为什么搭建一个 MCP 服务器?
MCP 允许您以统一的方式访问和"插件化"外部工具和资源到 LLMs,这或许可以通过注册在 mcp.so 上的成千上万的服务器得到最佳体现。
尽管开箱即用的 MCP 服务器具有高可用性,但自己搭建 MCP 服务器仍然是一个关键技能,因为你可能会遇到需要自定义服务器的特殊工作流程。
说到这,本教程将构建一个使用 Python 和 FastMCP(Python 中构建 MCP 的首选库)读取文档/PDF 的简单 MCP 服务器。到此为止,您将获得构建、测试和部署您自己的 MCP 服务器的基础知识和更广泛的理解,以增强您特定用例中 AI 的能力和实用性。
如何使用现有的 MCP 服务器与 Cursor 或 Claude Desktop
对于 MCP 服务器的新手来说,让我们快速了解一下如何使用现有的服务器,然后再构建一个自定义的服务器。
好吧,首先,你需要一个 MCP 主机应用程序,比如 Claude Desktop,或者任何其他每周出现的基于 AI 的 IDE。我更喜欢 Cursor,因为它是最快速成长且频繁更新的 IDE 之一。
步骤 1: 安装 Node.js 和 UV Python
选择您的主机后,您必须在机器上安装 Node.js 和 UV Python 包管理器,因为这两种方式是 MCP 服务器的主要安装方式。以下是安装说明:
- 安装 Node.js(包括 npm/npx)
macOS:
bash
# Using Homebrew
brew install node
# Or download installer from https://nodejs.org/Windows:
bash
# Download installer from https://nodejs.org/
# Or using winget
winget install OpenJS.NodeJS- 安装 UV Python
macOS:
bash
# Using curl
curl -sSf https://install.python-uv.org | bash
# Or using Homebrew
brew install uvWindows:
vbnet
# Using PowerShell (run as Administrator)
powershell -c "irm https://install.python-uv.org | iex"
# Or using pip
pip install uv使用 node --version、npx --version 和 uv --version 验证安装。
第2步:选择一个可以立即开始使用的服务器
你可以访问各种资源来找到适合你需求的服务器,包括 mcp.so,"Awesome MCP 服务器"GitHub 仓库,或我们最近的文章,其中挑选了社区中最好的 15 个开放 MCP 服务器。
在这里,我们演示如何将 Firecrawl MCP 添加到 Cursor 中,这使得你的 IDE 可以直接在聊天线程中抓取网页、爬取整个网站,或基本上做任何 Firecrawl 提供的事情。
要开始,你需要从 Firecrawl 获取一个 API 密钥,它提供了慷慨的免费套餐。然后,在你的主目录中创建一个 ~/.cursor/mcp.json 文件,以便在 Cursor 工作区中提供 MCP 服务器:
bash
mkdir ~/.cursor
touch ~/.cursor/mcp.json然后,在 JSON 文件中添加以下内容:
json
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}之后,重启你的 IDE 应该会让服务器在 Cursor 设置中可见:
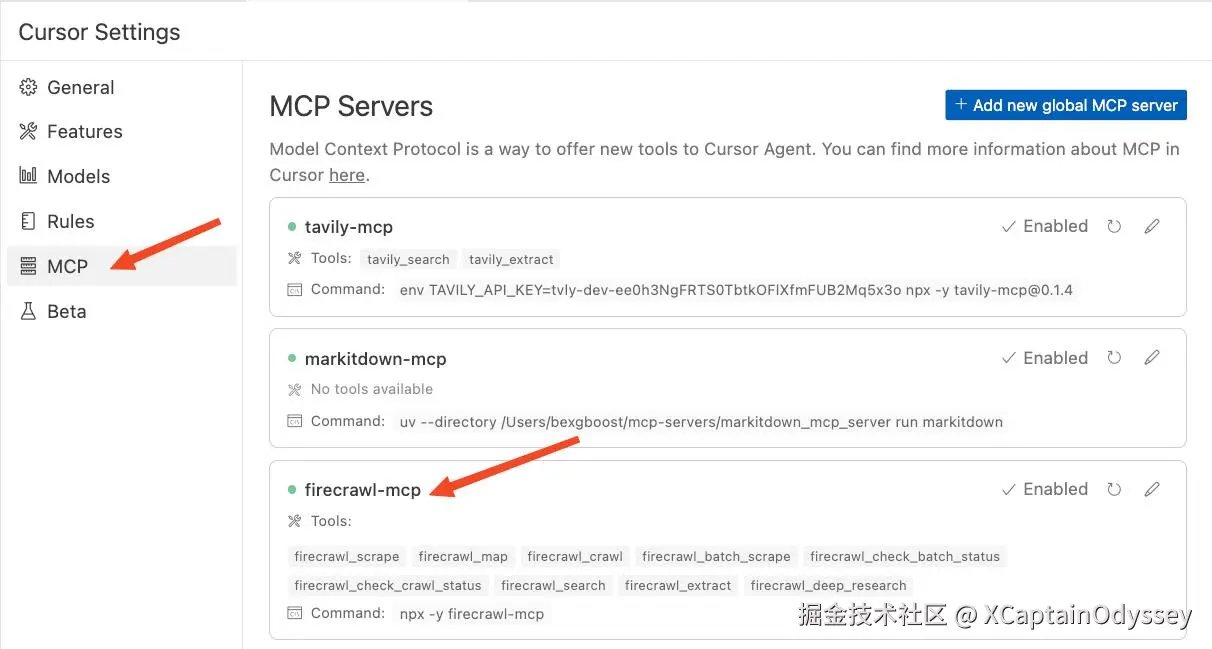
然后,尝试让 Cursor 爬取任何公开可访问的网页。例如,你可以让它爬取 GitHub 的热门仓库页面,MCP 服务器会自动确定需要爬取 https://github.com/trending 页面上的所有仓库。
使用 FastMCP 构建 MCP 服务器的逐步指南
自行构建 MCP 服务器为扩展 LLM 功能提供了无限可能,可以使用自定义工具、资源和提示。FastMCP 是创建 MCP 服务器推荐的 Python 库,提供了一个干净的、基于装饰器的 API,可以处理底层协议的复杂性。在本节中,我们将构建一个文档解析服务器,使 MCP 主机能够理解 PDF 和 DOCX 文件------这是大多数 AI 主机默认无法解析的文件格式。
为了探索我们即将构建的服务器的代码,您可以访问我们的 GitHub 仓库。
0. 安装 FastMCP
第一步是安装 MCP Python SDK。我们将使用 UV,这是一个比 pip 更快且依赖解析更好的现代 Python 包管理器:
csharp
uv add "mcp[cli]"[cli] 部分是可选的额外功能,包括命令行界面工具,如 MCP 检查器用于调试。使用 UV 的 add 命令可以自动将此包添加到您的环境中,而无需手动创建虚拟环境 - 它会在后台为您处理这些操作。
1. 定义工具、资源和提示
MCP 服务器由三个主要组件组成:
- 工具 : LLM 可以调用的执行操作的功能(模型控制)
- 资源 : 主应用程序可以提供给 LLM 的数据源(应用程序控制)
- 提示 : 用户可以通过 UI 元素调用的模板(用户控制)
首先,我们需要导入必要的模块并创建 FastMCP 实例:
javascript
from mcp.server.fastmcp import FastMCP
from mcp.server.fastmcp.prompts import baseFastMCP 是与 MCP 协议交互的高级接口。它负责连接管理、协议合规性以及代码与宿主应用程序之间的消息路由。
接下来,我们将初始化 FastMCP 实例:
ini
mcp = FastMCP("DocumentReader", dependencies=["markitdown[all]"])我们将服务器命名为"DocumentReader",并指定"markitdownall"作为依赖项。Markitdown 是一个轻量级的库,可以将各种文档格式转换为 markdown,这是 LLMs 的理想格式。
在深入实现之前,重要的是要规划我们的服务器将提供哪些功能。对于我们的文档阅读器,我们将定义:
less
@mcp.tool()
def read_pdf(file_path: str) -> str:
"""Read a PDF file and return the text."""
