客观下线)。
然后,已经确定主节点已经挂了的情况下,会从多个哨兵节点里面选取一个leader,让这个leader在剩余的节点里面选取一个主节点,选取成功之后,就会开始控制被选中的节点,通过slaveof命令等,修改主节点的配置和从节点的配置。
最后,哨兵会自动通知客户端程序,告诉新的主节点是谁,从而完成数据同步工作。
我们现在可以得出结论,哨兵的作用就是:监控,故障转移,通知。那么哨兵只有一个的话,也是可以的,但是误判的概率就比较高了,这个点涉及到s_down和o_down,后面细说,并且误判也会存在一种情况就是因为网络波动,毕竟网络波动导致了丢包或者抖动,刚好哨兵就收不到对应的PONG,也就误判了。而哨兵的个数,也应该是奇数个,这个点我们到后面的票数再细说。
以上就是引入哨兵机制后,简单的一个恢复流程,那么里面还有更多的细节,我们先不着急。我们现在思考如何进行对应的模拟?
模拟哨兵机制
咱们这里为什么要叫哨兵模拟机制呢?因为我们现在是没有办法真正演示哨兵机制的,你想,哨兵是一个单独的程序,并且在一个单独的服务器上,先不谈我们只有一台云服务器,我们光是节点就需要6个,那么我们好像是要需要6个服务器?
那么好,如果你说咱就是去买6个服务器,我们的电脑也不一定能够承受的了6个服务器,即便是六个轻量级的云服务器。所以我们需要一种技术让我们的云服务器上能运行3个节点3个哨兵。毕竟对于大多数的轻量级配置(2核4G)还是难以直接操作这么多服务,毕竟我们如果直接配置,我们还需要小心的避开依赖的端口号,依赖的配置文件和依赖的数据文件,就非常繁琐了。
这里就需要用到了docker技术了,docker就能完美解决以上的问题。
Docker 通过资源隔离、轻量虚拟化、配置自动化等手段,让你在有限资源的机器上运行多个服务变得可控、高效且易管理。docke中引入容器和镜像的概念,对于容器来说,我们可以理解它把实例化的内容放在了容器里面,具有隔离性,不会干扰彼此,所以我们就能躲开冲突的资源分配的问题了。Docker 使用的是宿主机内核,不会像虚拟机那样消耗额外内存和 CPU 核心。
对于容器和镜像来说,我们可以理解是进程和可执行程序之间的关系,我们通过镜像,启动了多个容器,每个容器相当于一个进程,互不打扰,我们通过对应的配置文件就可以达到我们想要的效果。
我们现在就需要配置docker的环境了。
配置docker环境
对于云服务器来说,有的云服务器是默认安装了docker镜像的,具体我们可以使用docker --version查看一下:
有了docker之后,我们安装docker-compose,这两个的关系如图:
| 项目 | Docker | Docker Compose |
|---|---|---|
| 作用 | 管理单个容器 | 管理多个容器组成的服务 |
| 配置方式 | 命令行为主 | 配置文件(YAML) |
| 适用场景 | 启动一个测试 Redis、Nginx | 启动一个完整的集群、项目或环境 |
| 使用方式 | docker run, docker build |
docker-compose up, docker-compose down |
| 依赖 | 独立运行 | 基于 Docker CLI 运行(必须装了 Docker) |
相当于Docker是一个造船厂,docker compose是造船图纸,docker通过compose来管理这么多容器。
安装docker-compose也非常简单,直接apt install docker-compose -y 即可:
不过我这里已经安装好了。
然后我们需要停止一下之前的Redis服务,因为当我们使用docker的时候,启动对应的Redis镜像,默认的端口号都是6379,不停止redis服务就启动docker的话,会存在端口冲突问题,导致docker启动不了。
这里我们推荐的做法是不再使用Redis服务,就使用docker服务即可。(推荐)
