🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目🍅 ↓↓文末获取源码联系↓↓🍅
这里写目录标题
- 基于大数据的手机详细信息数据分析系统-功能介绍
- 基于大数据的手机详细信息数据分析系统-选题背景意义
- 基于大数据的手机详细信息数据分析系统-技术选型
- 基于大数据的手机详细信息数据分析系统-视频展示
- 基于大数据的手机详细信息数据分析系统-图片展示
- 基于大数据的手机详细信息数据分析系统-代码展示
- 基于大数据的手机详细信息数据分析系统-结语
基于大数据的手机详细信息数据分析系统-功能介绍
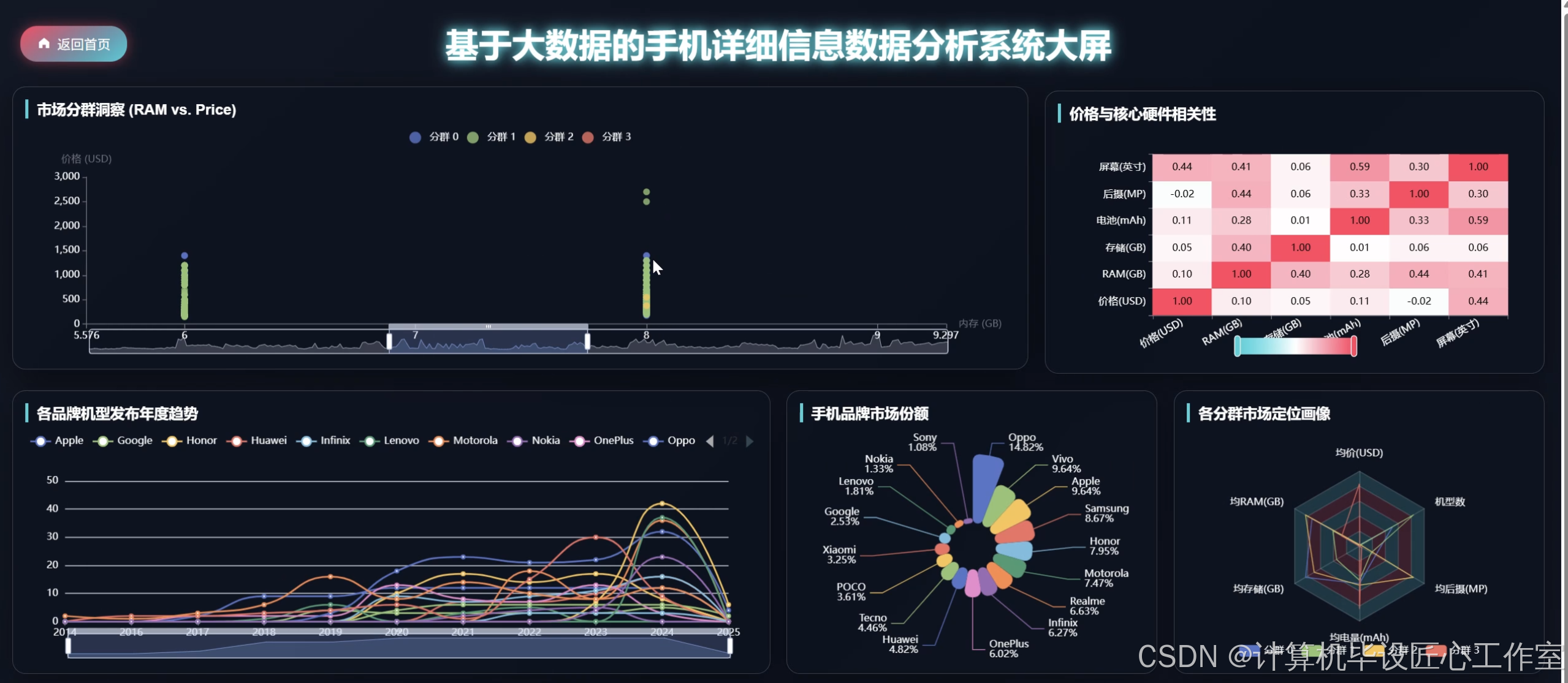
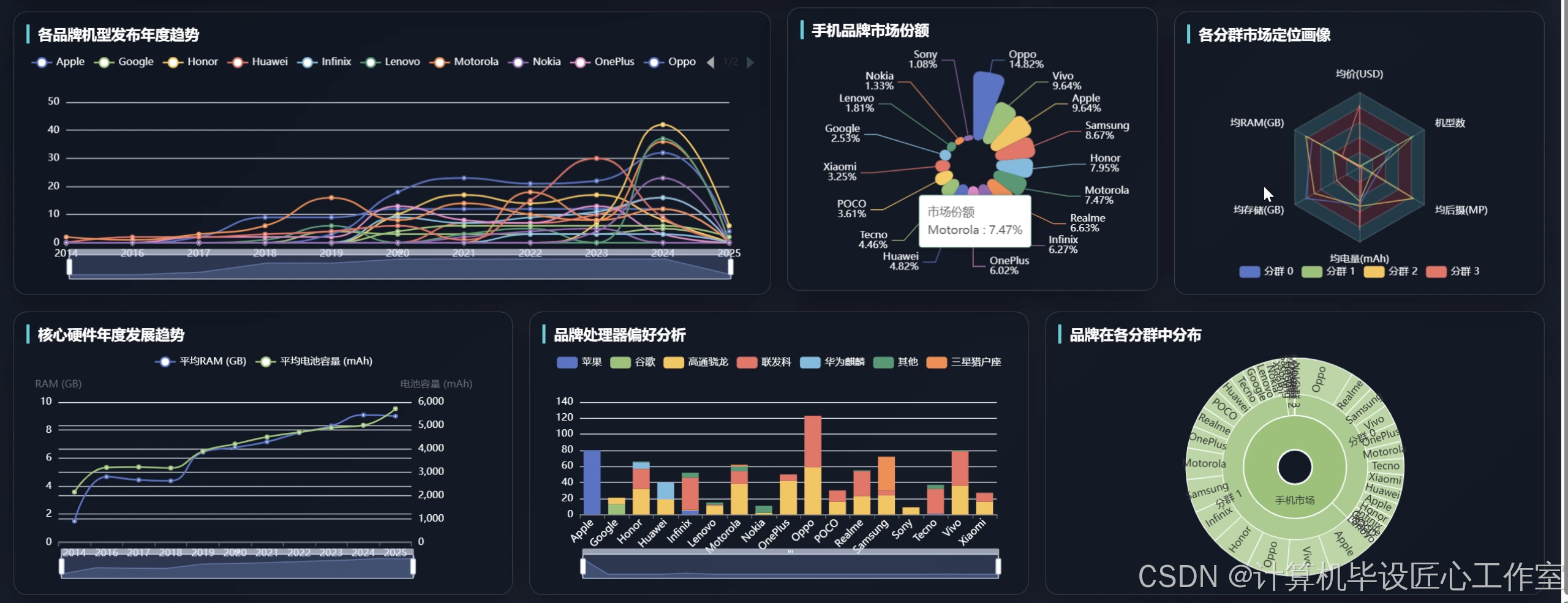
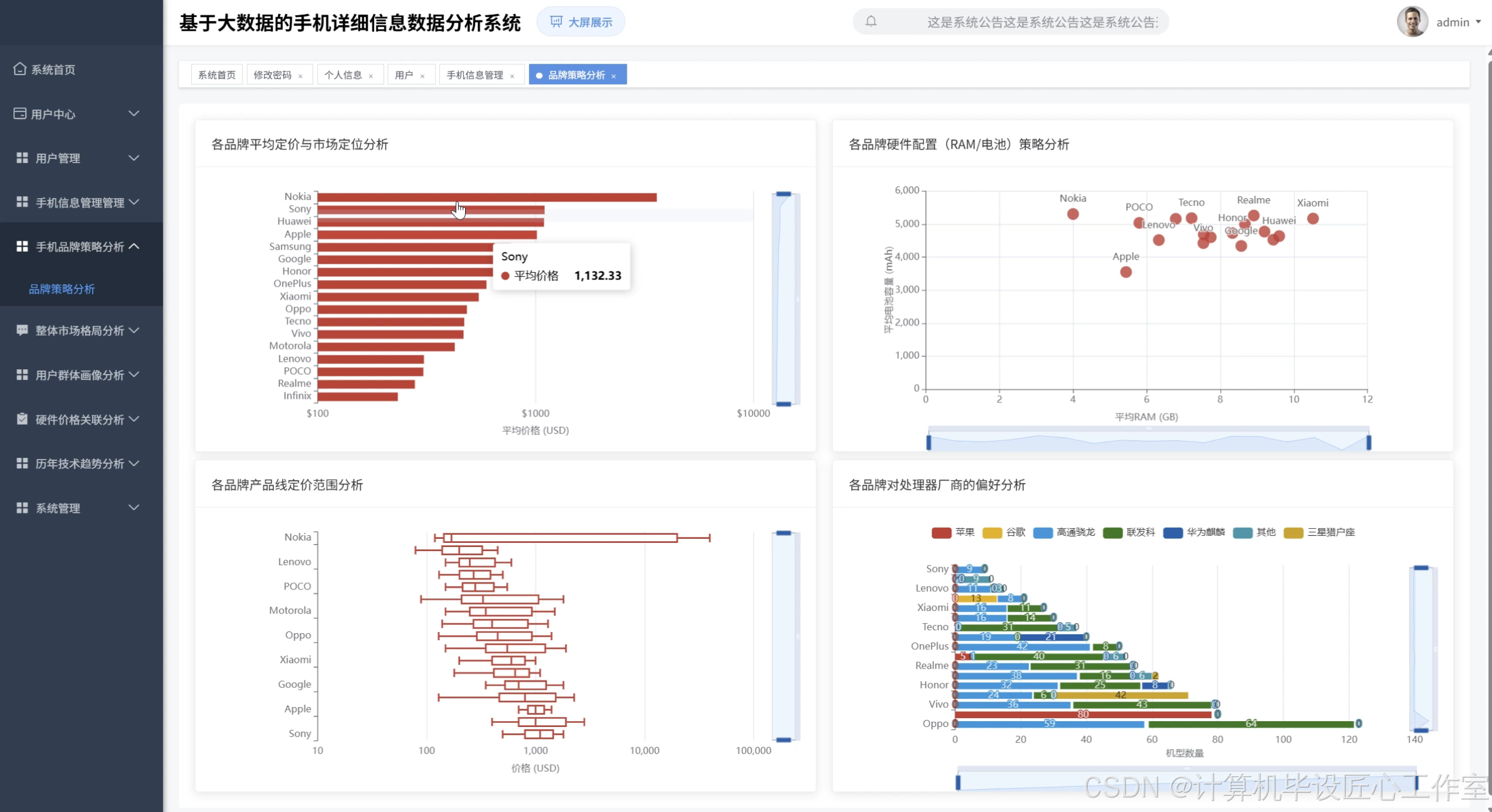
基于Hadoop+Spark的手机详细信息数据分析系统是一套采用现代大数据技术栈构建的智能分析平台,该系统充分利用Hadoop分布式文件系统(HDFS)进行海量手机数据的存储管理,结合Apache Spark强大的内存计算能力实现高效的数据处理与分析。系统后端采用Django框架构建RESTful API接口,前端运用Vue.js配合ElementUI组件库和ECharts可视化库打造直观的用户交互界面。核心功能涵盖市场宏观格局分析、品牌深度剖析与产品策略、价格与硬件配置关联性分析、手机技术演进趋势分析以及基于K-Means聚类算法的市场分群与画像分析等五大模块。系统通过Spark SQL进行复杂查询操作,利用Pandas和NumPy进行数据预处理和统计计算,最终将分析结果以丰富的图表形式展现,为用户提供全方位的手机市场洞察。整个系统架构设计合理,技术选型先进,能够有效处理大规模手机信息数据,为相关决策提供可靠的数据支撑。
基于大数据的手机详细信息数据分析系统-选题背景意义
选题背景
