大家好,我是沛哥儿,很高兴又和大家见面了。
在人工智能的世界里,神经网络如同大脑一般神秘又强大,而其中 **BP 算法(Backpropagation Algorithm)**就是驱动这个 "大脑" 不断学习进化的幕后引擎。

文章目录
- 一、算法的起源与发展
- [二、BP 算法的工作原理](#二、BP 算法的工作原理)
- [三、BP 算法的优势](#三、BP 算法的优势)
- [四、BP 算法的局限](#四、BP 算法的局限)
- 五、改进策略与优化方案
- [六、在 AI 领域的应用实例](#六、在 AI 领域的应用实例)
- 总结
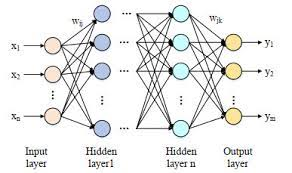
一、算法的起源与发展
BP 算法最早可追溯到 1974 年,由 Paul Werbos 在其博士论文中提出,但当时并未引起广泛关注。直到 1986 年,David Rumelhart、Geoffrey Hinton 和 Ronald Williams 重新阐述了该算法,并证明其能够有效解决多层神经网络的训练问题,才真正让 BP 算法大放异彩。它的出现,打破了神经网络训练的瓶颈,成为连接主义学派的重要里程碑,推动了神经网络从理论走向实际应用。
二、BP 算法的工作原理
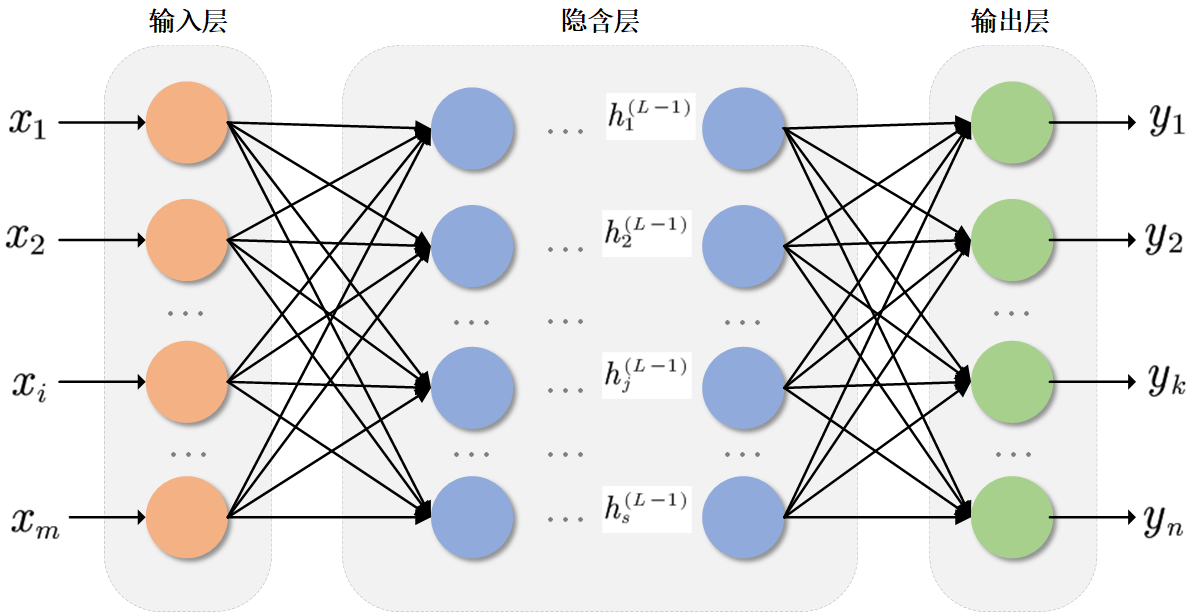
前向传播
前向传播是 BP 算法的 "第一步",它的作用是将输入数据通过神经网络的各层传递,最终得到输出结果。
假设我们有一个简单的三层神经网络,输入层有 n n n个神经元,隐藏层有 m m m个神经元,输出层有 k k k个神经元。输入向量为 x = ( x 1 , x 2 , ⋯ , x n ) T \mathbf{x}=(x_1,x_2,\cdots,x_n)^T x=(x1,x2,⋯,xn)T,隐藏层的权重矩阵为 W ( 1 ) \mathbf{W}^{(1)} W(1),偏置向量为 b ( 1 ) \mathbf{b}^{(1)} b(1);输出层的权重矩阵为 W ( 2 ) \mathbf{W}^{(2)} W(2),偏置向量为 b ( 2 ) \mathbf{b}^{(2)} b(2)。
在隐藏层,输入信号与权重进行加权求和,并加上偏置,然后通过激活函数 f f f进行处理,得到隐藏层的输出 h \mathbf{h} h:
h = f ( W ( 1 ) x + b ( 1 ) ) \mathbf{h} = f(\mathbf{W}^{(1)}\mathbf{x} + \mathbf{b}^{(1)}) h=f(W(1)x+b(1))
常见的激活函数有 Sigmoid 函数、ReLU 函数等。以 Sigmoid 函数为例,其表达式为:
f ( z ) = 1 1 + e − z f(z)=\frac{1}{1 + e^{-z}} f(z)=1+e−z1
接着,隐藏层的输出 h \mathbf{h} h作为输出层的输入,经过类似的加权求和、加偏置和激活函数处理,得到最终的输出 y \mathbf{y} y:
y = g ( W ( 2 ) h + b ( 2 ) ) \mathbf{y} = g(\mathbf{W}^{(2)}\mathbf{h} + \mathbf{b}^{(2)}) y=g(W(2)h+b(2))
下面是用 Python 实现简单前向传播的代码示例:
python
import numpy as np
# 定义Sigmoid激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 输入数据
x = np.array([[0.35], [0.9]])
# 隐藏层权重和偏置
W1 = np.array([[0.1, 0.8], [0.4, 0.6]])