return "This is a test"
@mcp.tool()
def read_docx(file_path: str) -> str:
"""Read a DOCX file and return the text."""
return "This is a test"
@mcp.resource("file://resource-name")
def always_needed_pdf():
# Return the file path
return "This PDF file is always needed."
@mcp.prompt()
def debug_pdf_path(error: str) -> list[base.Message]:
return f"I am debugging this error: {error}"上述代码定义了我们的 MCP 服务器的结构,其中包含占位实现:
- 两个工具(
read_pdf和read_docx),用于从文档中提取文本 - 一个资源,可以提供访问经常需要的文档的访问权限
- 一个帮助调试 PDF 相关问题的提示
每个组件使用装饰器模式(@mcp.tool(),@mcp.resource(),@mcp.prompt())来将函数注册到 MCP 服务器。文档字符串至关重要,因为它们提供了描述,帮助 LLM 理解何时以及如何使用每个组件。
2. 将工具添加到服务器
现在我们已经了解了 MCP 服务器的结构,让我们使用实际的功能实现我们的文档读取工具:
python
from mcp.server.fastmcp import FastMCP
from mcp.server.fastmcp.prompts import base
from markitdown import MarkItDown
import os
mcp = FastMCP("DocumentReader", dependencies=["markitdown[all]"])
md = MarkItDown()
@mcp.tool(
annotations={
"title": "Read PDF Document",
"readOnlyHint": True,
"openWorldHint": False
}
)
def read_pdf(file_path: str) -> str:
"""Read a PDF file and return the text content.
Args:
file_path: Path to the PDF file to read
"""
try:
# Expand the tilde (if part of the path) to the home directory path
expanded_path = os.path.expanduser(file_path)
# Use markitdown to convert the PDF to text
return md.convert(expanded_path).text_content
except Exception as e:
# Return error message that the LLM can understand
return f"Error reading PDF: {str(e)}"
@mcp.tool(
annotations={
"title": "Read Word Document",
"readOnlyHint": True,
"openWorldHint": False
}
)
def read_docx(file_path: str) -> str:
"""Read a DOCX file and return the text content.
Args:
file_path: Path to the Word document to read
"""
try:
expanded_path = os.path.expanduser(file_path)
# Use markitdown to convert the DOCX to text
return md.convert(expanded_path).text_content
except Exception as e:
return f"Error reading DOCX: {str(e)}"@mcp.tool() 装饰器将每个函数注册为一个工具,LLM 可以调用这些工具。让我们看看关键组件:
-
工具注解 : 我们添加了注解来提供关于工具的元数据:
title: 在 UI 显示中该工具的人类可读名称readOnlyHint: 由于这些工具只读取文件而不进行任何修改,因此设置为True- openWorldHint: 设置为
False,因为这些工具处理的是本地文件,而不是外部系统
-
描述性文档字符串 : 文档字符串至关重要,它们帮助 LLM 理解何时以及如何使用该工具。在
Args:部分包含参数描述可以提供更多的上下文。 -
错误处理 : 我们将转换包裹在 try/except 块中,以捕获并以 LLM 可以理解的格式返回任何错误。这遵循了 MCP 工具规范的最佳实践。
-
路径处理 : 我们使用
os.path.expanduser()安全地展开文件路径中的任何波浪号字符,这对于支持类似于~/Documents/file.pdf的路径非常重要。 -
Markitdown 使用 :
MarkItDown库提供了一个简单的.convert()方法,可以处理各种文档格式并返回文本内容。.text_content属性可以给我们纯文本,方便传递给 LLM。
这些工具非常简单,但它们遵循一个你可以扩展以实现更复杂功能的模式。例如,你可以添加工具来:
- 从文档中提取特定部分
- 将文档转换为不同格式
- 在文档中搜索关键词
- 计算文档内容的统计数据
请记住,工具应该专注于执行单一明确的操作。这使得它们更容易被 LLM 理解和正确使用。
要了解 MCP 中工具的更多信息,请参阅官方文档。
将资源添加到服务器
在 MCP 中,资源允许服务器暴露静态或动态数据,这些数据可以被宿主应用程序访问。与由模型控制的工具不同,资源是由应用程序控制的,这意味着它们通常作为上下文提供给模型,而不是由模型直接调用。
让我们为我们的文档阅读器服务器实现一些资源:
python
# document_reader.py
@mcp.resource("file://document/pdf-example")
def provide_example_pdf():
"""Provide the content of an example PDF document.