随着智能手机市场的快速发展和产品迭代加速,手机厂商面临着日益激烈的竞争环境。当前手机市场呈现出产品同质化严重、消费者需求多样化、技术创新周期缩短等特点,各大品牌需要通过精准的市场定位和产品策略来获得竞争优势。传统的市场分析方法往往依赖人工统计和小样本调研,难以应对海量多维的手机产品数据,分析效率低下且容易出现偏差。同时,手机产品涉及的技术参数众多,包括处理器性能、内存容量、电池续航、摄像头配置等各个方面,这些参数之间的关联关系复杂,传统分析工具难以进行深层次的挖掘。另外,手机市场的快速变化要求分析系统具备处理大量实时数据的能力,能够及时反映市场动态和技术趋势。在这样的背景下,运用大数据技术构建手机信息分析系统成为解决上述问题的有效途径。
选题意义
本课题的研究具有一定的理论价值和实践意义。从技术角度来看,通过将Hadoop分布式存储与Spark内存计算相结合,为处理大规模手机数据提供了可行的解决方案,验证了大数据技术在垂直领域应用的有效性。系统采用的K-Means聚类算法能够自动发现手机市场中的不同细分群体,为传统的市场分析方法提供了新的思路和工具。从实用层面而言,该系统可以帮助手机厂商更好地理解市场竞争格局,通过数据驱动的方式制定产品策略和定价决策。对于消费者来说,系统提供的手机配置与价格关联分析能够为购机选择提供参考依据。同时,系统展示的技术发展趋势分析对于产业链上游的芯片厂商和零配件供应商也具有一定的参考价值。虽然作为毕业设计项目,系统的规模和复杂度相对有限,但其展现的技术架构和分析思路为后续的深入研究奠定了基础,也为学习者提供了将理论知识与实践应用相结合的机会。
基于大数据的手机详细信息数据分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的手机详细信息数据分析系统-视频展示
基于Hadoop+Spark的手机信息分析系统完整方案
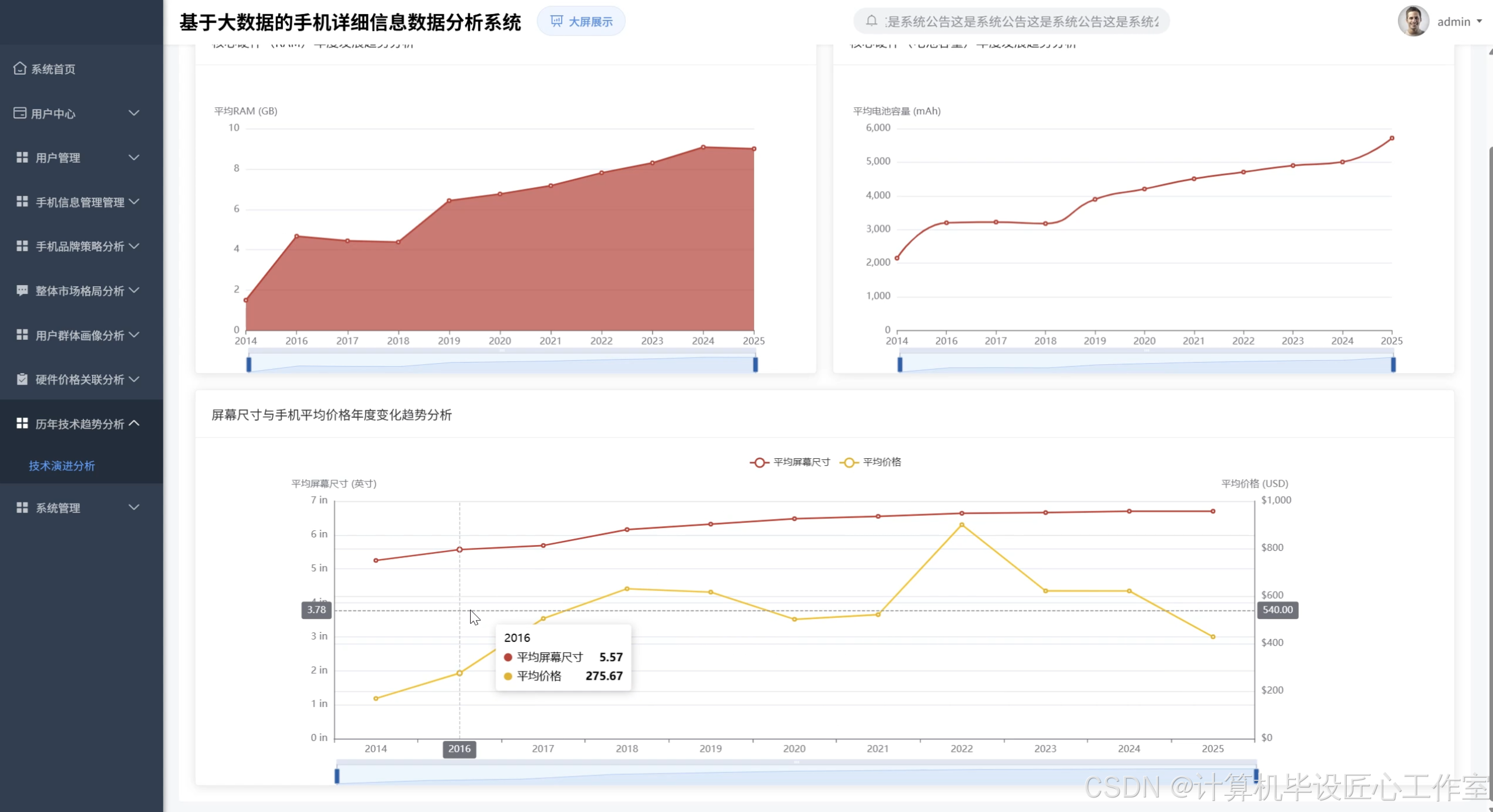
基于大数据的手机详细信息数据分析系统-图片展示
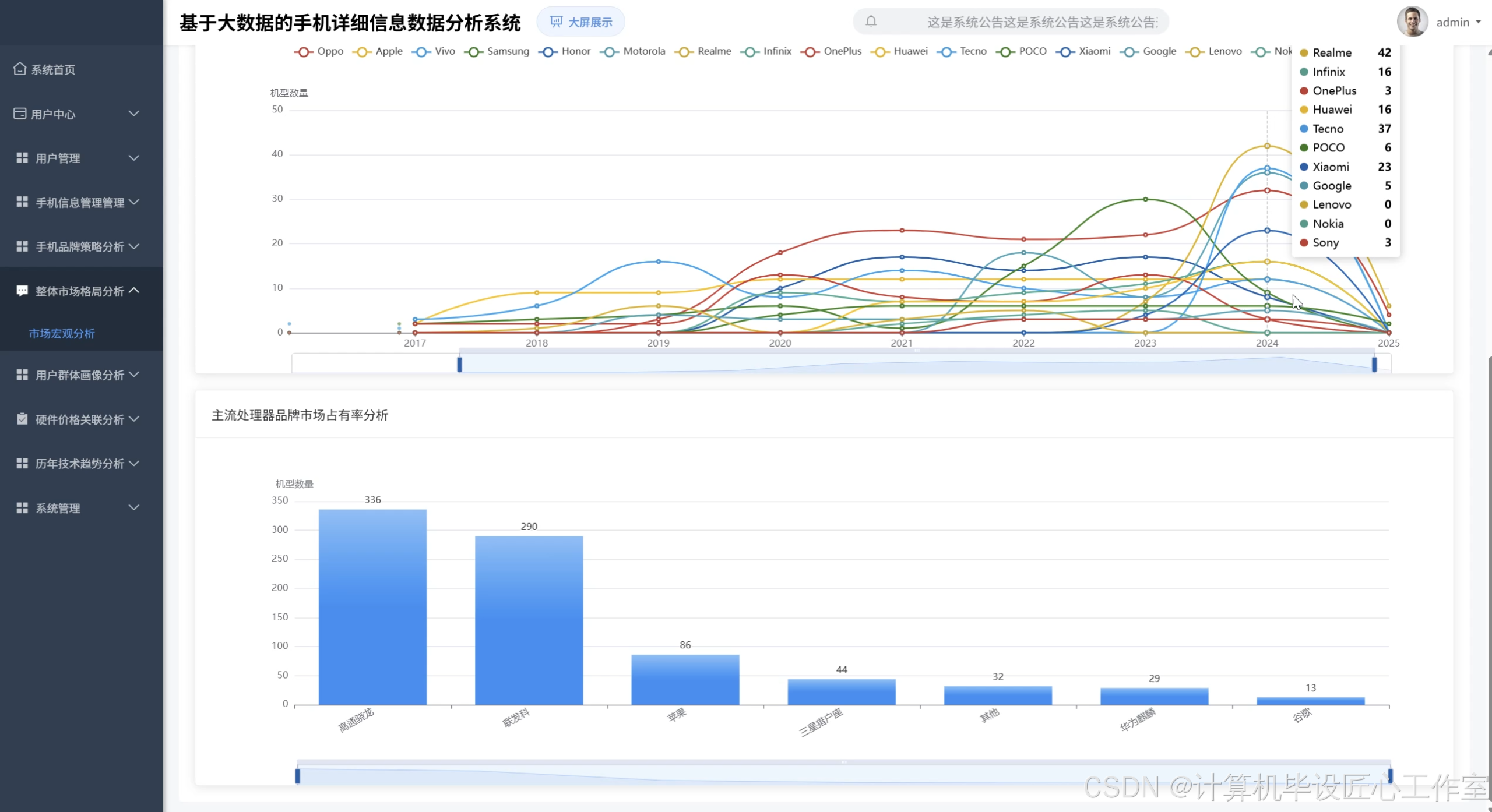
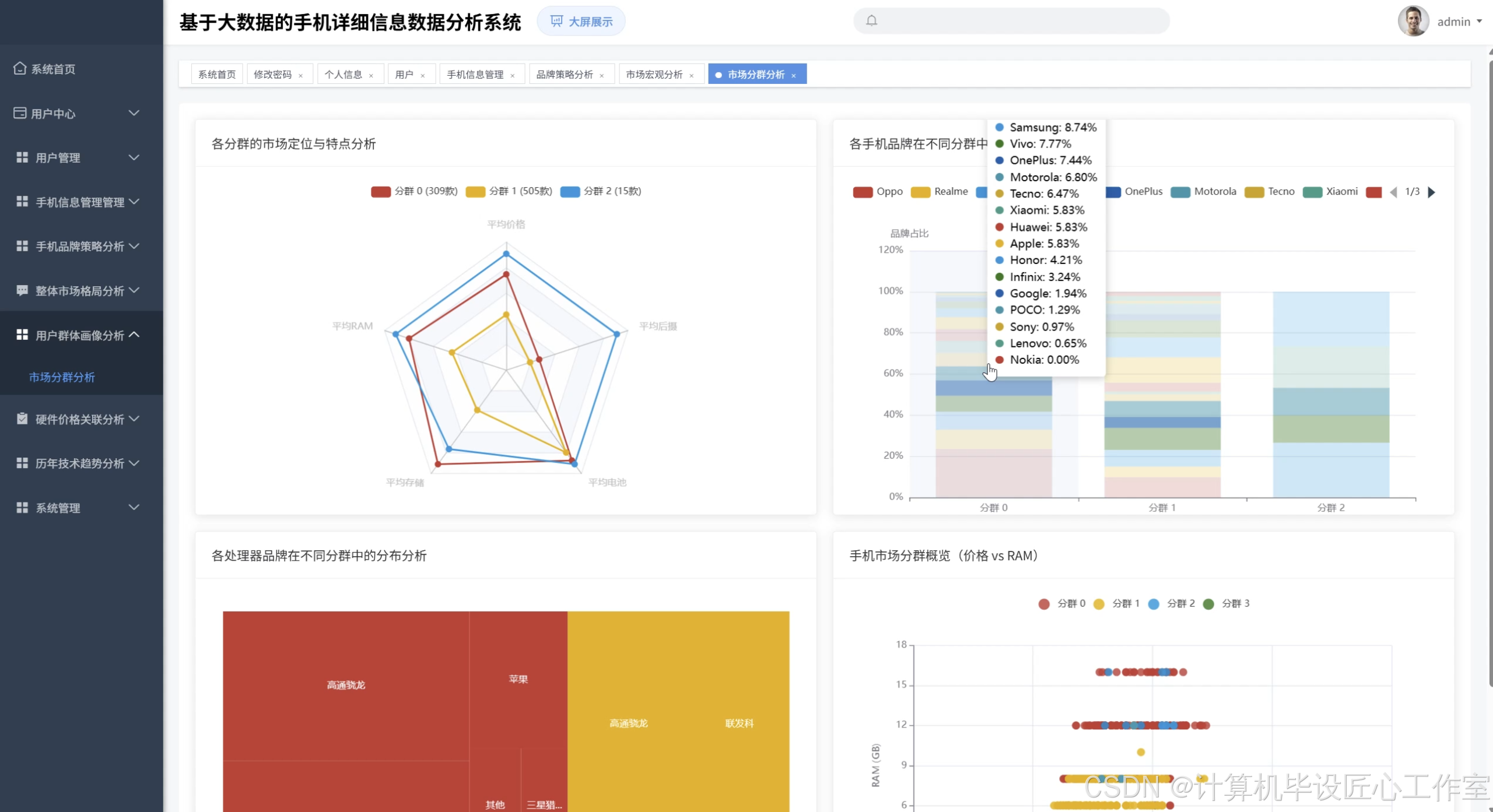
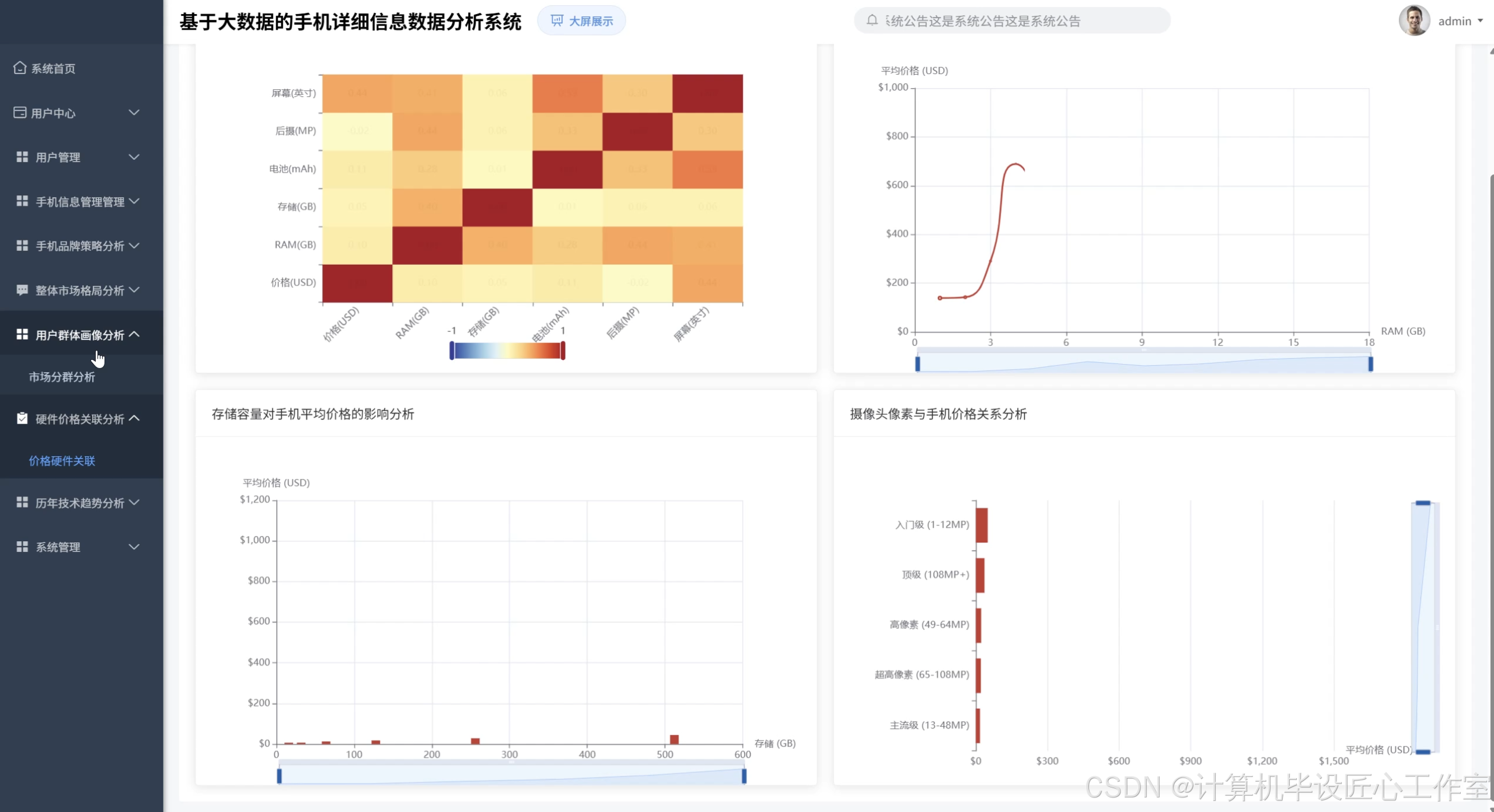
