基于 MCP 架构的知识库问答系统实践
摘要:本文详细介绍了如何利用 Model Context Protocol(MCP)架构结合 Alibaba Cloud Tablestore 构建一个高效的私有知识库问答系统。文章首先概述了 MCP 协议和 Tablestore 的向量检索能力,随后深入剖析系统设计,包括知识库构建(文本切分、FAQ 提取、向量化存储)和知识检索(查询拆解、混合检索、结果筛选)两大核心模块。接着展示了基于 Java/Spring AI 的 MCP Server 实现、Python MCP Client 的功能逻辑,以及完整的部署和演示步骤。所有代码均已开源,供读者参考和扩展。
1. 背景介绍
1.1 Model Context Protocol(MCP)概述
MCP 是一个开源协议,最初由 Anthropic 提出,旨在标准化大型语言模型(LLM)与外部工具和数据源的交互方式,可视为 AI 应用的"通用接口"1。OpenAI、Claude 等主流平台已宣布支持 MCP,推动了 AI Agent 开发的标准化进程2。MCP 定义了工具发现、调用、参数传递和资源管理等功能,显著降低了点对点集成的复杂性,提升了系统的互操作性和可维护性3。
1.2 Alibaba Cloud Tablestore 简介
Alibaba Cloud Tablestore 是一款 Serverless 分布式 NoSQL 数据存储服务,支持全文、标量和向量混合检索,具备按量付费和 PB 级扩展能力4。通过创建 Search Index,Tablestore 可高效执行 KNN 向量查询,满足大规模语义检索需求5。其多语言 SDK 和 CLI 工具进一步简化了与 MCP Server 的集成,适合构建企业级知识库系统6。
1.3 RAG(Retrieval-Augmented Generation)简介
RAG 是一种结合检索和生成的技术,通过从外部知识库动态获取上下文,提升 LLM 回答的准确性并减少"幻觉"现象7。RAG 流水线通常包括文档切分、向量索引、查询检索和生成融合等步骤,每一步的优化直接影响系统性能8。
2. 系统架构设计
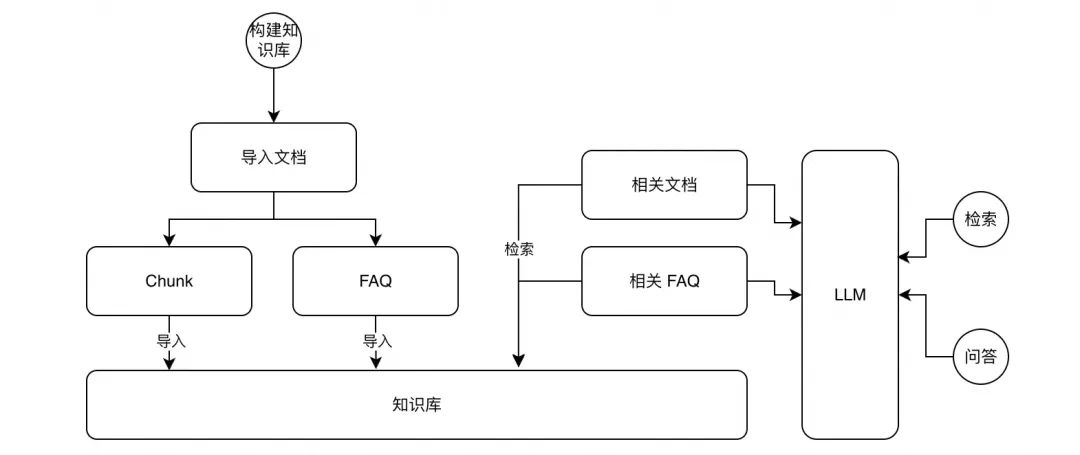
系统架构如下图所示,分为知识库构建和知识检索两大模块:
Plain
┌────────────┐ ┌──────────────┐ ┌─────────────┐
│ 文档源 │───→──│ 知识库构建 │───→──│ VectorStore │
│(Markdown) │ │(切分/FAQ/写入)│ │+ FAQ 索引 │
└────────────┘ └──────────────┘ └─────────────┘
│
↓
┌─────────┐ ┌───────────┐ ┌─────────────┐ ┌─────────┐
│ 用户提问 │─→──│ MCP Client│─→──│ MCP Server │─→──│ 检索工具 │
└─────────┘ └───────────┘ └─────────────┘ └─────────┘
│
↓
┌──────────────┐
│ LLM 生成回答 │
└──────────────┘- 知识库构建:将 Markdown 文档切分为语义完整的文本段,提取 FAQ,并将两者向量化后存储到 Tablestore。
- 知识检索:通过 MCP Client 拆解用户查询,调用 MCP Server 的检索工具获取相关文本和 FAQ,最终由 LLM 生成回答。
Agent架构设计
主要分为两部分:知识库构建和检索。
1.知识库构建
a.文本切段:对文本进行切段,切段后的内容需要保证文本完整性以及语义完整性。
b.提取 FAQ:根据文本内容提取 FAQ,作为知识库检索的一个补充,以提升检索效果。
c.导入知识库:将文本和 FAQ 导入知识库,并进行 Embedding 后导入向量。
2.知识检索(RAG)
a.问题拆解:对输入问题进行拆解和重写,拆解为更原子的子问题。
b.检索:针对每个子问题分别检索相关文本和 FAQ,针对文本采取向量检索,针对 FAQ 采取全文和向量混合检索。
c.知识库内容筛选:针对检索出来的内容进行筛选,保留与问题最相关的内容进行参考回答。
相比传统的 Naive RAG,在知识库构建和检索分别做了一些常见的优化,包括 Chunk 切分优化、提取 FAQ、Query Rewrite、混合检索等。
3. 具体实现
3.1 知识库构建
| 提示词 | 输入 | 输出 |
