目录
[1 Hive分区技术概述](#1 Hive分区技术概述)
[2 静态分区详解](#2 静态分区详解)
[2.1 静态分区工作原理](#2.1 静态分区工作原理)
[2.2 使用场景](#2.2 使用场景)
[2.3 示例](#2.3 示例)
[3 动态分区深度解析](#3 动态分区深度解析)
[3.1 动态分区执行流程](#3.1 动态分区执行流程)
[3.2 使用场景](#3.2 使用场景)
[3.3 示例](#3.3 示例)
[4 使用场景对比](#4 使用场景对比)
[4.1 场景选择](#4.1 场景选择)
[5 性能对比与优化](#5 性能对比与优化)
[5.1 插入性能](#5.1 插入性能)
[5.2 查询性能](#5.2 查询性能)
[5.3 小文件问题](#5.3 小文件问题)
[6 最佳实践](#6 最佳实践)
[6.1 混合分区策略](#6.1 混合分区策略)
[6.2 性能调优参数](#6.2 性能调优参数)
[7 总结与建议](#7 总结与建议)
Hive是一种基于Hadoop的数据仓库工具,广泛用于处理大规模数据集。分区是Hive中优化查询性能的重要机制,通过将数据按特定列划分为多个子集来加速查询。本文将深入探讨Hive中的两种分区方式------静态分区 和动态分区,分析它们的使用场景、性能特点,并通过流程图和示例帮助读者更好地理解和应用。
1 Hive分区技术概述
Hive 中的分区本质上是将表的数据按特定列的值分割并存储在不同的 HDFS 目录中,从而实现数据隔离和查询裁剪(Partition Pruning)。分区分为静态分区和动态分区,区别在于分区创建的方式和时机。
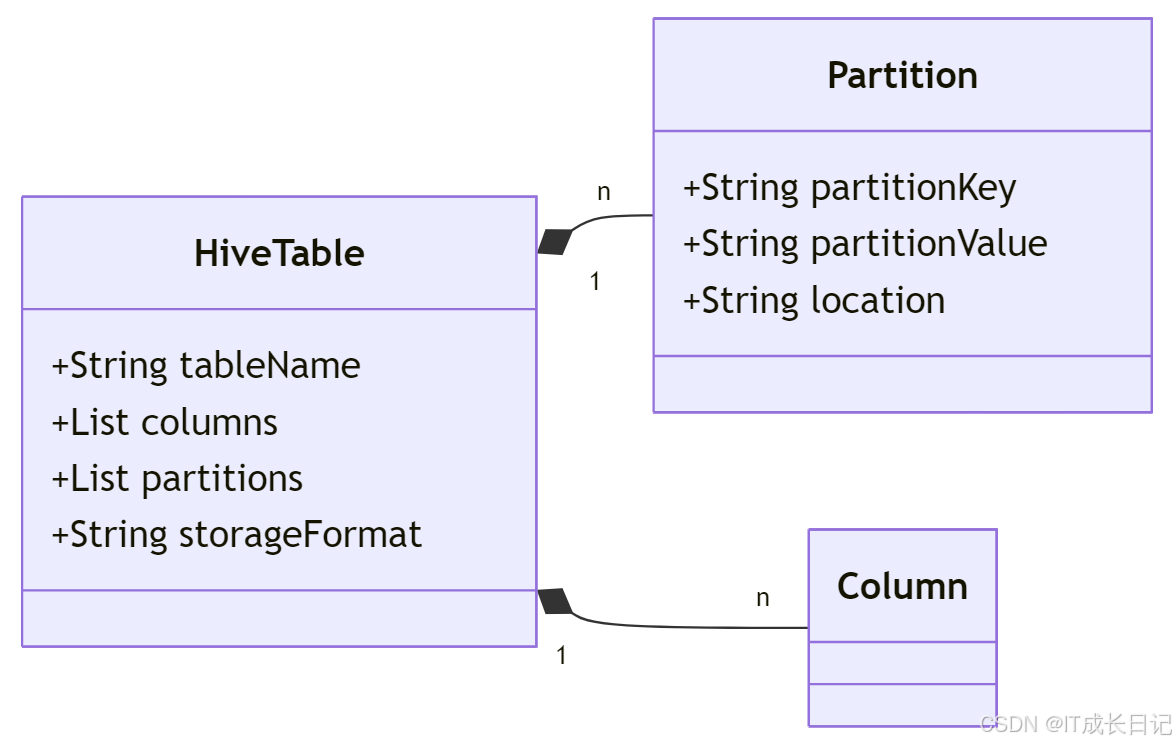
结构说明:
- HiveTable:表示一个Hive表,包含列定义和分区信息
- Partition:每个分区对应一个HDFS目录,由分区键(如dt)和值(如202504)定义
