无状态转换操作与有状态转换操作
无状态转换操作
无状态转换操作是指在固定的时间跨度内进行数据处理,不涉及跨批次的数据处理。
例如,设置采集时间为三秒,则只对这三秒内的数据进行计算和聚合。
有状态转换操作
有状态转换操作涉及跨批次的数据处理,可以将不同批次的数据放在一起进行处理。
主要包括两种操作:updateStateByKey 和 window operations。
updateStateByKey
功能
用于记录历史记录,跨批次维护状态。
例如,进行累加操作,统计所有输入数据的累加值。
实现步骤
定义状态:状态可以是任意数据类型。
定义状态更新函数:根据新的事件更新每一个键对应的状态。
代码示例
java
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object UpdateStateByKey {
def main(args: Array[String]): Unit = {
val updateFunc = (values:Seq[Int],state:Option[Int])=>{
val currentCount = values.foldLeft(0)(_+_)
val previousCount = state.getOrElse(0)
Some(currentCount+previousCount)
}
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("update")
val ssc = new StreamingContext(sparkConf,Seconds(5))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("node01",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_,1))
val stateDStream = pairs.updateStateByKey[Int](updateFunc)
stateDStream.print()
ssc.start()
ssc.awaitTermination()
}
}运行结果
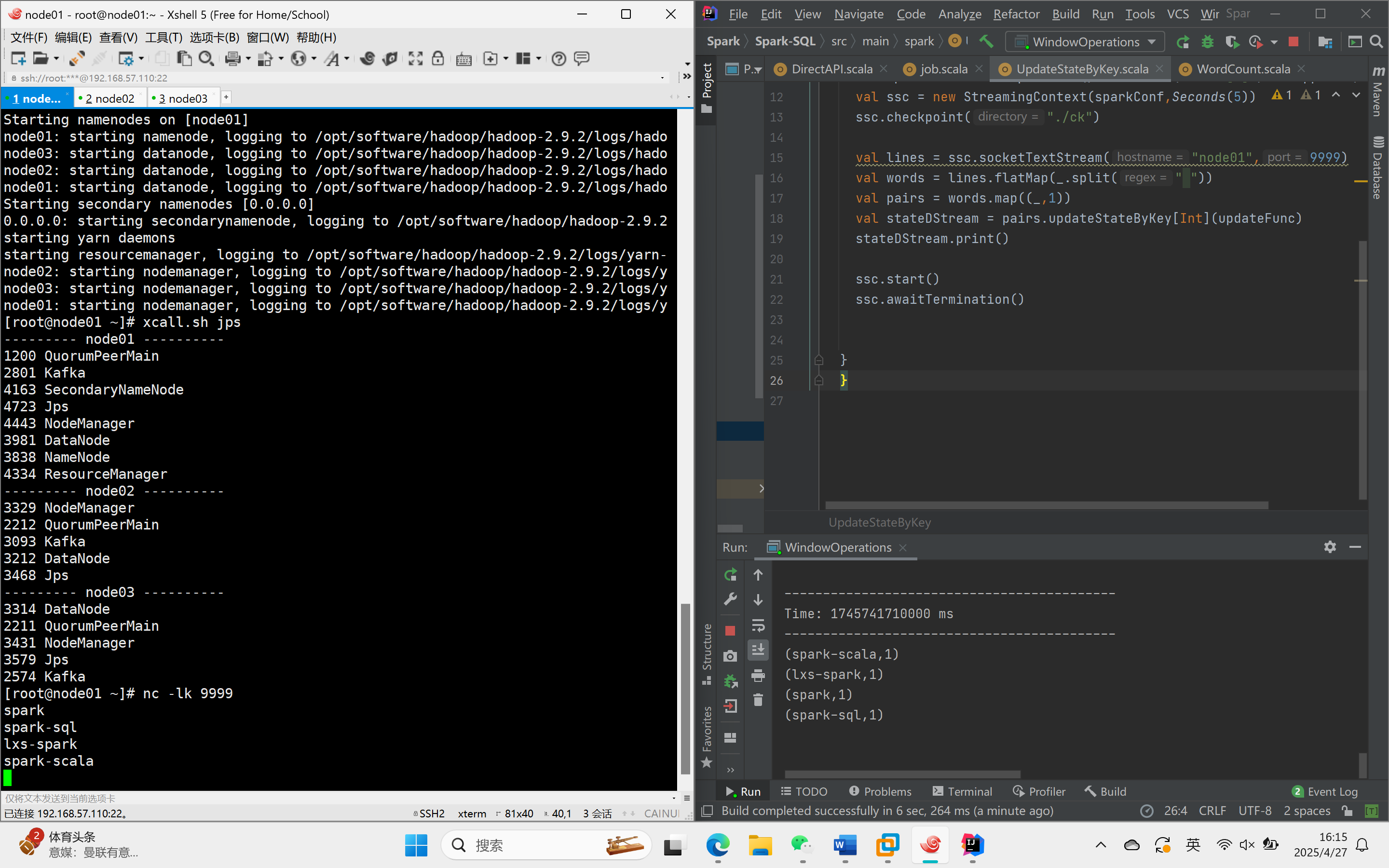
通过定义更新函数,获取当前数据和之前的状态,将新数据和旧状态相加,生成新的状态。
window operations
功能
设置窗口大小和滑动窗口的间隔,动态获取流媒体的状态。
需要两个参数:窗口时长和滑动步长。
实现步骤
窗口时长:规定每次计算的时间范围。
滑动步长:规定每隔多久触发一次计算。
两者必须是采集周期大小的整数倍。
代码示例
java
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WindowOperations {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("window")
val ssc = new StreamingContext(sparkConf,Seconds(3))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("node01",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_,1))
val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(12),Seconds(6))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}运行结果
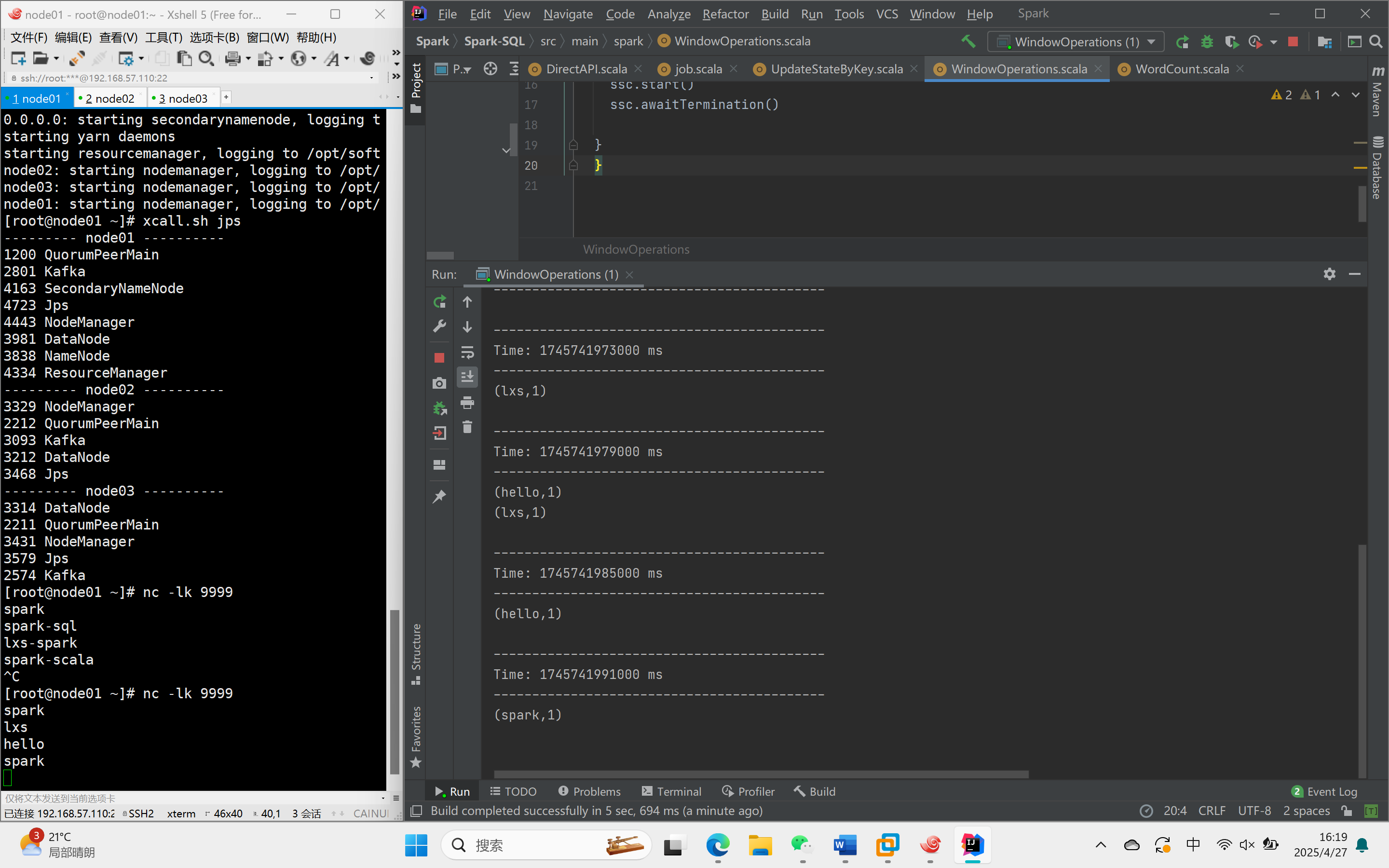
设置采集周期为三秒,窗口时长为12秒,滑动步长为6秒,进行词频统计。
输出操作
常见输出方式
打印在控制台上。
保存成文本文件。
保存成Java对象的序列化形式。
结合RDD进行输出。
用途
可以将数据写入外部数据库,如MySQL。