Spark-Streaming概述
Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,以及和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。
1.DStream的概念
和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流作为抽象表示,叫作 DStream。
所以简单来将,DStream 就是对 RDD 在实时数据处理场景的一种封装。

Spark-Streaming的特点:易用、容错、易整合到spark体系。
1)易用性:Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序
2)容错:Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。
3)易整合:Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
Spark-Streaming架构
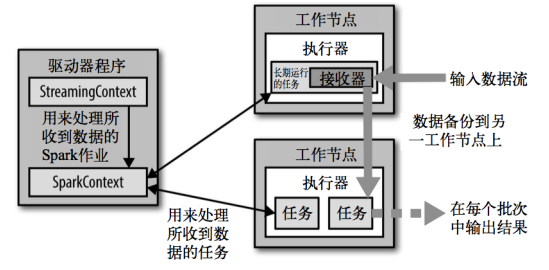
Spark-Streaming架构图:
背压机制:
在Spark 1.5 以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数"spark.streaming.receiver.maxRate"的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer 数据生产高于 maxRate,当前集群处理能力也高于 maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即 Spark Streaming Backpressure): 根据JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。通过属性"spark.streaming.backpressure.enabled"来控制是否启用 backpressure 机制,默认值为false,即不启用。
DStream实操
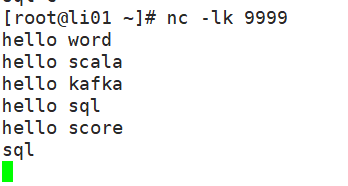
案例一:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数
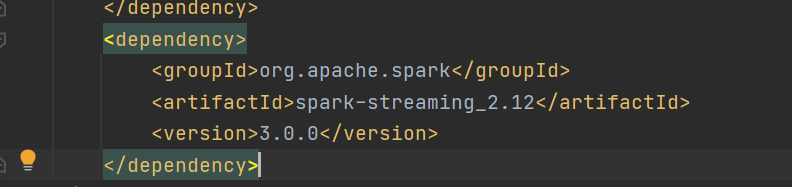
1. 添加依赖
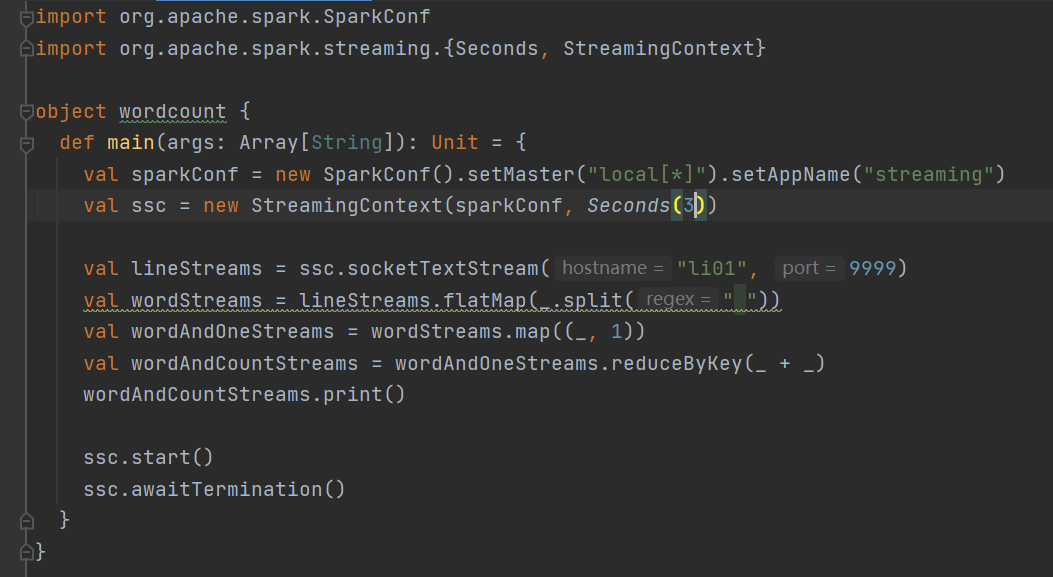
2 代码如下
3 启动netcat发送数据 ,运行代码可以得到不同单词出现的次数
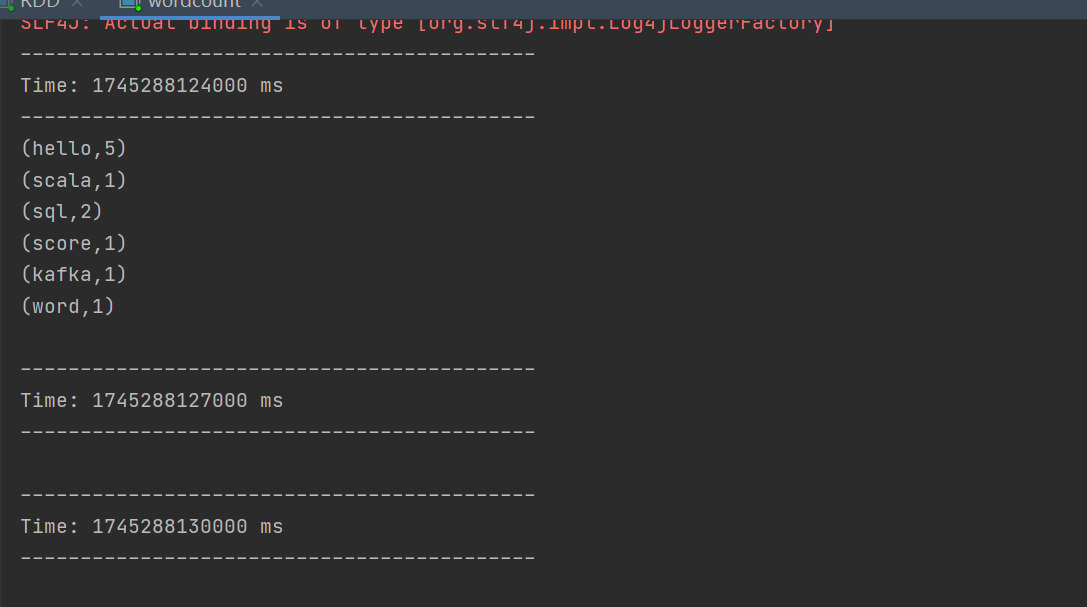
DStream 创建
创建DStream的三种方式:RDD队列、自定义数据源、kafka数据源
