目录
-
- 一、引言:打破传统机器学习的"同分布"枷锁
- 二、核心概念:域、任务与迁移学习的定义
-
- [1. 域(Domain)的构成](#1. 域(Domain)的构成)
- [2. 任务(Task)的定义](#2. 任务(Task)的定义)
- [3. 迁移学习的核心定义](#3. 迁移学习的核心定义)
- 三、三大核心设置:归纳、直推与无监督迁移学习
-
- [1. 归纳式迁移学习(Inductive Transfer Learning)](#1. 归纳式迁移学习(Inductive Transfer Learning))
- [2. 直推式迁移学习(Transductive Transfer Learning)](#2. 直推式迁移学习(Transductive Transfer Learning))
- [3. 无监督迁移学习(Unsupervised Transfer Learning)](#3. 无监督迁移学习(Unsupervised Transfer Learning))
- 四、四大迁移策略:实例、特征、参数与关系知识迁移
-
- [1. 实例迁移:数据层面的"择优而用"](#1. 实例迁移:数据层面的“择优而用”)
- [2. 特征表示迁移:构建跨域"通用语言"](#2. 特征表示迁移:构建跨域“通用语言”)
- [3. 参数迁移:模型层面的"知识共享"](#3. 参数迁移:模型层面的“知识共享”)
- [4. 关系知识迁移:复杂结构的"关系映射"](#4. 关系知识迁移:复杂结构的“关系映射”)
- 五、关键挑战:负面迁移与未来研究方向
-
- [1. 负面迁移:迁移不当的"陷阱"](#1. 负面迁移:迁移不当的“陷阱”)
- [2. 未来研究方向](#2. 未来研究方向)
- 六、经典案例:迁移学习如何落地真实场景
-
- [1. 文本分类:跨领域知识复用](#1. 文本分类:跨领域知识复用)
- [2. WiFi定位:动态环境下的模型适配](#2. WiFi定位:动态环境下的模型适配)
- [3. 情感分类:跨产品快速适配](#3. 情感分类:跨产品快速适配)
- 七、总结:迁移学习的"知识迁移"本质
一、引言:打破传统机器学习的"同分布"枷锁
在机器学习的世界里,传统算法有一个根深蒂固的假设:训练数据和测试数据必须来自相同的特征空间,并且服从相同的分布。然而现实场景往往更加复杂:
- 跨领域分类:大学网页分类模型无法直接用于企业网站,因为特征分布差异显著
- 动态环境适配:WiFi信号强度随时间、设备变化,导致定位模型性能衰减
- 数据标注成本:为每个新产品重新标注情感分类数据耗时耗力
这些挑战催生了迁移学习(Transfer Learning)这一全新框架,其核心目标是利用源领域的知识提升目标领域的学习效果,打破"数据同分布"的枷锁。
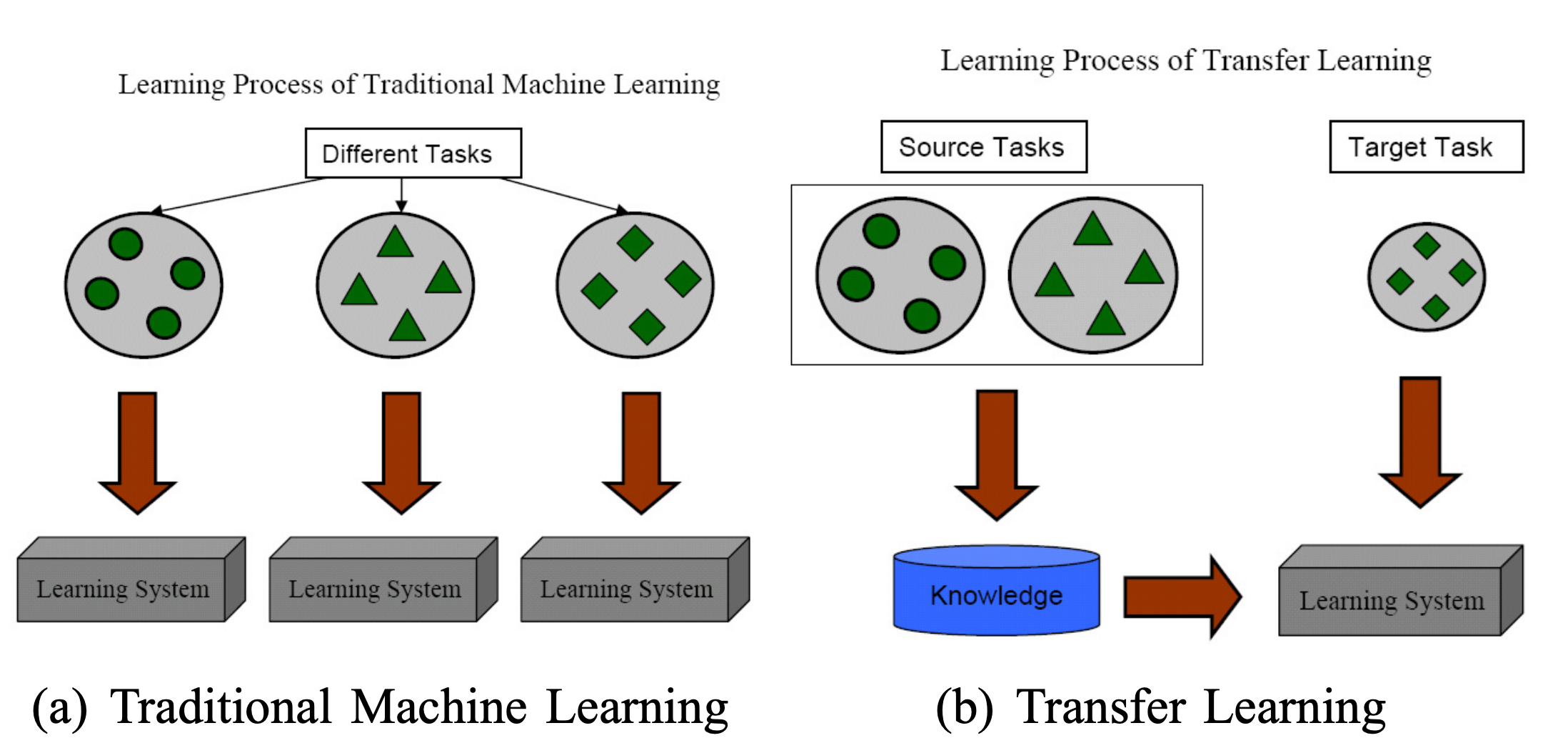
二、核心概念:域、任务与迁移学习的定义
1. 域(Domain)的构成
一个域 D D D 包含两个关键要素:
- 特征空间 X X X:例如文档分类中的词向量空间
- 边缘概率分布 P ( X ) P(X) P(X):不同领域的特征分布可能差异巨大(如中文vs英文文档的词分布)
2. 任务(Task)的定义
任务 T T T 由两部分组成:
- 标签空间 Y Y Y:分类任务的标签集合(如正负情感)
- 目标预测函数 f ( ⋅ ) f(\cdot) f(⋅) :本质是条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)