sudo systemctl stop redis
或者
sudo service redis-server stop
我们可以通过这两个方式停止Redis的服务,记住不能使用kil -9哦。
然后我们需要使用docker获取到redis的镜像 ,毕竟没有可执行程序我们也就没有办法启动进程了。对应的命令是docker pull redis:7.2 ,也可以是docker pull redis:5.0.9,5.0.9的版本较老但是非常稳定,7.2的版本是最新的稳定版,体验相对好一点,其实我们都感觉不出来所以随便选一个了。
不过这里我们会面临一个问题就是被墙,这是国内服务器(像腾讯云、阿里云、华为云)常见的现象 ,因为访问 Docker Hub 会被墙或受限,导致连接慢、超时、甚至失败。报错信息常见为:
此时我们需要在etc的docker目录下创建一个daemon.json配置文件,根据自己的云服务器添加相关配置文件,然后systemctl daemon-reexec再sudo systemctl restart docker重启一下docker服务即可,对于腾讯云的配置文件是这样的:
{
"registry-mirrors": [
"https://mirror.ccs.tencentyun.com"
]
}此时我们拉取对应的镜像就没有问题了。可以使用docker images 查看对应的镜像仓库
具体的信息我们到时候更新docker会着重介绍。这里我们先看着玩即可。
基于docker环境搭建哨兵环境
现在我们已经有了对应的docker环境和对应的Redis镜像了。那么我们前文介绍到了docker-compose是启动对应实例的利器,并且我们是通过配置文件的方式启动对应的实例,那么实例的相关配置也是在对应的配置文件里写了。
问题来了,我们常见的配置文件有conf,json,xml,但是这里的配置文件可不是这里面的了,docker-compose的配置文件的格式是yml。
对比三种配置文件
我们这里简单对比一下json,xml,yml三种配置文件。
其中最为繁琐的配置文件当属xml文件了,以下是一个示例:
XML
<services>
<redis>
<image>redis:7.2</image>
<container_name>redis-master</container_name>
<ports>
<port>6379:6379</port>
</ports>
<volumes>
<volume>./data:/data</volume>
</volumes>
<command>redis-server --appendonly yes</command>
</redis>
</services>这是XML文件的redis配置文件。
XML
{
"services": {
"redis": {
"image": "redis:7.2",
"container_name": "redis-master",
"ports": ["6379:6379"],
"volumes": ["./data:/data"],
"command": "redis-server --appendonly yes"
}
}
}这是json的配置文件。
XML
services:
redis:
image: redis:7.2
container_name: redis-master
ports:
- "6379:6379"
volumes:
- ./data:/data
command: redis-server --appendonly yes这是yml文件的配置文件。
我们光从第一印象就能发现json文件和yml文件比xml文件简洁太多了,对于xml文件来说,它敲起来可真的太繁琐了。