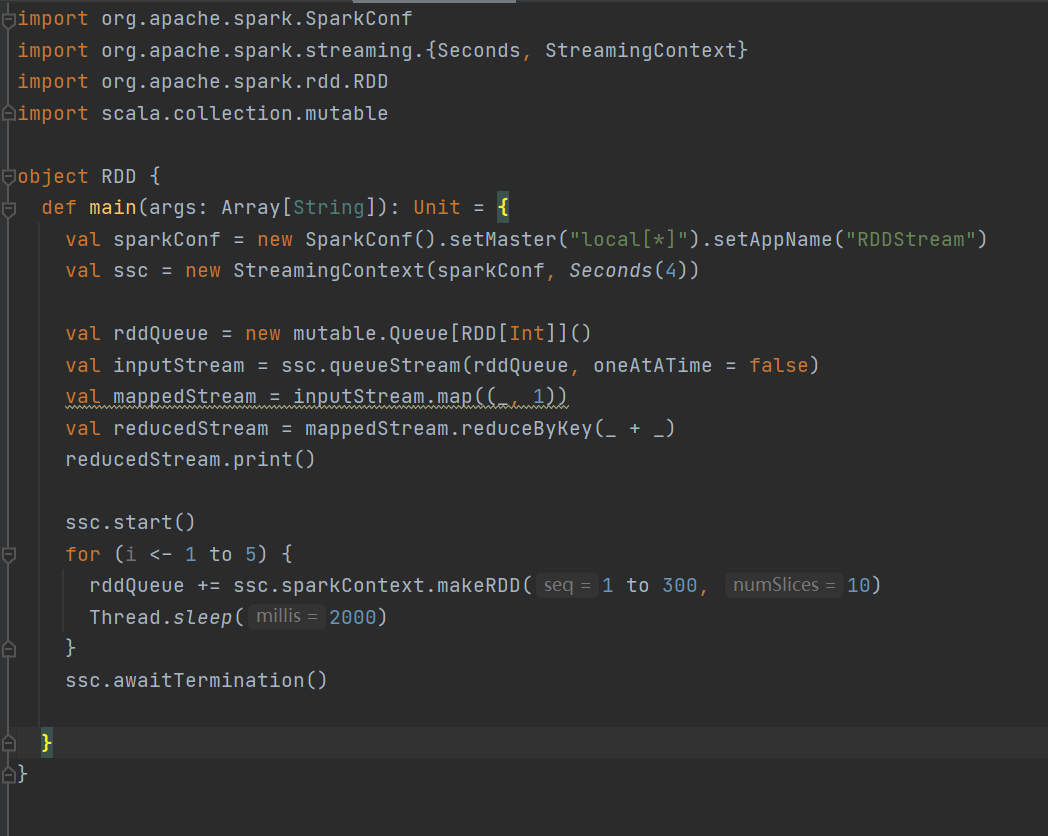
方式一:RDD队列
**任务需求:**循环创建几个 RDD,将 RDD 放入队列。通过 SparkStream 创建 Dstream,计算 WordCount
案例演示
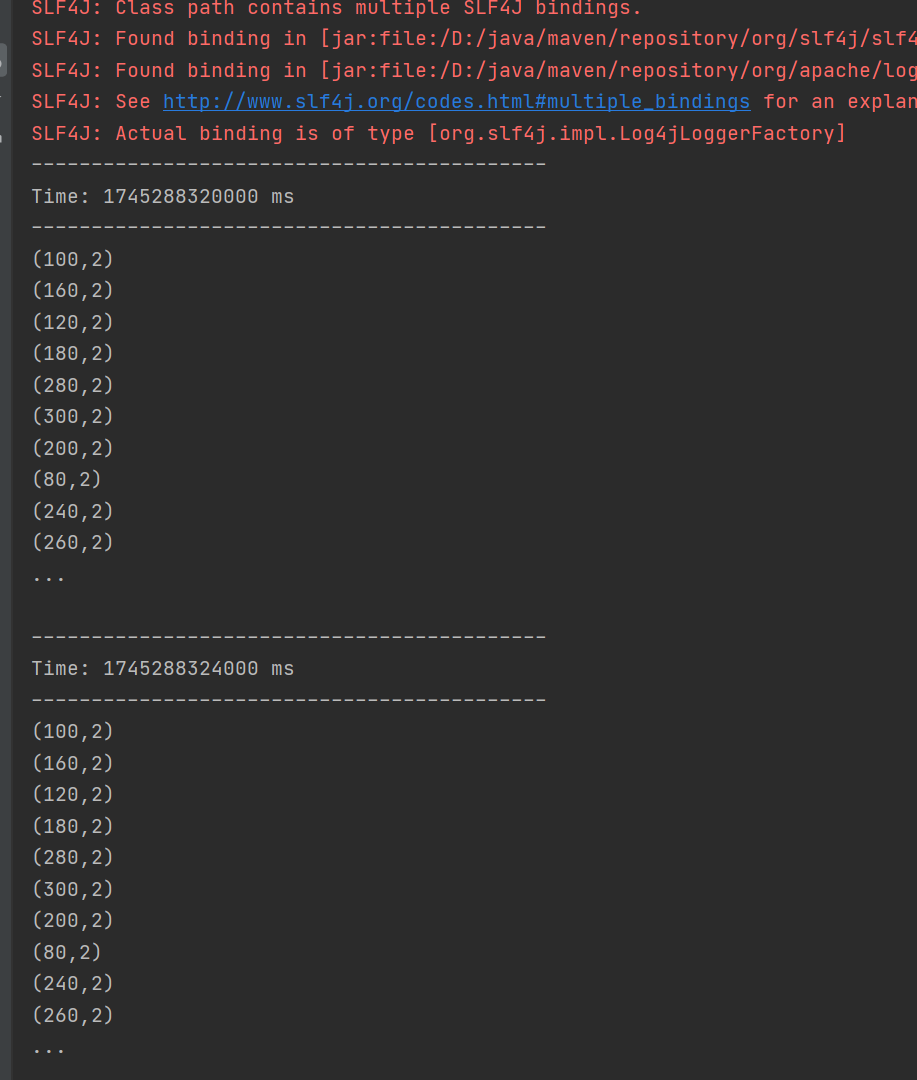
运行结果
方式二:自定义数据源
**定义:**自定义数据源需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
**任务需求:**自定义数据源,实现监控某个端口号,获取该端口号内容。
案例演示
- 自定义数据源
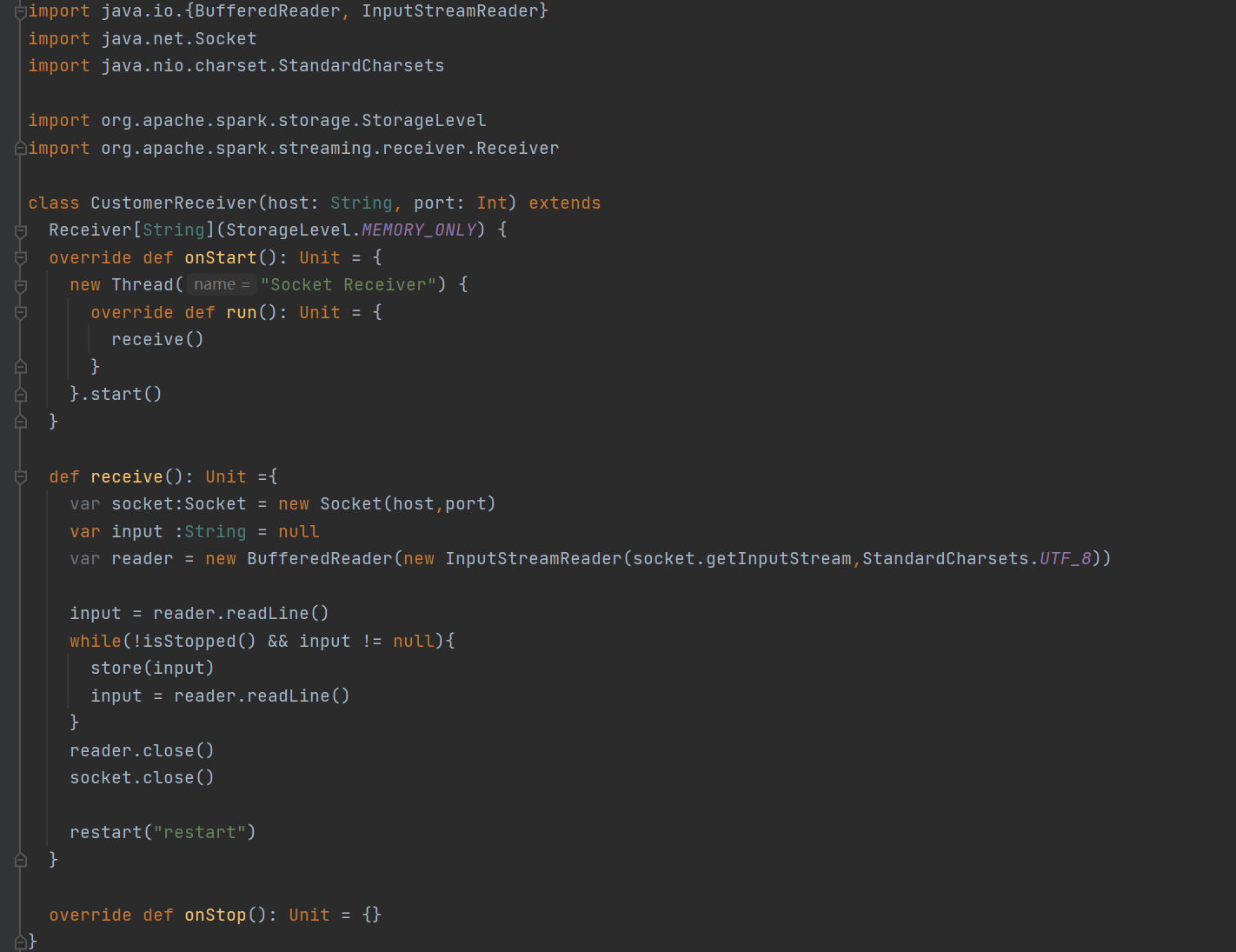
- 使用自定义的数据源采集数据
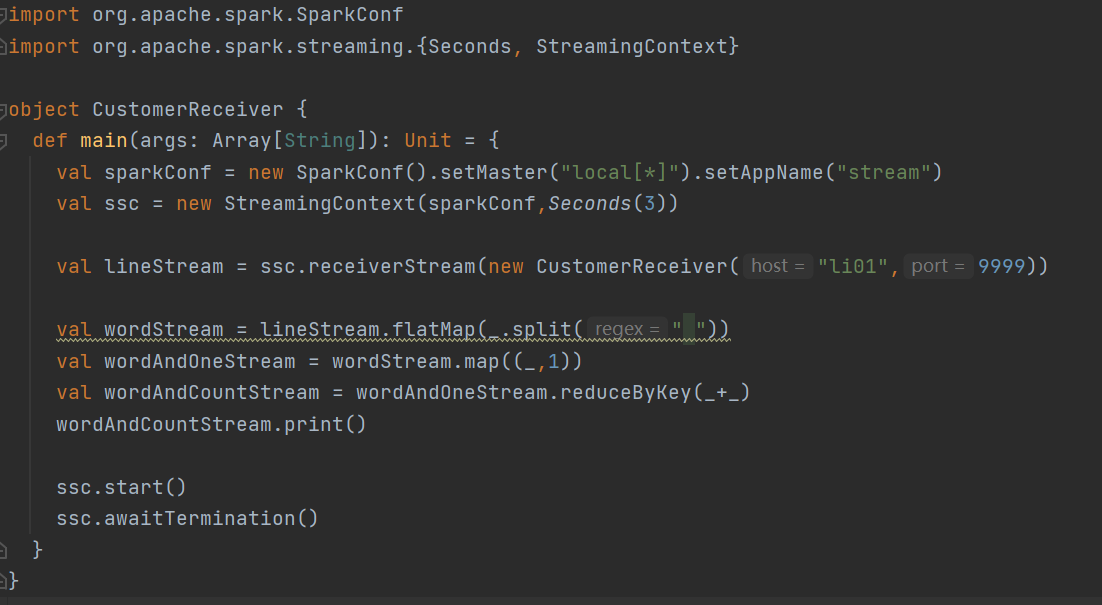
3 往端口传输数据
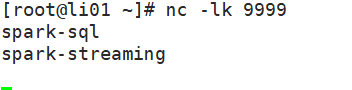
运行结果