基于大数据的手机详细信息数据分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, max, min, when, desc, asc
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler, StandardScaler
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName("MobileDataAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def market_share_analysis(mobile_df):
"""市场份额分析 - 各品牌手机市场占有率统计"""
brand_count = mobile_df.groupBy("Company").agg(count("*").alias("model_count")).orderBy(desc("model_count"))
total_models = mobile_df.count()
brand_share = brand_count.withColumn("market_share", (col("model_count") / total_models * 100).cast("decimal(5,2)"))
brand_share_pandas = brand_share.toPandas()
top_brands = brand_share_pandas.head(10)
market_analysis_result = {
'total_models': total_models,
'brand_distribution': top_brands.to_dict('records'),
'market_leader': top_brands.iloc[0]['Company'] if len(top_brands) > 0 else None,
'market_leader_share': float(top_brands.iloc[0]['market_share']) if len(top_brands) > 0 else 0
}
processor_share = mobile_df.groupBy("ProcessorBrand").agg(count("*").alias("processor_count")).orderBy(desc("processor_count"))
processor_share_with_percentage = processor_share.withColumn("processor_share", (col("processor_count") / total_models * 100).cast("decimal(5,2)"))
processor_data = processor_share_with_percentage.toPandas().to_dict('records')
market_analysis_result['processor_distribution'] = processor_data
price_ranges = mobile_df.withColumn("price_range", when(col("Price_USD") < 200, "Budget").when((col("Price_USD") >= 200) & (col("Price_USD") < 500), "Mid-range").when((col("Price_USD") >= 500) & (col("Price_USD") < 1000), "Premium").otherwise("Flagship"))
price_distribution = price_ranges.groupBy("price_range").agg(count("*").alias("count")).orderBy(desc("count"))
market_analysis_result['price_segment_distribution'] = price_distribution.toPandas().to_dict('records')
return market_analysis_result