3. 迁移学习的核心定义
给定源域 D S D_S DS/源任务 T S T_S TS 和目标域 D T D_T DT/目标任务 T T T_T TT,迁移学习旨在利用 D S D_S DS 和 T S T_S TS 的知识,提升目标域预测函数 f T ( ⋅ ) f_T(\cdot) fT(⋅) 的性能,其中 D S ≠ D T D_S \neq D_T DS=DT 或 T S ≠ T T T_S \neq T_T TS=TT。
三、三大核心设置:归纳、直推与无监督迁移学习
根据源域与目标域的关系,迁移学习可分为三大核心设置,下表对比了它们的核心差异:
| 设置 | 源/目标任务关系 | 目标域标签 | 典型场景 |
|---|---|---|---|
| 归纳式迁移学习 | 任务不同( T S ≠ T T T_S \neq T_T TS=TT) | 少量可用 | 跨产品情感分类(标签体系相同但分布不同) |
| 直推式迁移学习 | 任务相同( T S = T T T_S = T_T TS=TT) | 完全不可用 | 跨设备WiFi定位(特征空间相同但分布不同) |
| 无监督迁移学习 | 任务不同 | 完全不可用 | 跨领域聚类(如从图像到文本的特征迁移) |
1. 归纳式迁移学习(Inductive Transfer Learning)
- 核心场景:目标任务与源任务不同,但存在关联(如从图像分类到物体检测)
- 关键假设:目标域有少量标签数据,源域有大量标签/无标签数据
- 典型算法 :
- TrAdaBoost:通过迭代重加权源域数据,抑制"坏样本"影响(类似AdaBoost扩展)
- 稀疏特征学习:利用源域数据学习共享特征表示(如稀疏编码提取高层特征)
2. 直推式迁移学习(Transductive Transfer Learning)
- 核心场景:任务相同但域不同(如跨语言文本分类)
- 关键假设:目标域无标签数据可在训练时获取(类似半监督学习)
- 典型算法 :
- 核均值匹配(KMM):通过再生核希尔伯特空间(RKHS)匹配源/目标域数据分布
- 结构对应学习(SCL):利用" pivot features"构建跨域特征对应关系(如自然语言处理中的词性标签)
3. 无监督迁移学习(Unsupervised Transfer Learning)
- 核心场景:无标签数据场景下的跨域学习(如跨模态数据聚类)
- 关键挑战:需从无标签数据中挖掘跨域共享特征
- 典型算法 :
- 自教聚类(STC):通过互信息最大化学习跨域共享特征空间
- 迁移判别分析(TDA):迭代生成伪标签进行降维迁移
四、四大迁移策略:实例、特征、参数与关系知识迁移
根据"迁移什么",迁移学习可分为四大策略,下表总结了各自的核心思想与适用场景:
| 策略 | 迁移对象 | 核心技术 | 典型应用 |
|---|---|---|---|
| 实例迁移 | 源域数据实例 | 重加权、重要性采样 | 跨领域文本分类(如20 Newsgroups数据集) |
| 特征表示迁移 | 共享特征空间 | 稀疏编码、流形对齐 | 图像/视频跨域识别(如域适应问题) |
| 参数迁移 | 模型参数/先验 | 多任务学习、贝叶斯共享 | 多语言模型参数迁移(如BERT跨语言版本) |
| 关系知识迁移 | 数据间关系 | 马尔可夫逻辑网络 | 社交网络分析、知识图谱迁移 |
1. 实例迁移:数据层面的"择优而用"
- 核心思想:并非所有源域数据都对目标域有用,通过权重调整筛选"优质实例"
- 关键技术 :