b1 = np.array([[0.3], [0.9]])
# 输出层权重和偏置
W2 = np.array([[0.3, 0.9], [0.2, 0.1]])
b2 = np.array([[0.1], [0.2]])
# 隐藏层计算
h = sigmoid(np.dot(W1, x) + b1)
# 输出层计算
y = sigmoid(np.dot(W2, h) + b2)
print(y)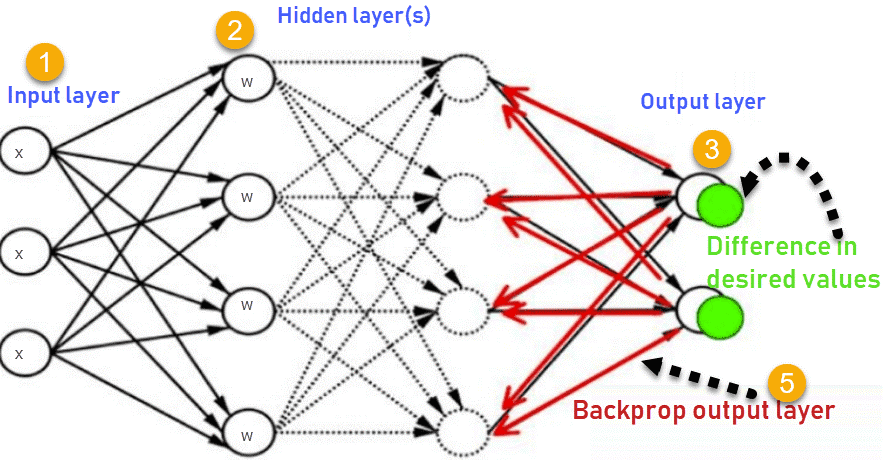
反向传播
当输出结果 y \mathbf{y} y与期望输出 t \mathbf{t} t存在误差时,就需要通过反向传播来调整神经网络的参数。反向传播的核心思想是将误差从输出层反向传递到前面的各层,根据误差对权重和偏置进行调整,使得误差逐渐减小。
计算误差通常使用损失函数,常见的有均方误差(MSE),其公式为:
L = 1 2 ∑ i = 1 k ( t i − y i ) 2 L = \frac{1}{2}\sum_{i = 1}^{k}(t_i - y_i)^2 L=21∑i=1k(ti−yi)2
接下来,通过链式法则计算误差对各层权重和偏置的梯度,以更新参数。例如,输出层权重的更新公式为:
W ( 2 ) = W ( 2 ) − η ∂ L ∂ W ( 2 ) \mathbf{W}^{(2)} = \mathbf{W}^{(2)} - \eta \frac{\partial L}{\partial \mathbf{W}^{(2)}} W(2)=W(2)−η∂W(2)∂L
其中, η \eta η是学习率,控制参数更新的步长。
下面是在上述代码基础上,添加反向传播更新参数的 Python 代码:
python
import numpy as np
# 定义Sigmoid激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 定义Sigmoid函数的导数
def sigmoid_derivative(x):
return x * (1 - x)
# 输入数据
x = np.array([[0.35], [0.9]])
# 期望输出
t = np.array([[0.5], [0.8]])
# 隐藏层权重和偏置
W1 = np.array([[0.1, 0.8], [0.4, 0.6]])
b1 = np.array([[0.3], [0.9]])
# 输出层权重和偏置
W2 = np.array([[0.3, 0.9], [0.2, 0.1]])
b2 = np.array([[0.1], [0.2]])
# 学习率
learning_rate = 0.5
for i in range(10000):
# 前向传播
h = sigmoid(np.dot(W1, x) + b1)
y = sigmoid(np.dot(W2, h) + b2)
# 反向传播
# 计算输出层误差
error = t - y
d_output = error _* sigmoid__derivative(y)
# 计算隐藏层误差
error_hidden = np.dot(W2.T, d_output)
d_hidden = error_hidden * sigmoid_derivative(h)
# 更新权重和偏置
W2 += learning_rate * np.dot(d_output, h.T)
b2 += learning_rate * d_output
W1 += learning_rate * np.dot(d_hidden, x.T)
b1 += learning_rate * d_hidden