- 关系:一个表可以包含多个分区,每个分区独立存储数据
2 静态分区详解
2.1 静态分区工作原理
静态分区在表创建时定义,用户在插入数据时必须显式指定分区值。Hive 会根据指定的值创建对应的分区目录。
- 静态分区数据插入流程
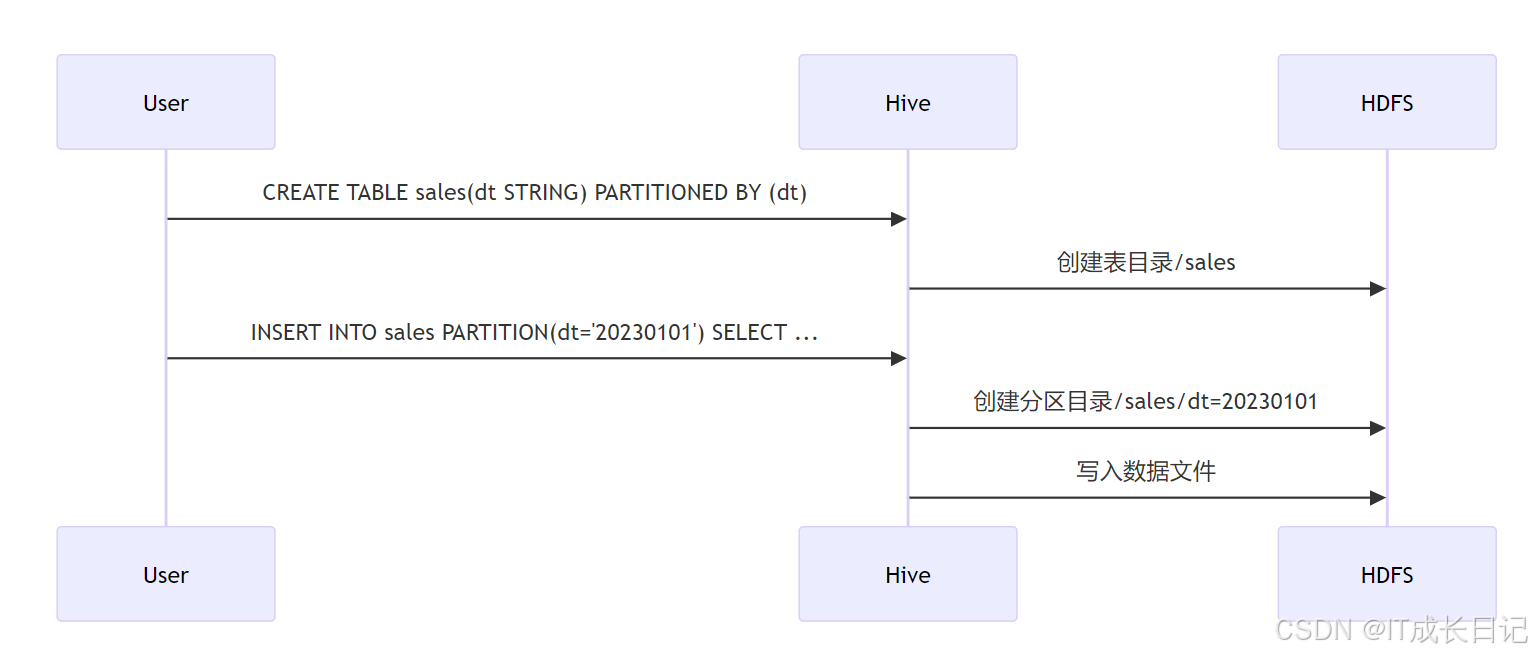
流程步骤:
- 用户创建分区表,指定分区键(如 dt)
- Hive 在 HDFS 上创建表的基础目录
- 用户插入数据时显式指定分区值(如 dt='20250426')
- Hive 在 HDFS 上创建对应的分区目录并写入数据
2.2 使用场景
- 已知分区值:当数据的分区值是预先确定的,例如按日期(如 20250426)或地区(如 CN)划分
- 有限分区数量:适用于分区数量较少且可控的场景
- 精细管理:需要对特定分区进行删除、更新等操作时
2.3 示例
-- 创建静态分区表
CREATE TABLE static_sales (
order_id BIGINT,
amount DECIMAL(10,2)
) PARTITIONED BY (dt STRING);
-- 插入数据到指定分区
INSERT INTO static_sales PARTITION(dt='20250426')
SELECT order_id, amount FROM raw_orders WHERE dt='20250426';
-- 查询特定分区
SELECT * FROM static_sales WHERE dt='20250426';3 动态分区深度解析
3.1 动态分区执行流程
动态分区允许 Hive 在插入数据时根据数据的列值自动创建分区,无需用户手动指定所有分区值。
- 动态分区插入流程

流程步骤:
- 用户执行插入操作(如 INSERT OVERWRITE)