This resource makes a sample PDF available to the model without requiring
the user to specify a path.
"""
try:
# Use an absolute path with the file:// schema
pdf_path = "file:///Users/bexgboost/Downloads/example.pdf"
# Convert the PDF to text using markitdown
return md.convert(pdf_path).text_content
except Exception as e:
return f"Error providing example PDF: {str(e)}"
@mcp.resource("file://document/recent/{filename}")
def provide_recent_document(filename: str):
"""Provide access to a recently used document.
This resource shows how to use path parameters to provide dynamic resources.
"""
try:
# Construct the path to the recent documents folder
recent_docs_folder = os.path.expanduser("~/Documents/Recent")
file_path = os.path.join(recent_docs_folder, filename)
# Validate the file exists
if not os.path.exists(file_path):
return f"File not found: {filename}"
# Convert to text using markitdown
return md.convert(file_path).text_content
except Exception as e:
return f"Error accessing document: {str(e)}"让我们来检查一下这些资源的关键组成部分:
-
资源 URI: MCP 中的资源通过类似于 URI 的路径来标识,带有特定的模式。在我们的示例中:
file://document/pdf-example是一个静态资源路径file://document/recent/{filename}使用路径参数来表示动态资源
-
路径参数 : 第二个资源展示了如何使用路径参数(用花括号包围)来创建动态资源。参数
{filename}作为参数传递给函数。 -
URI 模式 :
file://模式表示这些资源代表文件内容。其他常见的模式包括http://,data://,或与您的应用程序相关的自定义模式。 -
返回值 : 资源可以直接返回文本内容,这就是我们通过返回从文档中提取的文本来实现的方式。
-
错误处理 : 就像使用工具时一样,我们包含了适当的错误处理,以便在资源无法访问时提供有用的反馈。
资源不仅限于文件 - 数据库、API 和其他数据源也可以作为资源进行暴露。例如:
python
# A sample - don't add this to our MCP server
@mcp.resource("db://customer/{customer_id}")
def get_customer_record(customer_id: str):
"""Retrieve a customer record from the database."""
try:
# In a real application, you would query your database
connection = database.connect("customer_database")
result = connection.query(f"SELECT * FROM customers WHERE id = {customer_id}")
return json.dumps(result.to_dict())
except Exception as e:
return f"Error retrieving customer data: {str(e)}"
@mcp.resource("api://weather/current/{location}")
def get_current_weather(location: str):
"""Get current weather for a specific location."""
try:
# In a real application, you would call a weather API
response = requests.get(f"https://weather-api.example/current?location={location}")
return response.text
except Exception as e:
return f"Error retrieving weather data: {str(e)}"我们在这里定义的资源只是占位示例 - 在实际应用中,你可能会创建资源,这些资源:
- 提供用户历史中的最近文档
- 提供经常需要的参考材料访问权限
- 显示配置设置
- 与连接系统的信息共享
- 从数据库检索记录
- 从外部 API 获取实时数据
在设计资源 URI 时,重要的是创建一个逻辑的、分层的结构,使每个资源的目的清晰明了。路径应该表明该资源提供了什么类型的数据,以及它如何与其他系统中的资源相关联。
要了解 MCP 中的资源更多信息,请参阅官方文档。
4. 向服务器添加提示
在 MCP 中,提示允许您定义可重用的提示模板,这些模板可以在客户端应用程序中呈现给用户。与工具(模型控制)和资源(应用程序控制)不同,提示是用户控制的,用户可以通过明确提及它们在主机 UI 中明确选择它们。
让我们为我们的文档阅读器服务器实现一个提示:
python
from mcp.server.fastmcp.prompts import base
@mcp.prompt()
def debug_pdf_path(error: str) -> list[base.Message]:
"""Debug prompt for PDF issues.
This prompt helps diagnose issues when a PDF file cannot be read.
Args:
error: The error message encountered
"""
return [
base.Message(
role="user",
content=[
base.TextContent(
text=f"I'm trying to read a PDF file but encountered this error: {error}. "
f"How can I resolve this issue? Please provide step-by-step troubleshooting advice."
