目录
[1 Hive DDL操作概述](#1 Hive DDL操作概述)
[2 数据库操作全流程](#2 数据库操作全流程)
[2.1 创建数据库](#2.1 创建数据库)
[2.2 查看数据库](#2.2 查看数据库)
[2.3 使用数据库](#2.3 使用数据库)
[2.4 修改数据库](#2.4 修改数据库)
[2.5 删除数据库](#2.5 删除数据库)
[3 表操作全流程](#3 表操作全流程)
[3.1 创建表](#3.1 创建表)
[3.2 查看表信息](#3.2 查看表信息)
[3.3 修改表](#3.3 修改表)
[3.4 删除表](#3.4 删除表)
[4 分区与分桶操作](#4 分区与分桶操作)
[4.1 分区操作流程](#4.1 分区操作流程)
[4.2 分桶操作](#4.2 分桶操作)
[5 最佳实践与注意事项](#5 最佳实践与注意事项)
[6 总结](#6 总结)
1 Hive DDL操作概述
Hive的数据定义语言(DDL)是用于创建、修改和删除数据库对象的命令集合,主要包括对数据库、表、视图等对象的操作。作为Hadoop生态系统中的数据仓库工具,Hive的DDL语法与传统的SQL语法高度相似,但也有一些特有的扩展。
Hive DDL的主要特点:
- 类SQL语法:HiveQL语法与标准SQL高度兼容
- 元数据存储:DDL操作会记录在元数据存储中(通常使用MySQL或Derby)
- 延迟执行:部分DDL操作不会立即影响实际数据文件
- 扩展属性:支持为数据库和表添加自定义属性
2 数据库操作全流程
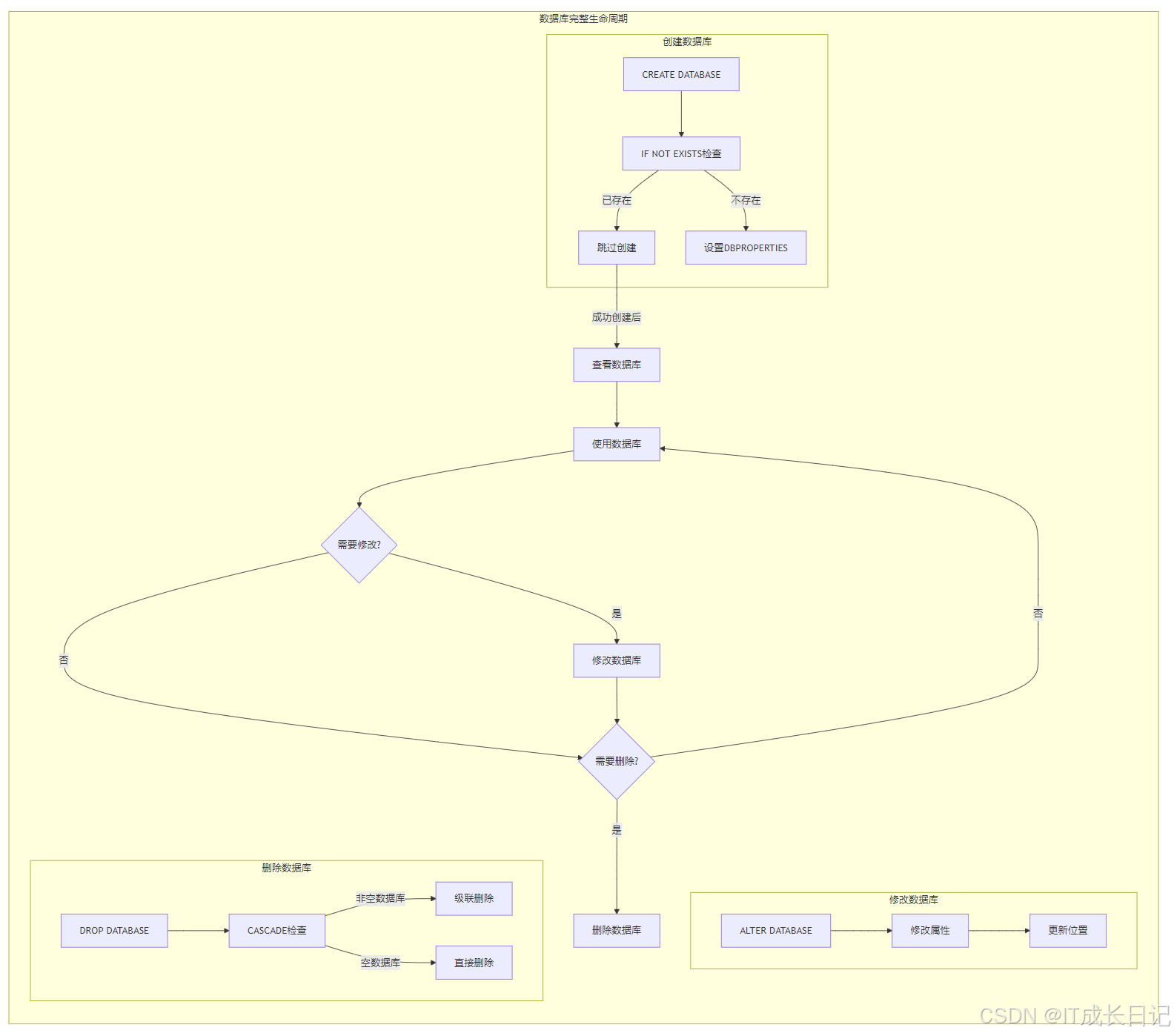
2.1 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];关键参数解释:
- IF NOT EXISTS:避免重复创建时报错
- LOCATION:指定数据库在HDFS上的存储路径
-
WITH DBPROPERTIES:为数据库添加描述性属性
-
示例
CREATE DATABASE IF NOT EXISTS sales_db
COMMENT 'Sales department database'
LOCATION '/user/hive/warehouse/sales.db'
WITH DBPROPERTIES ('creator'='John', 'date'='2025-04-20');
2.2 查看数据库
-
常用命令
-- 列出所有数据库
SHOW DATABASES;-- 使用正则表达式过滤
SHOW DATABASES LIKE 'sales*';-- 查看数据库详细信息
DESCRIBE DATABASE sales_db;-- 查看扩展属性
DESCRIBE DATABASE EXTENDED sales_db;
2.3 使用数据库
-- 切换当前数据库
USE sales_db;
-- 查看当前使用的数据库
SELECT current_database();2.4 修改数据库
Hive的数据库修改功能有限,主要可以修改属性
-- 修改数据库属性
ALTER DATABASE sales_db SET DBPROPERTIES ('edited-by'='Mary');
-- 修改数据库位置(注意:Hive 4.0+支持)
ALTER DATABASE sales_db SET LOCATION 'hdfs://new/path';2.5 删除数据库
-- 基本删除
DROP DATABASE sales_db;
-- 安全删除(数据库为空时)
DROP DATABASE IF EXISTS sales_db;
-- 强制删除(删除非空数据库)
DROP DATABASE IF EXISTS sales_db CASCADE;3 表操作全流程

3.1 创建表
-
基本语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement];
关键参数解释:
- EXTERNAL:创建外部表,删除表时不删除数据
- PARTITIONED BY:创建分区表
-
STORED AS:指定文件存储格式(如TEXTFILE, ORC, PARQUET等)
-
示例
CREATE EXTERNAL TABLE IF NOT EXISTS sales_records (