- Hive 根据配置决定分区模式(严格模式或非严格模式)
- 在非严格模式下,Hive 分析 SELECT 语句中的分区列值
- 根据列值自动推断并创建分区目录
-
将数据写入对应的分区目录
-
配置要求
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
3.2 使用场景
- 分区值不确定:当数据量大且分区值数量未知或变化频繁时
- 自动化管理:需要批量插入数据并自动生成分区时
- 动态列值:分区键的值来源于数据本身(如日期、类别)
3.3 示例
-- 创建动态分区表
CREATE TABLE dynamic_sales (
order_id BIGINT,
amount DECIMAL(10,2),
dt STRING
) PARTITIONED BY (dt);
-- 动态插入数据
INSERT OVERWRITE TABLE dynamic_sales PARTITION(dt)
SELECT order_id, amount, dt FROM raw_orders;
-- 查看生成的分区
SHOW PARTITIONS dynamic_sales;4 使用场景对比
4.1 场景选择
静态分区适用场景:
- 数据按固定维度划分,分区值已知且数量有限
- 需要对分区进行精细控制(如删除旧分区)
- 对数据一致性要求较高
动态分区适用场景:- 数据量大,分区值随数据动态变化
- 批量导入数据,减少手动操作
- 追求自动化和灵活性
5 性能对比与优化
5.1 插入性能
分析:
- 静态分区:插入时需手动指定分区值,Hive 为每个分区创建目录,速度较稳定但较慢
- 动态分区:自动推断分区值并创建目录,可能生成更多 MapReduce 任务,插入时间稍长
- 无分区:无需分区开销,插入最快,但查询效率低
5.2 查询性能
分析:
- 查询性能相似:静态分区和动态分区都支持分区裁剪,仅扫描相关分区,效率远高于全表扫描