|---|---|---|
| 需要将以下文本切段,并根据文本内容整理 FAQ。 文本切段的要求是:1. 保证语义的完整性:不要将一个完整的句子切断,不要把表达同一个语义的不同句子分割开2. 保留足够多的上下文信息:如果切割后的文本段必须确保上下文信息能表达正确的语义,那就不能切割3. 过滤无效信息:过滤格式化内容如大量填充的空格、过度不需要的标点以及过渡语4. 移除 markdown 内容的标记,层次关系按 1、2、3 以及 1.1、2.1 来标记5. 只保留文本内容,移除链接等信息6. 不要对标题单独切段;仅对正文进行切段,标题可以与正文合并一段,或者作为上下文信息扩充正文分段7. 切段后的文本如果不是一个完整的句子,请修改为一个完整表达的句子FAQ 的要求是:1. FAQ 的问题范围尽量小,提出比较原子的"何时""为什么""如何"问题2. 对主要内容整理 FAQ,FAQ 的数量不大于 20 个直接输出整理后的结果,结果格式: | 表格存储向量检索在原有的 DiskANN 算法之上进行优化,提供大规模和高性能的向量检索服务。前期,我们也先为用户提供了基于 HNSW 的图算法,但是发现明显的性能问题。HNSW 对内存要求很高,很难支撑大规模数据,当内存不足时,HNSW 访问磁盘的性能差。表格存储上的用户大多数数据量都相对较大,HNSW 的效果和成本问题不符合我们的产品定位。我们希望可以让更多的数据可以低成本地使用上向量检索能力,因此我们后续废弃掉了 HNSW 算法,使用 DiskAnn 重新实现了向量检索能力。 | json { "Chunks": "表格存储向量检索在原有的 DiskANN 算法上进行了优化,提供大规模和高性能的向量检索服务。", "HNSW 图算法内存开销高,在大规模场景下性能和成本均不符合产品定位。", "DiskANN 在内存不足时能够提供更稳定的检索性能,满足大多数大规模场景需求。" , "FAQs": { "Question": "表格存储向量检索使用了什么算法?", "Answer": "在原有 DiskANN 算法的基础上进行了优化,提供大规模和高性能的向量检索服务。" }, { "Question": "为什么要放弃 HNSW 算法?", "Answer": "HNSW 对内存要求高,访问磁盘性能差,成本与效果不符合产品定位。" }, { "Question": "DiskANN 相比 HNSW 有何优势?", "Answer": "在内存不足时仍能提供稳定的检索性能,更适合大规模场景。" } } |
知识库构建分为三个步骤:
-
文本切分:通过 LLM 提示词对文档进行语义切分,确保每段文本语义完整且上下文连贯。示例提示词如下:
Plain将以下文档切分为语义完整的段落,每段不超过 500 字,并保留上下文连贯性: {document}- 优点是切分结果灵活且准确,缺点是执行速度较慢且消耗较多 Token。
-
FAQ 提取:基于切分后的文本段,利用 LLM 提取常见问题和答案,形成 FAQ 库。例如:
Plain从以下文本提取 FAQ 列表,格式为 [{"question": "", "answer": ""}, ...]: {chunk} -
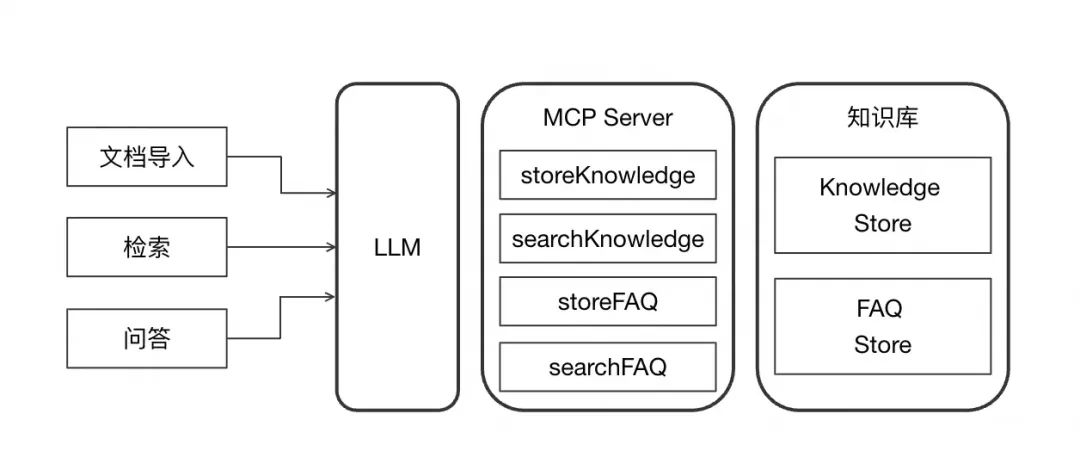
写入知识库 :将文本段和 FAQ 分别向量化后,通过 MCP Server 的
addDocument和addFAQ工具写入 Tablestore。代码示例:

from mcp_client import McpClient client = McpClient(server_url="http://localhost:8080") # 写入文本段 for chunk in chunks: client.call_tool("addDocument", {"content": chunk.text, "embedding": chunk.embedding}) # 写入 FAQ for faq in faqs: client.call_tool("addFAQ", {"question": faq.question, "answer": faq.answer})
3.2 MCP Server(Java/Spring AI)
MCP Server 基于 Spring AI 框架实现,暴露以下 4 个工具:
addDocument:将文本段向量化并写入向量索引。addFAQ:将 FAQ 写入全文+向量混合索引。searchByVector:执行 KNN 向量检索,返回最相似的文本段5。searchByFAQ:结合全文和向量检索,返回相关 FAQ。