order_id BIGINT COMMENT 'Unique order identifier',
customer_id STRING,
amount DOUBLE
)
COMMENT 'Sales records from all regions'
PARTITIONED BY (sale_date STRING, region STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS ORC
LOCATION '/user/hive/warehouse/sales.db/records'
TBLPROPERTIES ('orc.compress'='SNAPPY');
3.2 查看表信息
-- 列出所有表
SHOW TABLES;
-- 查看表结构
DESCRIBE FORMATTED sales_records;
-- 查看表分区
SHOW PARTITIONS sales_records;
-- 查看建表语句
SHOW CREATE TABLE sales_records;3.3 修改表
-
常用修改操作
-- 重命名表
ALTER TABLE sales_records RENAME TO sales_data;-- 添加列
ALTER TABLE sales_data ADD COLUMNS (
payment_method STRING COMMENT 'Credit card or cash',
discount DOUBLE COMMENT 'Applied discount amount'
);-- 修改列
ALTER TABLE sales_data CHANGE COLUMN amount total_amount DOUBLE;-- 修改表属性
ALTER TABLE sales_data SET TBLPROPERTIES ('notes'='Updated schema 2025');-- 添加分区
ALTER TABLE sales_data ADD PARTITION (sale_date='2025-04-20', region='EAST');
3.4 删除表
-- 删除内部表(同时删除数据)
DROP TABLE sales_data;
-- 删除外部表(仅删除元数据)
DROP TABLE sales_data;
-- 有条件删除
DROP TABLE IF EXISTS sales_data;
-- 清空表数据(保留结构)
TRUNCATE TABLE sales_data;4 分区与分桶操作
4.1 分区操作流程

-
分区管理命令
-- 添加单个分区
ALTER TABLE sales_data ADD PARTITION (sale_date='2025-04-20');-- 添加多个分区
ALTER TABLE sales_data ADD
PARTITION (sale_date='2023-01-02')
PARTITION (sale_date='2023-01-03');-- 删除分区
ALTER TABLE sales_data DROP PARTITION (sale_date='2025-04-20');-- 修复分区(元数据与HDFS不一致时)
MSCK REPAIR TABLE sales_data;
4.2 分桶操作
分桶是将数据分散到固定数量的桶中,提高查询效率
-- 创建分桶表
CREATE TABLE bucketed_users (
id INT,
name STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;5 最佳实践与注意事项
命名规范:
- 使用小写字母和下划线组合
- 保持名称描述性但简洁
性能考虑:- 合理使用分区避免小文件问题
- 根据查询模式设计分区键
数据安全:- 重要数据使用外部表
- 定期备份元数据
版本兼容性:- 不同Hive版本DDL语法可能有差异
- 注意Hive与传统RDBMS的语法区别
6 总结
Hive DDL提供了完整的数据对象管理能力,从数据库到表再到分区和分桶。掌握这些操作是使用Hive进行大数据处理的基础。在实际工作中,建议:
- 结合业务需求设计合理的表结构
- 充分利用分区和分桶优化查询性能
- 通过属性(DBPROPERTIES/TBLPROPERTIES)记录元信息
- 定期维护和优化数据库对象