)
]
)
]让我们来了解一下这个提示实现中的关键组件:
-
提示定义 : 提示使用
@mcp.prompt()装饰器定义,该装饰器将其注册到 MCP 服务器。 -
函数参数 :
error参数成为用户在调用提示时可以提供的参数。参数可以是必需的或可选的(带有默认值)。 -
返回结构 : 提示返回一个
base.Message对象列表,这些对象代表要发送给 LLM 的对话。每个消息包含:角色(通常是"用户"或"助手")内容,包含一个或多个内容项(通常是TextContent)
-
文档字符串 :就像工具和资源一样,清晰的文档字符串有助于解释提示的目的并记录其参数。
这个提示会在客户端应用程序的用户界面中出现,使用户能够轻松获取与 PDF 相关的错误帮助。例如,当遇到读取文件的错误时,他们可以从 UI 中选择"调试 PDF 路径",并提供错误消息以获取故障排除建议。
在编写提示时,请记住它们旨在创建可重用的标准交互,使常见任务更容易完成。设计良好的提示可以显著提高 MCP 服务器的易用性,为用户完成特定目标提供清晰的路径。
要了解有关 MCP 中提示使用的更多信息,请参阅官方文档。
5. 调试 MCP 服务器
FastMCP 附带了一个内置的调试工具,称为 MCP Inspector,它提供了一个干净的 UI,用于测试您的服务器组件,而无需连接到 MCP 主机应用程序。此调试器在部署之前验证您的实现方面非常有价值。
要启动调试器,请使用 mcp dev 命令,后跟您的脚本名称:
mcp dev document_reader.py这将启动您的 MCP 服务器并在浏览器中打开 Inspector 界面。如果它没有自动打开,您通常可以通过 http://127.0.0.1:6274 访问它。
加载 Inspector 后,点击"连接"按钮以与您的服务器建立连接。界面将显示用于探索您的 MCP 服务器三大组件的选项卡:
- 工具 : 列出所有可用工具及其描述
- 资源 : 显示所有已注册的资源
- 提示 : 显示所有定义的提示
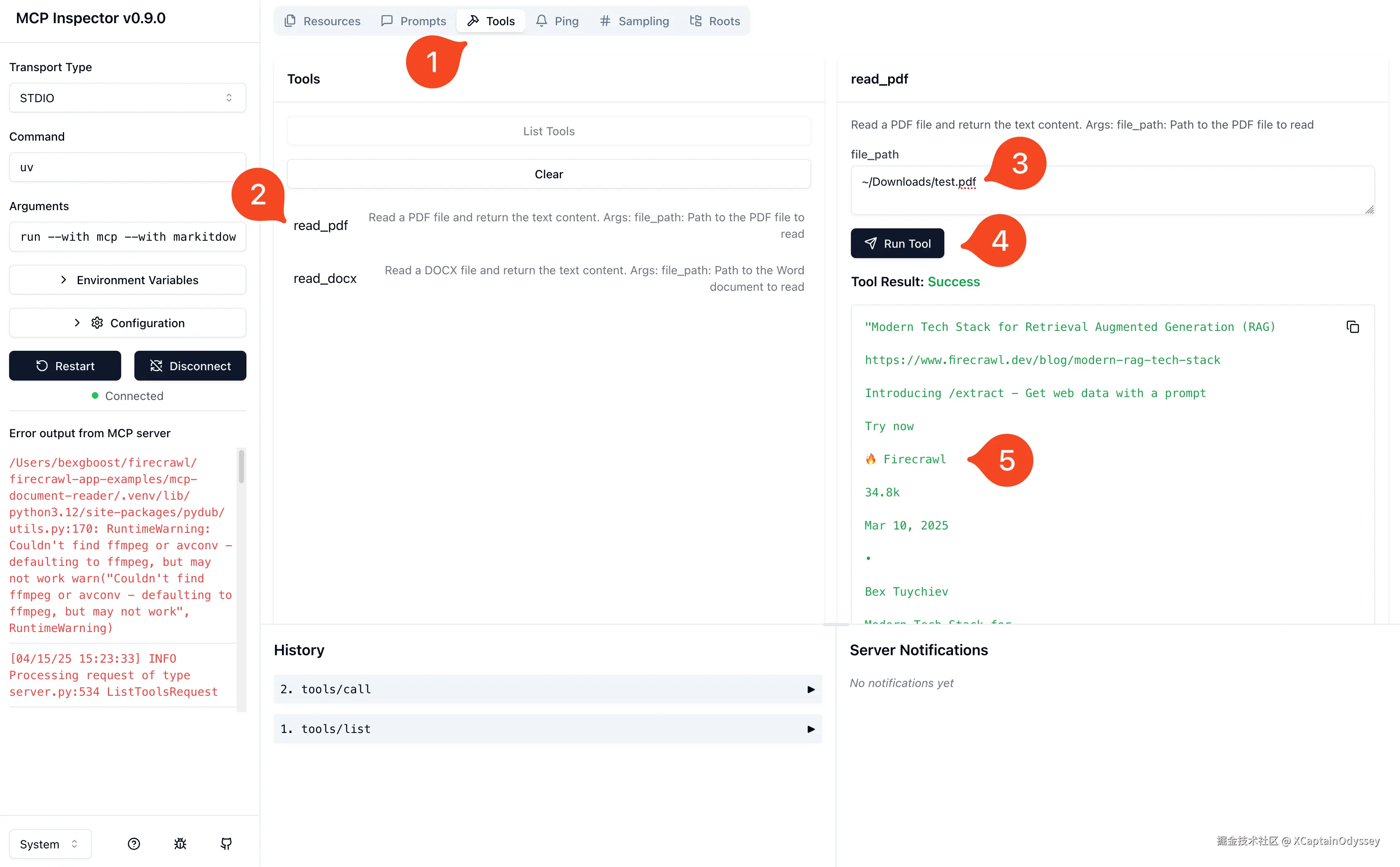
在工具选项卡中,您应该看到我们之前创建的两个工具:"读取 PDF 文档"和"读取 Word 文档"。您可以点击任何工具以查看其详细信息并提供参数进行测试。例如,点击 PDF 工具将显示一个文件路径的输入字段。在您的机器上输入一个 PDF 文件的完整路径,该工具将执行并显示提取的文本内容。