| Tools | 功能 | 给 LLM 的描述 | 输入参数 | 输出结果 |
|---|---|---|---|---|
| storeKnowledge | 写入知识库内容,同时进行 Embedding 后写入向量。 | Store document into knowledge store for later retrieval. | json { "content": "知识库内容", "meta_data": { "source": "文档" } } | json { "content": { "type": "text", "text": "null" } , "isError": false } |
| searchKnowledge | 对知识库进行向量检索提取内容。 | Search for similar documents on natural language descriptions from knowledge store. | json { "query": "知识库内容", "size": 100 } | json { "content": { "type": "text", "text": "\[{"content":"知识库内容","meta_data":{"source":"文档"}}" } ], "isError": false } |
| storeFAQ | 写入 FAQ 内容,问题和答案分别写入 Question 和 Answer 两个字段,Question 字段额外进行 Embedding 后写入向量。 | Store document into FAQ store for later retrieval. | json { "question": "问题", "answer": "答案" } | json { "content": { "type": "text", "text": "null" } , "isError": false } |
工具注册代码示例:
Java
@Configuration
public class TablestoreMcpConfig {
@Bean
public McpServer tablestoreMcpServer(TablestoreClient client) {
return McpServer.builder()
.tool(new AddDocumentTool(client))
.tool(new AddFaqTool(client))
.tool(new VectorSearchTool(client))
.tool(new FaqSearchTool(client))
.build();
}
}Spring AI 自动将工具映射为 MCP 协议的函数调用,LLM 通过 MCP Client 触发对应操作9。
3.3 知识检索(RAG 优化)
检索流程包括:
-
查询拆解 :将复杂问题分解为原子子问题。例如:
1.Plain将以下问题拆解为子问题: 用户问题:{question} 输出格式:[{sub_question: ""}, ...] -
混合检索 :对每个子问题,调用
searchByVector(向量检索)和searchByFAQ(全文+向量混合检索)。 -
结果筛选:通过 LLM 提示词筛选最相关的内容,剔除冗余信息。
| 提示词模板 | 检索条件 | 检索结果 |
|---|---|---|
| 你是产品答疑助手,在回答问题之前请先检索 Knowledge 库和 FAQ 库:1. 先理解问题并对问题进行拆解,拆解成多个子问题。2. 每个子问题同时检索 Knowledge 库和 FAQ 库,每次检索结果不超过 20 条。3. 对检索的内容进行筛选,保留与问题最相关的内容,Knowledge 和 FAQ 分别不超过 10 条。最后合并检索内容,返回与检索内容最相关的 20 条,直接返回检索的结果,举例如下:1. 如果是 Knowledge,格式为:Knowledge: <结果>2. 如果是 FAQ,格式为:FAQ: <结果>检索内容:%s | Tablestore 底层向量索引算法选择了哪种实现? | Knowledge: 表格存储向量检索在原有的 DiskANN 算法之上进行了优化。。。Knowledge: 表格存储上的用户大多数数据量相对较大。。。FAQ: 为什么最初选择了 HNSW 图算法?FAQ: 为了给用户提供一种向量检索的服务选项。FAQ: 表格存储向量检索是基于什么算法实现的?FAQ: 表格存储向量检索是在原有的 DiskANN 算法基础上进行了优化。 |