那么对于json文件来说,它主要是通过花括号来表现配置的,对于yml文件来说它主要是通过缩进来表现配置的,那么在江湖上总有人戏称yml文件是游标卡尺,因为内容一多,真就得拿个游标卡尺去比对一下了。
那么不同的配置文件有不同的优势,我们这里主要是做一个了解。有了对文件的基本了解之后,就可以开始编排主从节点和哨兵了。
编排主从节点和sentinel
主从节点
首先编写主从节点的配置文件:
在家目录下创建一个redis的目录,然后创建一个docker-compose.yml配置文件,使用vim编辑,复制这么一段配置:
XML
version: '3'
services:
redis-master:
image: redis:7.2
container_name: redis-master
ports:
- "6379:6379"
command: ["redis-server", "--appendonly", "yes"]
redis-slave1:
image: redis:7.2
container_name: redis-slave1
ports:
- "6380:6379"
command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]
redis-slave2:
image: redis:7.2
container_name: redis-slave2
ports:
- "6381:6379"
command: ["redis-server", "--appendonly", "yes", "--slaveof", "redis-master", "6379"]我们从截取一段来看,image代表的是镜像的版本,container_name代表的是容器名字,ports有两个,6380:6379,6380代表的是宿主机的端口号,我们可以通过映射出来的6380端口号访问这个容器,6379代表的是这个容器里面的redis分配的端口号,默认都是6379。然后是网络,启动的命令是和我们之前的通过命令行方式启动服务的时候非常相似了,指定主节点。
而这里同学们大概率会有疑问了,我们之前指定主节点的时候,都是通过的slaveof hostip hostport指定的,那么这里的话,docker有自己的一套域名解析方法,可以根据对应的名字给到对应的ip。所以我们可以直接指定名字。
此时我们主从节点的配置有了,我们就可以通过命令docker-compose up -d 全部启动了:
d代表的是我们让容器在后台运行,不然就会一直在前台打印对应的信息了。
我们也可以通过docker-compose log 查看一下运行日志:
这是一部分,有很多的。
然后我们就可以验证一下是否启动成功了: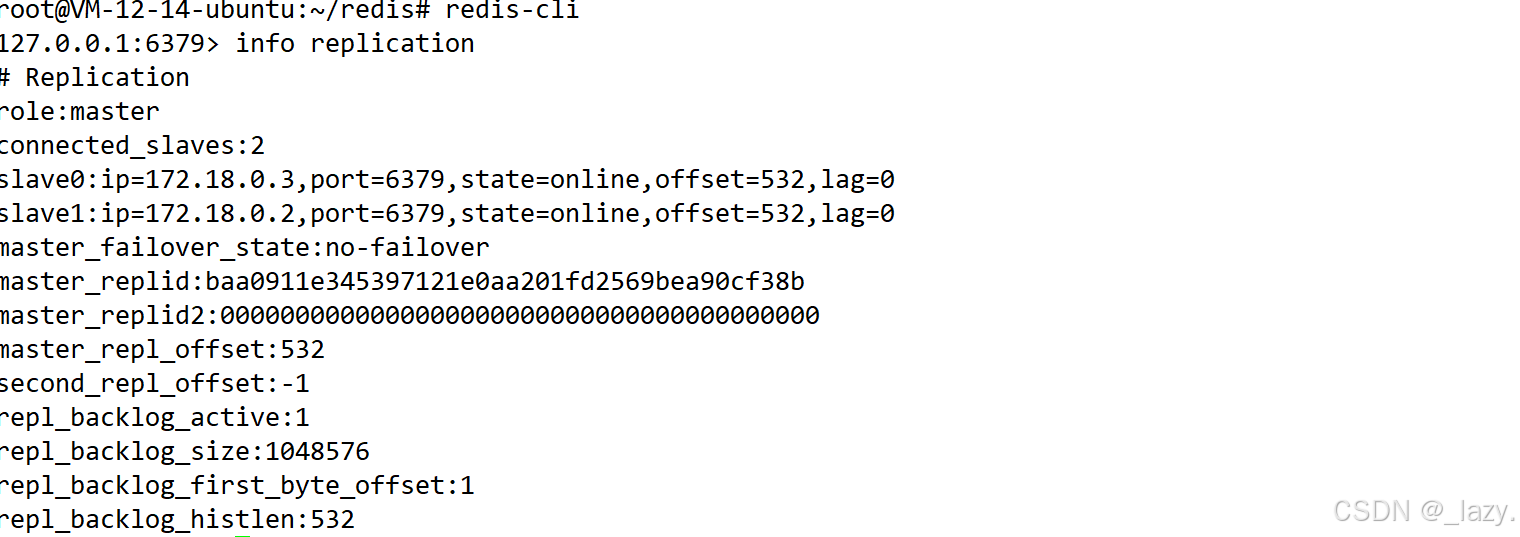
从节点这里就不验证了,是同样的操作。
sentinel
我们同样先创建一个和redis同级的目录redis-sentinel:
然后在这里面配置:
XML
version: '3'
services:
sentinel1:
image: 'redis:7.2'
container_name: redis-sentinel-1
restart: always
command: ["redis-sentinel", "/etc/redis/sentinel.conf"]
# command: ["/bin/sh", "/wait.sh"]
volumes:
- ./filesentinel1:/etc/redis
# - ./sentinel1.conf:/etc/redis/sentinel.conf
#- ./wait.sh:/wait.sh
ports:
- "26379:26379"
networks:
- default
sentinel2:
image: 'redis:7.2'
container_name: redis-sentinel-2