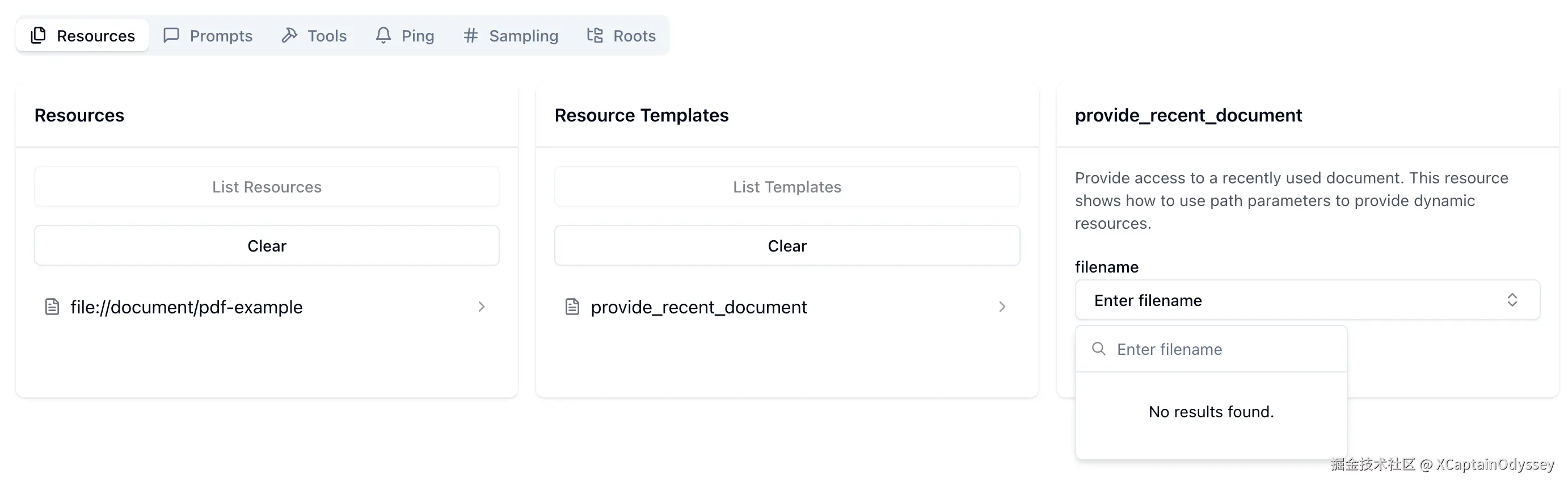
同样,在资源选项卡中,您可以测试您的资源,通过选择它们并提供任何所需的路径参数。对于我们的动态资源,带有 {filename} 参数,您将被提示输入一个文件名以测试该资源。
对于提示,检查员将显示一个表单,其中包含每个提示参数的字段。您可以填写这些字段以查看提示在发送给 LLM 之前将如何呈现。
检查员特别适用于:
- 验证参数处理 :确保您的工具、资源和提示能够正确处理不同的参数值,包括边界情况
- 测试错误处理 :故意提供无效输入以验证您的错误处理逻辑
- 检查内容格式 : 确保文本提取和格式化按预期工作
- 调试路径问题 : 在不同操作系统上解决文件路径处理问题
在实际工作流程中,一旦你使用检查器验证了你的 MCP 服务器,你就可以将其添加到像 Claude 桌面或 Cursor 这样的 MCP 主机中。然后,用户可以像"总结我位于~/Downloads/test.pdf 的 PDF 内容"这样的自然语言问题,LLM 会自动识别合适的工具,提取文件路径参数,并提供所需的信息。
有关 Inspector 和 MCP 调试技术的更多细节,您可以参考官方文档中的 MCP Inspector 页面和 调试指南。
6. 本地连接到 MCP 服务器
现在,真相时刻 - 使用主机应用程序本地测试我们的服务器。对于 Claude 桌面,设置非常简单。在你的服务器脚本所在的同一目录中,调用 mcp install 命令:
mcp install document_reader.py重启 Claude 桌面,服务器必须可见:
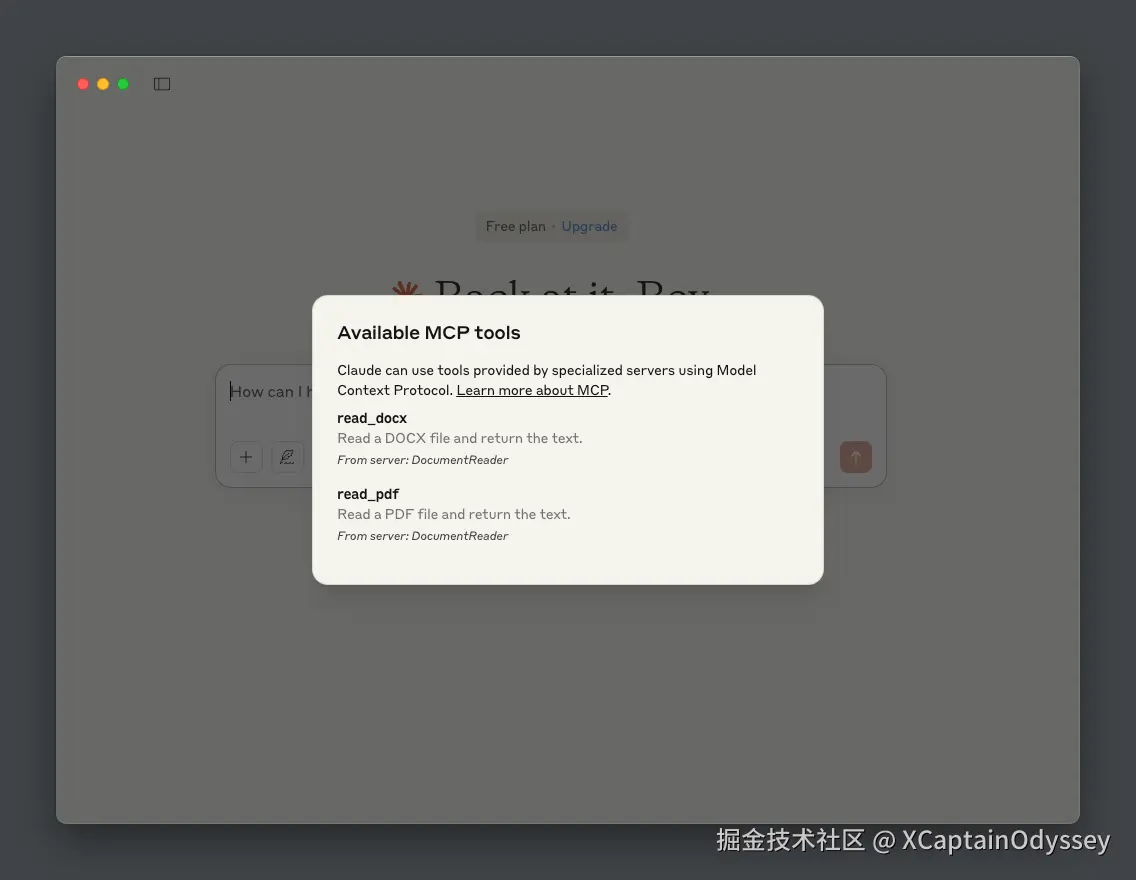
让我们让它总结我们的 Word 文档:
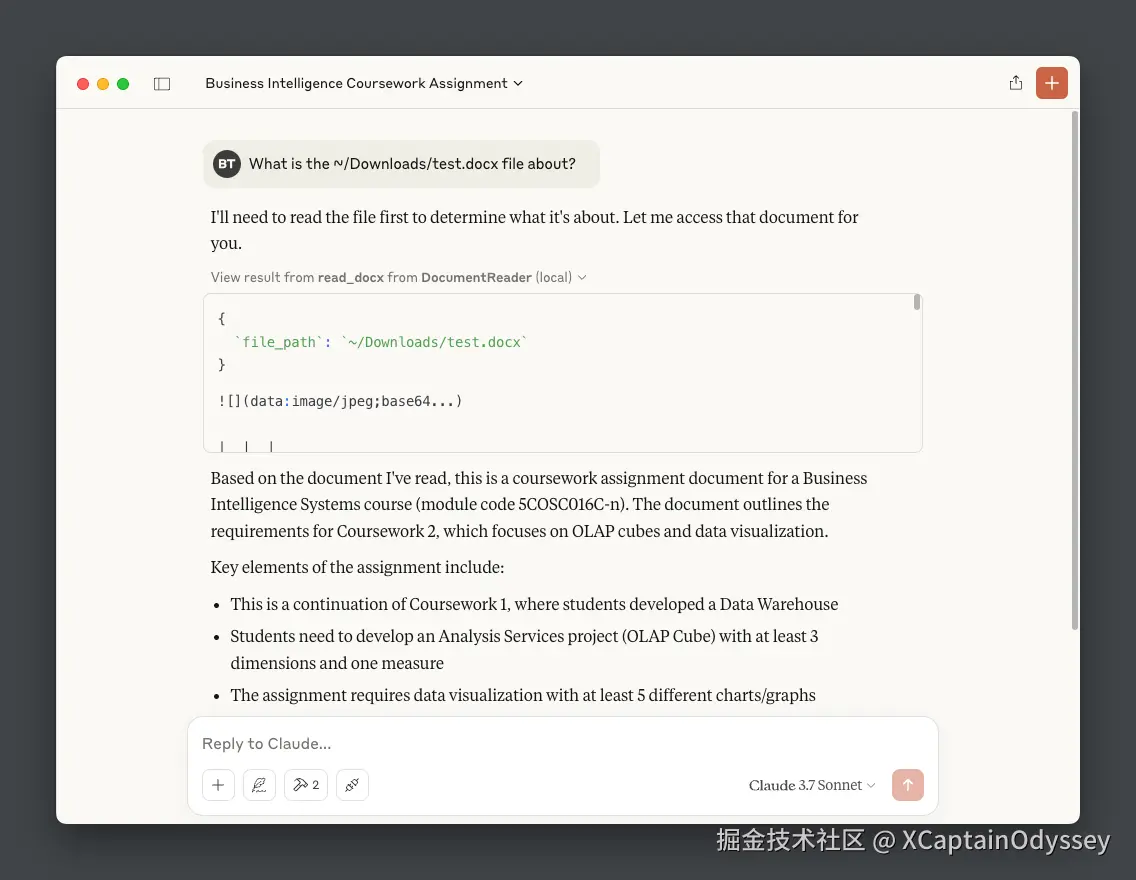
我们的服务器在 Claude 中已经完全运行。现在,让我们通过将以下 JSON 配置粘贴到 ~/.cursor/mcp.json 文件中将其添加到 Cursor 中:
json
{
"mcpServers": {
..., // Other servers