- 重要性采样 :根据 P ( X S ) / P ( X T ) P(X_S)/P(X_T) P(XS)/P(XT) 计算实例权重,平衡分布差异
- TrAdaBoost算法:迭代提升中动态调整源域样本权重,聚焦目标域难分样本
2. 特征表示迁移:构建跨域"通用语言"
- 核心思想:学习与领域无关的通用特征表示,降低域间差异
- 技术分类 :
- 监督式:利用源域标签学习共享特征(如多任务学习中的稀疏特征提取)
- 无监督式:通过自编码器、稀疏编码等无标签方法学习高层特征(如Raina等人的自教学习)
- 流形对齐:对齐源/目标域流形结构(如Procrustes分析实现无对应点流形对齐)
3. 参数迁移:模型层面的"知识共享"
- 核心思想:共享模型参数或先验分布,适用于任务相关但数据分布不同的场景
- 典型方法 :
- 多任务学习扩展 :将源/目标任务参数分解为共享部分( w 0 w_0 w0)和任务特定部分( v S , v T v_S, v_T vS,vT)
- 贝叶斯框架:通过层次化先验建模任务间依赖(如高斯过程多任务学习MT-IVM)
4. 关系知识迁移:复杂结构的"关系映射"
- 核心场景:处理非独立同分布(non-iid)的关系数据(如社交网络、知识图谱)
- 关键技术 :
- 马尔可夫逻辑网络(MLN):通过谓词逻辑映射源/目标域实体关系(如教授-学生关系到经理-员工关系)
- 二阶马尔可夫逻辑:发现结构规律并迁移到目标域谓词实例
五、关键挑战:负面迁移与未来研究方向
1. 负面迁移:迁移不当的"陷阱"
- 定义:源域知识反而降低目标域性能的现象(如领域无关的噪声数据干扰)
- 成因 :
- 源/目标域差异过大(如文本分类中跨语言且无共享特征)
- 迁移策略不当(如错误保留源域特有噪声特征)
- 应对思路 :
- 领域相关性度量(如基于Kolmogorov复杂度的任务关联度分析)
- 动态权重调整(如根据目标域验证集效果自适应调整源域权重)
2. 未来研究方向
- 异构迁移学习:跨越不同特征空间的迁移(如图像→文本跨模态迁移)
- 大规模应用:从文本分类、定位等小场景扩展到视频分析、社交网络挖掘
- 自动化迁移:无需人工领域知识的自适应性迁移(如元学习驱动的迁移策略)
- 理论边界:明确迁移学习的性能上限与适用条件(如基于VC维的泛化误差分析)
六、经典案例:迁移学习如何落地真实场景
1. 文本分类:跨领域知识复用
- 场景:从大学网页分类模型迁移到企业网站分类
- 挑战:特征分布差异(学术术语vs商业术语)
- 解决方案 :
- 实例迁移:通过TrAdaBoost重加权源域文档
- 特征迁移:利用稀疏编码学习跨领域通用词向量表示
2. WiFi定位:动态环境下的模型适配
- 场景:同一地点不同时间的信号分布变化导致定位模型失效
- 挑战:信号强度受设备、时间影响,分布漂移显著
- 解决方案 :
- 直推式迁移:利用当前时刻无标签信号数据,通过KMM匹配历史数据分布
- 参数迁移:共享不同时间/设备模型的底层特征提取参数
3. 情感分类:跨产品快速适配
- 场景:从手机评论分类模型迁移到相机评论分类
- 挑战:产品相关词汇差异大,重新标注成本高
- 解决方案 :
- 特征表示迁移:通过结构对应学习(SCL)提取跨产品的情感极性通用特征(如"好/坏"等情感词)
七、总结:迁移学习的"知识迁移"本质
迁移学习的核心价值在于打破数据壁垒,让机器学习系统具备"举一反三"的能力。从实例层面的样本筛选,到特征层面的通用表示,再到模型层面的参数共享,迁移学习通过不同策略实现了跨域知识的有效复用。随着异构迁移、自动化策略等方向的突破,这一技术将在更多复杂场景中发挥关键作用,成为构建智能系统的重要基石。