- 关键点:合理选择分区键以提高裁剪效率
5.3 小文件问题
动态分区可能因自动创建大量分区而产生小文件问题,影响查询性能。解决方法:
-- 合并小文件
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
INSERT OVERWRITE TABLE dynamic_sales PARTITION(dt)
SELECT * FROM dynamic_sales;6 最佳实践
6.1 混合分区策略
结合静态分区和动态分区的优势,适用于复杂场景。
-
混合分区流程
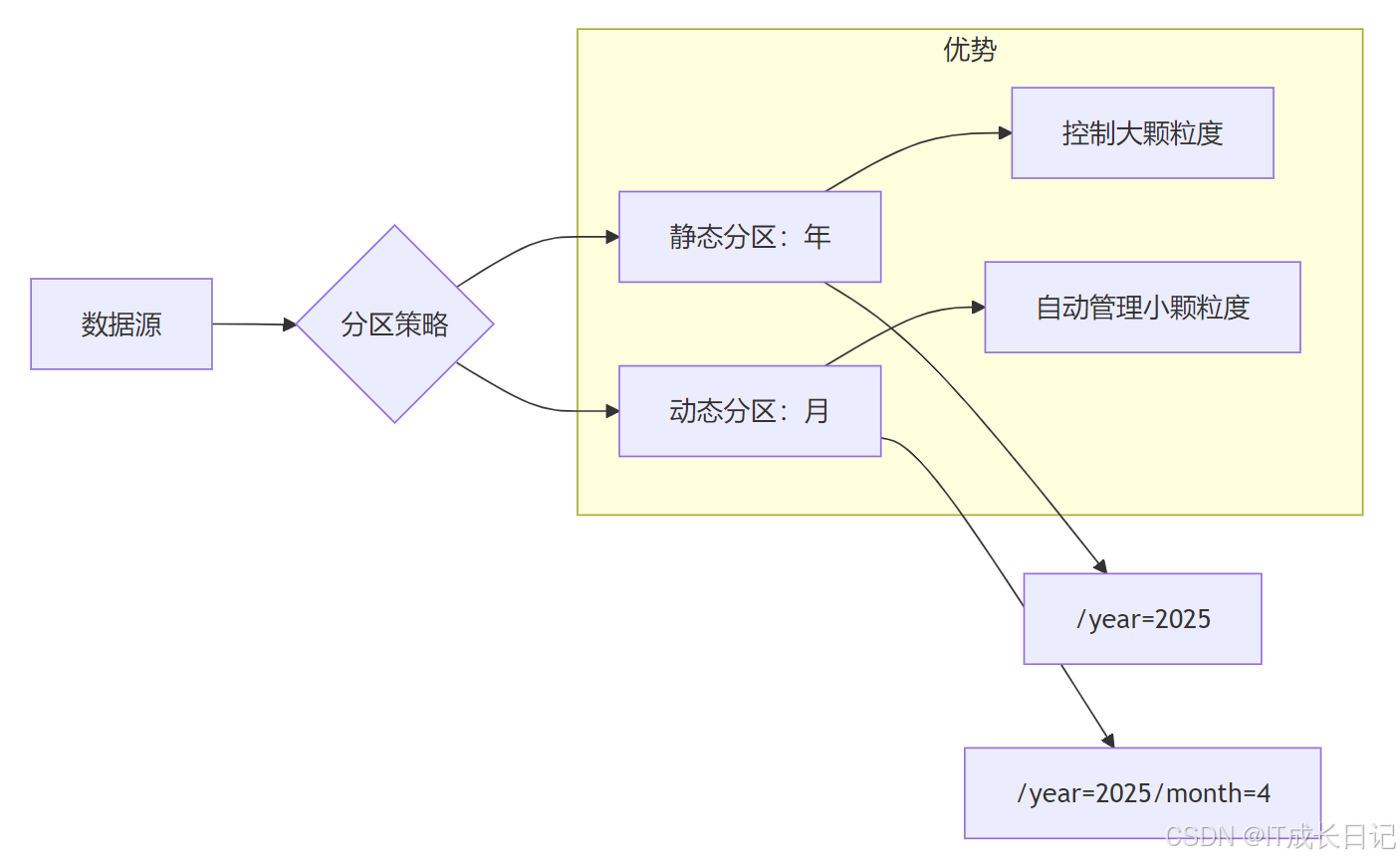
-
示例:
CREATE TABLE mixed_sales (
order_id BIGINT,
amount DECIMAL(10,2)
) PARTITIONED BY (year INT, month STRING);INSERT INTO mixed_sales PARTITION(year=2025, month)
SELECT order_id, amount, month FROM raw_sales WHERE year=2025;
6.2 性能调优参数
SET hive.exec.max.dynamic.partitions=1000;
-- 限制动态分区数量
SET hive.exec.parallel=true;
-- 启用并行执行7 总结与建议
- 静态分区:适合分区值已知、管理需求高的场景,插入稍慢但查询高效
- 动态分区:适合分区值动态变化、自动化需求高的场景,需关注小文件问题
- 建议:
- 小规模数据或关键业务表使用静态分区
- 大规模数据处理使用动态分区并优化配置
- 混合分区策略可兼顾灵活性和性能
根据业务需求选择合适的分区方式,并在实际应用中优化Hive性能。