restart: always
command: ["redis-sentinel", "/etc/redis/sentinel.conf"]
volumes:
- ./filesentinel2:/etc/redis
#- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- "26380:26379"
sentinel3:
image: 'redis:7.2'
container_name: redis-sentinel-3
restart: always
command: ["redis-sentinel", "/etc/redis/sentinel.conf"]
volumes:
- ./filesentinel3:/etc/redis
# - ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- "26381:26379"
networks:
default:
external:
name: redis_default不过对于哨兵来说配置文件是不能使用同一份的,因为哨兵在运行的时候会对各自的配置文件进行修改,所以需要多份配置文件。
XML
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000哨兵的配置文件如上。
对于配置文件来说,第一行代表可以访问任意的ip,对于第二行来说代表的是端口号,sentinel默认的端口号就是26379,第三行代表的是法定票数,为2,和推荐哨兵个数为奇数有关。然后就是心跳包的截止时间了,1000ms代表的是如果1s内没有收到PONG,就认为机器挂了。
那么在这里我们着重解释一下command部分和volumes部分: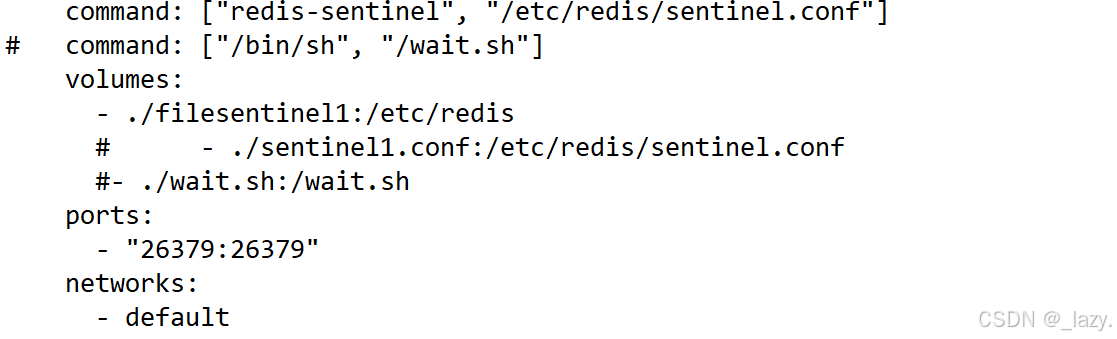
对于command部分,就是容器启动的时候,要去/etc/redis/的这个目录里面找sentinel.conf文件,而我们在volumes部分,将/etc/redis目录映射为了宿主机的./filesentinel1,即我们让它在这个目录里面找sentinel.conf文件。
那么我们的理念就是,不管怎么样,只要能让它在宿主机里面找到sentinel.conf文件就行,那么我们也可以把sentinel.conf改为sentinel1.conf或者sentinel2.conf,只要能让它在我们映射的部分找到就可以了。
所以我们也可以把三份配置文件放在一个目录下,然后对command来说,路径最后的配置文件更改为对应的配置文件名就可以了,只要能找到就可以了。
此时我们的配置就全部完成了!
然后我们尝试启动一下,启动之后我们使用docker-compose logs查看:
这个的原因是因为哨兵节点不认识redis节点,原因是因为网络:
首先我们要清楚,docker-compose一下启动了N个容器,那么N个容器就处在一个局域网里面,而我们再启动其他的容器,就是另一个局域网了,默认这两个局域网是不互通的。
但是这里,我们有的时候会面临一个非常痛苦的问题,即我们明明配置成功了,但是不管如何sentinel和redis节点都没有共享一个网络,笔者在这里碰到的原因是因为:sentinel启动的时候DNS没有准备好,导致DNS解析失败。
面对这个问题我们又两种方法,一种是直接使用ip,让sentinel不进行DNS解析的工作的,一种是使用脚本,当sentinel启动的时候检测DNS是否启动,如果启动了再进行DNS的解析工作。
脚本如下:
bash
#!/bin/sh
echo "waiting...."
until ping -c1 redis-master >/dev/null 2>&1; do
sleep 1
done
echo 'starting...'