"document-reader-mcp": {
"command": "uv",
"args": [
"--directory",
"/path/to/server/directory",
"run",
"document_reader.py"
]
}
}
}之后重启 Cursor,服务器必须在你的设置中可见:
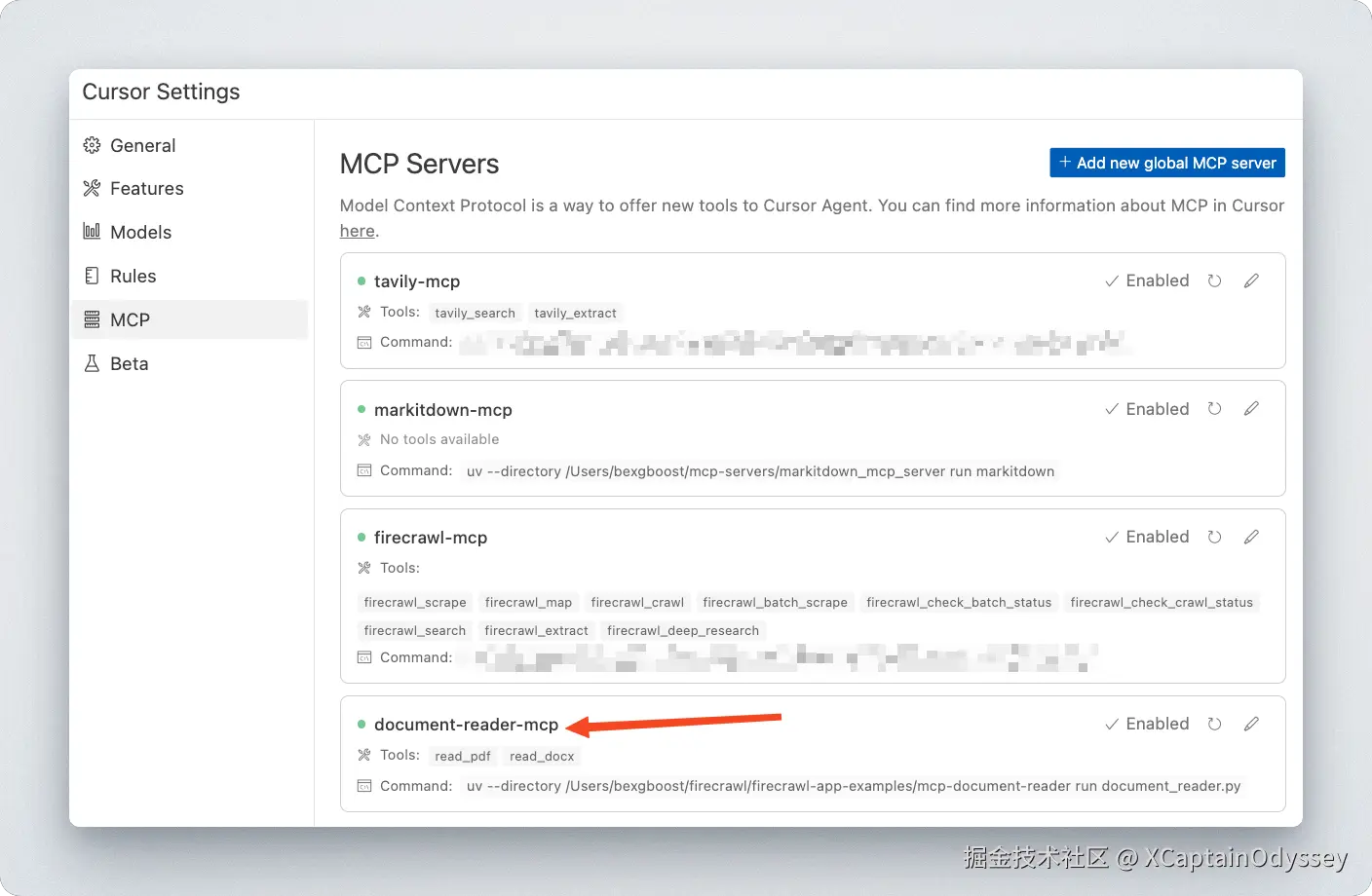
让我们在我当前目录中的一个 PDF 文档上进行测试:
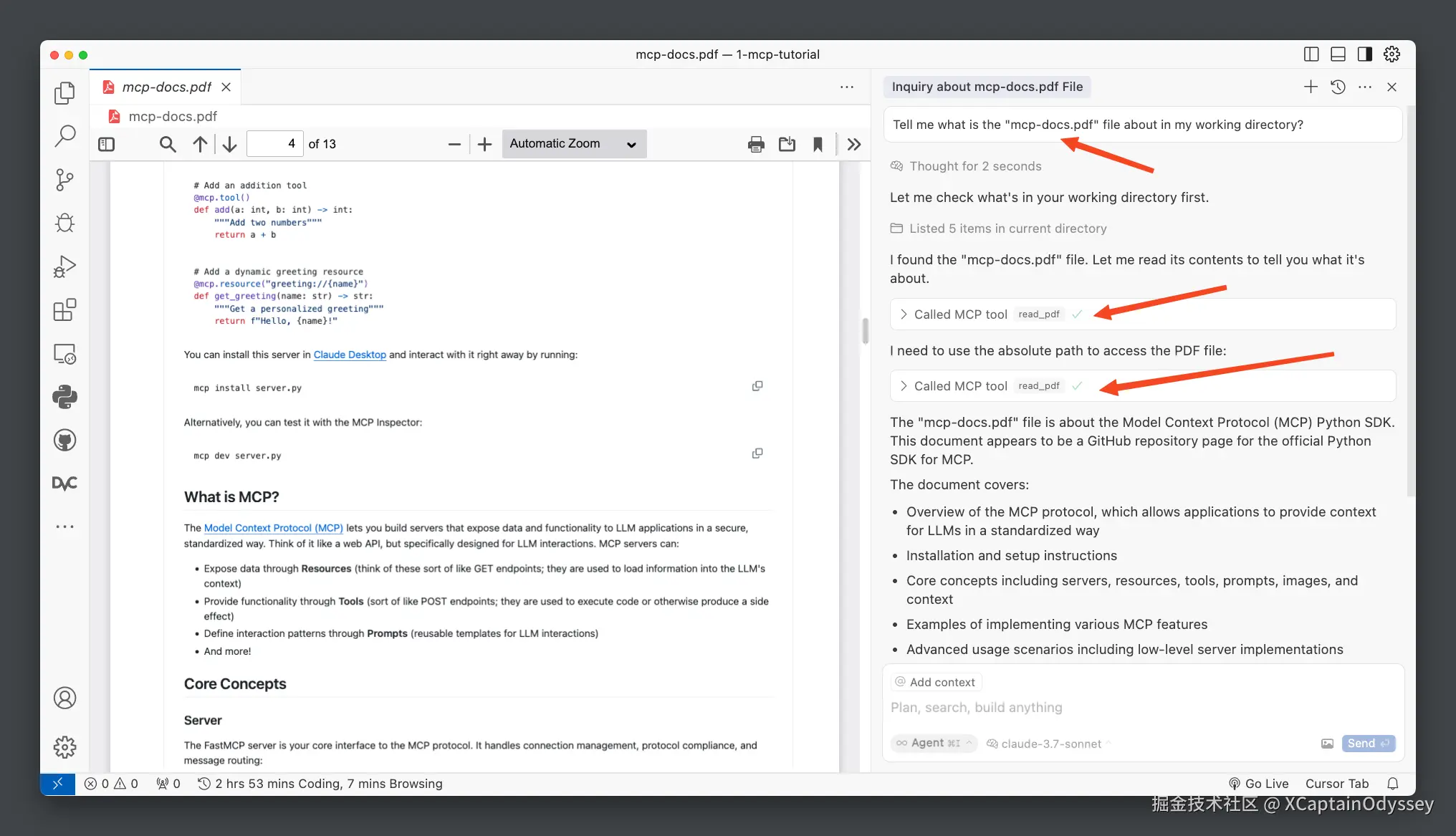
如你所见,我没有提供 PDF 文件的路径。在当前环境中,提示本身已经足够让 Cursor 确定需要使用完整路径,以便 MCP 工具能够正确运行。
如果你的服务器仅用于个人使用,那么我们的工作就完成了。然而,如果你想让它对外公开供外部用户使用,请继续阅读下一节。
7. 部署 MCP 服务器
在成功在本地构建并测试完 MCP 服务器后,下一步是将其部署以供更广泛的使用。MCP 服务器部署主要有两种主要方法:使用 stdio 传输的本地托管和使用 SSE 传输的远程托管。在本节中,我们将探讨如何通过 PyPI 分发我们的文档读取服务器。
将 MCP 服务器打包为 Python 包可以让其他人通过简单的命令轻松安装和使用它。以下是如何结构化并发布您的 MCP 服务器的方法:
- 首先,将现有的
document_reader.py文件重命名为server.py,以与包结构保持一致,然后创建必要的目录结构:
css
mcp-document-reader/
├── src/
│ └── document_reader/
│ ├── __init__.py
│ └── server.py
├── pyproject.toml
├── README.md
└── LICENSE- 在
__init__.py文件中,导入并暴露服务器的主要组件:
python
# src/document_reader/__init__.py
from .server import read_pdf, read_docx, mcp- 定义您的包元数据在
pyproject.toml中(将名称改为独一无二的名称,因为我已经使用了下面的名称):
ini