print(y)
三、BP 算法的优势
强大的非线性映射能力:能够处理复杂的非线性关系,比如在图像识别中识别各种形状和颜色的物体。
自学习与自适应:无需手动提取特征,通过大量数据训练,自动调整参数适应数据模式。
泛化能力:在训练集上学习到的模式能够较好地应用于新的未知数据。
容错性:即使部分神经元出现故障或数据存在噪声,仍能给出相对合理的输出。

四、BP 算法的局限
训练时间长:当神经网络结构复杂、数据量大时,训练过程可能需要耗费大量时间和计算资源。
易陷入局部极小值:在误差曲面中,算法可能找到局部最优解,而不是全局最优解,导致模型性能不佳。
对初始权重敏感:不同的初始权重可能导致最终训练结果差异很大,需要多次尝试找到合适的初始值。
可能过拟合:在训练数据上表现良好,但在测试数据上泛化能力差。
五、改进策略与优化方案
引入动量项:在权重更新时,加入上一次的更新量,使参数更新更加平滑,避免陷入局部极小值,公式为:
Δ W ( l ) = α Δ W ( l ) − η ∂ L ∂ W ( l ) \Delta \mathbf{W}^{(l)} = \alpha \Delta \mathbf{W}^{(l)} - \eta \frac{\partial L}{\partial \mathbf{W}^{(l)}} ΔW(l)=αΔW(l)−η∂W(l)∂L
其中, α \alpha α是动量因子。
自适应学习率:根据训练过程动态调整学习率,如 Adagrad、Adadelta、RMSProp、Adam 等算法。
正则化技术:如 L1 和 L2 正则化,通过在损失函数中添加正则化项,防止模型过拟合。

六、在 AI 领域的应用实例
图像识别
在 MNIST 手写数字识别任务中,BP 算法可以训练神经网络对 0 - 9 的手写数字进行分类。通过大量的手写数字图像数据训练,网络能够学习到数字的特征,实现高精度的识别。
以下是使用 Keras 库结合 BP 算法实现 MNIST 手写数字识别的简单代码:
python
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.utils import to_categorical
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 784).astype('float32') / 255
x_test = x_test.reshape(-1, 784).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 构建神经网络模型
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=64)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)语音识别
将语音信号转换为文本信息时,BP 算法可训练神经网络学习语音的声学特征和语言模型,实现语音到文字的转换。
代码略
自然语言处理
在文本分类、情感分析等任务中,BP 算法训练的神经网络可以理解文本语义,完成相应的处理任务。
代码略

总结
BP 算法作为神经网络训练的核心算法,凭借其独特的工作原理和强大的学习能力,在人工智能领域发挥着不可替代的作用。虽然它存在一些局限性,但通过不断的改进和优化,依然有着广阔的应用前景。
随着人工智能技术的不断发展,BP 算法也面临着新的机遇和挑战。一方面,在量子计算、神经形态芯片等新技术的支持下,BP 算法的训练效率有望得到大幅提升;另一方面,如何更好地解决局部极小值、过拟合等问题,以及将 BP 算法与其他新兴技术(如强化学习、生成对抗网络)相结合,将是未来研究的重要方向。
所有图片来源网络