3.4 知识库问答
问答阶段将筛选后的内容输入 LLM,生成最终回答。提示词模板如下:
Plain
根据以下知识段和 FAQ,回答用户问题:
问题:{question}
知识段:{vector_results}
FAQ:{faq_results}
回答格式:{answer}MCP Server 日志显示,系统自动调用检索工具并基于检索内容生成准确回答。
4. 部署与演示
4.1 创建 Tablestore 实例
使用 Tablestore CLI 创建实例6:
Bash
aliyun tablestore create-instance --instance-name my-kb --type Search4.2 启动 MCP Server
配置环境变量并启动服务:
Bash
export TSL_ENDPOINT=<your-endpoint>
export TSL_ACCESS_KEY_ID=<your-access-key-id>
export TSL_ACCESS_KEY_SECRET=<your-access-key-secret>
export TSL_INSTANCE_NAME=my-kb
mvn spring-boot:run或通过 IDE 运行 App 类,系统会自动初始化表和索引。
4.3 导入知识库
准备 Markdown 格式的知识库文档,配置 LLM API 密钥(默认使用 qwen-max),执行:
Bash
export LLM_API_KEY=sk-xxxxxx
python knowledge_manager.py --dir ./docs4.4 检索知识库
运行检索命令:
Bash
python query_manager.py --retrieve --question "什么是 MCP?"4.5 基于知识库问答
执行问答命令:
Bash
python query_manager.py --qa --question "MCP 的主要功能是什么?"5. 代码仓库
- Java MCP Server 实现:https://github.com/aliyun/alibabacloud-tablestore-mcp-server/tree/main/tablestore-java-mcp-server-rag
- Python Client 及管理脚本 :同仓库下
tablestore-python-mcp-server目录。
6. 结论
本实践展示了如何基于 MCP 架构和 Alibaba Cloud Tablestore 构建一个企业级知识库问答系统。通过优化 RAG 流程(语义切分、FAQ 提取、查询拆解、混合检索),系统实现了高效的知识检索和准确的问答能力。Tablestore 的 Serverless 特性和向量检索功能进一步增强了系统的扩展性和易用性。开源代码为开发者提供了一个可快速上手的模板,欢迎参考并在此基础上进行功能扩展!
参考文献
- Anthropic, "Model Context Protocol Specification," 2024.
- OpenAI, "Agents SDK with MCP Support," 2025.
- "MCP: A Unified Protocol for AI Agent Development," AI Research Blog, 2024.
- Alibaba Cloud, "Tablestore Overview," https://www.alibabacloud.com/product/tablestore, 2025.
- Alibaba Cloud, "Tablestore Vector Search," https://help.aliyun.com/document_detail/123456.html, 2025.
- Alibaba Cloud, "Tablestore CLI Guide," https://help.aliyun.com/document_detail/654321.html, 2025.
- Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS, 2020.
- Gao et al., "RAG Optimization Techniques," arXiv, 2023.
- Spring AI, "MCP Integration Guide," https://spring.io/projects/spring-ai, 2025.