[build-system]
requires = ["setuptools>=61.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "mcp-document-reader"
version = "0.1.0"
description = "MCP server for reading and extracting text from PDF and DOCX files"
readme = "README.md"
authors = [
{name = "Your Name", email = "your.email@example.com"}
]
license = {text = "MIT"}
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
dependencies = [
"mcp>=1.2.0",
"markitdown[all]",
]
requires-python = ">=3.9"
[project.scripts]
mcp-document-reader = "document_reader.server:main"
[tool.setuptools]
package-dir = {"" = "src"}- 在你的
server.py文件中添加一个main()函数使其可执行:
csharp
# src/document_reader/server.py
def main():
mcp.run()
if __name__ == "__main__":
main()-
使用构建工具构建你的包:
uv pip install build
python -m build
这将在 dist/ 目录中生成分发文件。
- 创建一个 PyPI 账户并上传您的包:
在上传到 PyPI 之前,您需要在 PyPI.org 创建一个账户。注册后,您必须验证您的电子邮件,添加 2FA 验证并生成您的设置中的 API 令牌。然后,您可以使用 twine 安全地上传您的包。Twine 是一个用于将 Python 包发布到 PyPI 的工具,通过 HTTPS 提供更好的安全性,并支持现代身份验证方法。
uv pip install twine在首次上传到 PyPI 时,您将被提示输入 PyPI 账户凭据。为了更好的安全性,建议使用 API 令牌而不是密码:
twine upload dist/*或者,您可以在家目录中的 .pypirc 文件中存储凭据,或者使用环境变量。
发布后,用户可以安装您的 MCP 服务器:
csharp
uv add mcp-document-reader并直接运行:
javascript
mcp-document-reader例如,我的服务器现在可以在 pypi.org/project/mcp... 访问。
要使用打包的服务器与 Claude Desktop 或其他 MCP 客户端,用户可以在配置文件中使用 uv 添加它:
json
"pypi-document-reader-mcp": {
"command": "uv",
"args": [
"--directory",
"/Users/bexgboost/miniforge3/lib/python3.12/site-packages/document_reader",
"run",
"server.py"
]
}注意:为了在您的主机上正确安装服务器,您必须像上面那样提供安装目录。
这种部署方法非常适合与他人共享您的 MCP 服务器,同时保持本地托管的简单性。服务器运行在用户的机器上,因此无需担心托管费用或管理远程基础设施的问题。
如需了解其他托管选项的详细信息,包括使用 SSE 传输进行远程部署,请参阅 Aravind Putrevu 关于托管 MCP 服务器的指南。
结论
FastMCP 使构建扩展特定任务的 LLM 能力的自定义工具变得容易。我们的文档阅读器示例展示了如何通过简单的代码启用 AI 助手处理 PDF 和 DOCX 文件。此模式适用于许多应用程序,包括网络爬虫、数据分析和 API 集成。对于 AI 应用程序中的网络爬虫,Firecrawl 提供了一个与 Claude Desktop 和 Cursor 兼容的现成 MCP 服务器。
MCPs 允许开发人员以最少的努力创建语言模型的标准扩展。本教程涵盖了使用 Python 构建和部署简单 MCP 服务器的基础知识。要获取更多详细信息,请参阅官方 MCP 文档以获取完整的参考资料。访问 Firecrawl 博客以获取将网络爬虫与 AI 结合的实用教程,并在实际项目中实现这些技术。