exec redis-server /etc/redis/sentinel.conf --sentinel
如果我们不想使用DNS解析,我们可以使用上图的方式,直接使用对应的ip地址即可。我们可以使用这个命令查看与redis-master相关的网络信息,这里我们就可以看到不同节点的ip地址了。

那么现在,我们就能通过docker-compose logs查看到哨兵节点确实是正在监测对应的节点。
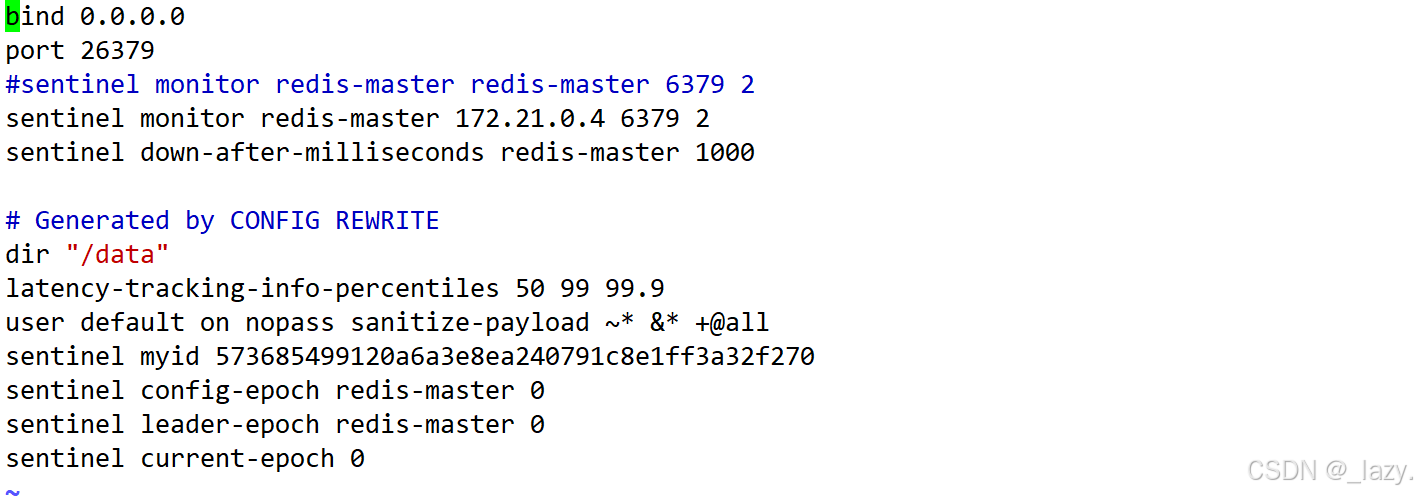
我们也确实看到了对应的文件发生了修改。
不过当我们启动节点时候,推荐的是先启动主从节点,然后再启动哨兵节点,如果先
模拟哨兵
现在我们就简单模拟一下主节点挂了的场景。
目前全部正常运行,然后我们挂了主节点。
//TODO
那么我们现在看到了具体的一个投票过程,其中我们也看到了s_down和o_down,其中s_down代表的是主观下线,也就是哨兵节点主观认为这个节点挂了,那么当其他哨兵认为这个节点下线的时候,就会触发o_down,即多个哨兵同时认为是它下线了。
为什么分为s_down和o_down?
因为哨兵如果因为网络抖动等问题收不到PONG是比较常见的事,所以我们就需要让多个哨兵同时确定。
对于投票过程来说,先是选出了对应的leader,然后是通过三个方面选取对应的主节点,分别是优先级,offset,runid。
其中对于优先级来说是影响最大的,在启动节点的时候会有相关的字段描述它的优先级,在它对应的配置文件里。但是默认的优先级都是一样的,如果我们不修改的话,优先级是一样的,即难以分出胜负,所以我们需要用到offset,我们可以根据从节点和主节点的offset对比,看谁的进度更加贴合于主节点,谁更贴合谁就当主节点,如果offset都一样了。就要用到runid了,这个runid我们在主从复制的部分提到过,我们当时说的就是在哨兵里面会用到,它其实是一个随机数,大小全看天命,到时候就通过runid来选取即可,单纯是比大小。
我们现在简单展开一下哨兵节点是奇数个的原因,你也看到了,有投票,如果投票是大于了哨兵个数的一半,那么它就是leader,那么,如果哨兵个数是偶数的话,出现了对半开的情况岂不是很尴尬?所以我们非常建议哨兵的个数是奇数个。
并且我们发现,redis-master重启之后,它变成了slave节点。
以上就是哨兵机制的全部内容~
感谢阅读!