def brand_strategy_analysis(mobile_df):
"""品牌策略分析 - 各品牌定价策略和硬件配置分析"""
brand_pricing_strategy = mobile_df.groupBy("Company").agg(
avg("Price_USD").alias("avg_price"),
min("Price_USD").alias("min_price"),
max("Price_USD").alias("max_price"),
avg("RAM").alias("avg_ram"),
avg("BatteryCapacity_mAh").alias("avg_battery"),
avg("Storage_GB").alias("avg_storage"),
count("*").alias("model_count")
).orderBy(desc("avg_price"))
brand_strategy_pandas = brand_pricing_strategy.toPandas()
brand_strategy_pandas['price_range'] = brand_strategy_pandas['max_price'] - brand_strategy_pandas['min_price']
brand_strategy_pandas['positioning'] = brand_strategy_pandas['avg_price'].apply(
lambda x: 'Flagship' if x >= 800 else 'Premium' if x >= 500 else 'Mid-range' if x >= 200 else 'Budget'
)
brand_processor_preference = mobile_df.groupBy("Company", "ProcessorBrand").agg(count("*").alias("usage_count")).orderBy("Company", desc("usage_count"))
processor_preference_data = brand_processor_preference.toPandas()
strategy_result = {
'brand_positioning': brand_strategy_pandas.to_dict('records'),
'processor_partnerships': processor_preference_data.to_dict('records'),
'premium_brands': brand_strategy_pandas[brand_strategy_pandas['avg_price'] >= 600]['Company'].tolist(),
'budget_brands': brand_strategy_pandas[brand_strategy_pandas['avg_price'] < 300]['Company'].tolist()
}
hardware_correlation = mobile_df.select("Price_USD", "RAM", "Storage_GB", "BatteryCapacity_mAh").toPandas().corr()
strategy_result['hardware_price_correlation'] = hardware_correlation.to_dict()
return strategy_result
def market_segmentation_clustering(mobile_df):
"""基于K-Means的市场细分聚类分析"""
feature_columns = ["Price_USD", "RAM", "Storage_GB", "BatteryCapacity_mAh", "ScreenSize_inches"]
mobile_df_clean = mobile_df.select(*feature_columns).na.drop()
assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")
feature_vector = assembler.transform(mobile_df_clean)
