门控循环单元(GRU)基本原理
一、GRU核心思想与设计动机
目标 :在保留LSTM长程记忆能力的前提下,简化网络结构
核心创新:
- 合并LSTM的输入门和遗忘门为更新门(Update Gate)
- 去除细胞状态(Cell State),直接通过隐藏状态传递信息
- 参数数量比LSTM减少1/3,训练速度提升20-30%
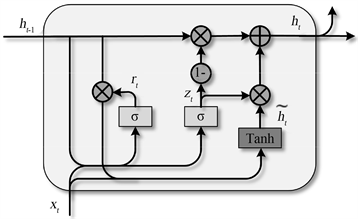
二、网络结构分解
1. 核心组件(两个门 + 候选状态)
| 组件 | 符号 | 功能描述 |
|---|---|---|
| 更新门 | z t z_t zt | 控制历史信息与当前信息的融合比例 |
| 重置门 | r t r_t rt | 决定忽略多少历史信息生成候选状态 |
| 候选隐藏状态 | h ~ t \tilde{h}_t h~t | 包含当前输入与部分历史信息的中间状态 |
2. 数学公式推导
更新门(Update Gate)
z t = σ ( W z ⋅ h t − 1 , x t + b z ) z_t = \sigma(W_z \cdot h_{t-1}, x_t + b_z) zt=σ(Wz⋅ht−1,xt+bz)
- σ \sigma σ: Sigmoid函数(输出0-1间的保留比例)
重置门(Reset Gate)
r t = σ ( W r ⋅ h t − 1 , x t + b r ) r_t = \sigma(W_r \cdot h_{t-1}, x_t + b_r) rt=σ(Wr⋅ht−1,xt+br)
候选隐藏状态
h ~ t = tanh ( W ⋅ r t ⊙ h t − 1 , x t + b ) \tilde{h}_t = \tanh(W \cdot r_t \\odot h_{t-1}, x_t + b) h~t=tanh(W⋅rt⊙ht−1,xt+b)
- ⊙ \odot ⊙: Hadamard积(控制历史信息流入量)
最终隐藏状态
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t
- 动态平衡历史信息保留与更新
三、PyTorch实现(手动版)
1. GRU单元实现
python
import torch
import torch.nn as nn
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.hidden_size = hidden_size
# 合并计算三个门的参数矩阵
self.W = nn.Linear(input_size + hidden_size, 3*hidden_size)
def forward(self, x, h_prev):
# 拼接输入与历史状态
combined = torch.cat((x, h_prev), dim=1)
gates = self.W(combined)
# 分割门控计算结果
z, r, n = torch.split(gates, self.hidden_size, dim=1)
# 激活函数应用
z = torch.sigmoid(z) # 更新门
r = torch.sigmoid(r) # 重置门
n = torch.tanh(r * n) # 候选状态
# 最终状态更新
h = (1 - z) * h_prev + z * n
return h