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=True)
scaler_model = scaler.fit(feature_vector)
scaled_data = scaler_model.transform(feature_vector)
kmeans = KMeans(featuresCol="scaledFeatures", predictionCol="cluster", k=4, seed=42, maxIter=100)
kmeans_model = kmeans.fit(scaled_data)
clustered_data = kmeans_model.transform(scaled_data)
cluster_analysis = clustered_data.groupBy("cluster").agg(
count("*").alias("cluster_size"),
avg("Price_USD").alias("avg_price"),
avg("RAM").alias("avg_ram"),
avg("Storage_GB").alias("avg_storage"),
avg("BatteryCapacity_mAh").alias("avg_battery"),
avg("ScreenSize_inches").alias("avg_screen_size")
).orderBy("cluster")
cluster_profiles = cluster_analysis.toPandas()
cluster_profiles['cluster_label'] = cluster_profiles.apply(lambda row:
'Budget Phones' if row['avg_price'] < 300 else
'Mid-range Performance' if row['avg_price'] < 600 else
'Premium Flagship' if row['avg_price'] < 1000 else
'Ultra Premium', axis=1)
clustered_with_original = clustered_data.join(mobile_df.select("Company", "Price_USD", "RAM", "Storage_GB", "BatteryCapacity_mAh"),
(clustered_data.Price_USD == mobile_df.Price_USD) &
(clustered_data.RAM == mobile_df.RAM) &
(clustered_data.Storage_GB == mobile_df.Storage_GB))
brand_cluster_distribution = clustered_with_original.groupBy("Company", "cluster").agg(count("*").alias("count")).orderBy("Company", "cluster")
clustering_result = {
'cluster_profiles': cluster_profiles.to_dict('records'),
'cluster_centers': kmeans_model.clusterCenters(),
'brand_cluster_distribution': brand_cluster_distribution.toPandas().to_dict('records'),
'total_clustered_phones': clustered_data.count(),
'clustering_summary': f"Successfully segmented {clustered_data.count()} phones into 4 distinct market clusters"
}
return clustering_result基于大数据的手机详细信息数据分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目🍅 主页获取源码联系🍅