✳️ 引言:AIGC,正在重构视觉智能的"生成逻辑"
AI生成内容(AIGC)正在从"内容创作工具"跃升为计算机视觉系统的新引擎。它不再只是"文生图"、"图生文"的演示技术,而是实实在在地改变着我们构建、处理和理解视觉数据的方式。
从智能安防到虚拟现实,从工业质检到数字孪生,视觉系统正在经历一次从"被动采集"到"主动生成"的范式跃迁。生成模型让计算机不仅能"看懂世界",更具备"重构世界"的能力。
在这个过程中,视频数据不再只是模型的输入源,更成为驱动生成、交互和控制的核心素材 。这要求底层视觉通道必须具备高效、稳定、低延迟的特性,以支撑大模型实时推理与反馈。
作为一款专注于跨平台、低延迟、工业级视频接入的中间件,大牛直播SDK 正在成为连接真实世界与生成智能之间的"感官通路",让每一帧实时视频都具备可理解、可生成、可反馈的能力,为AIGC时代的视觉系统构筑基础设施。
🧩 一、AIGC对传统计算机视觉体系的冲击与重塑
AIGC(AI-Generated Content)正以前所未有的方式,深度改变着计算机视觉系统的设计逻辑与能力边界。传统视觉体系长期以来以"感知与识别"为核心,强调如何高效提取图像特征、理解场景语义,并将视觉信息输入下游决策模块。而AIGC的引入,让视觉系统具备了"内容生成"与"场景建构"的能力,形成了从感知 → 表达 → 创造的新型闭环。
🔄 模式迁移:从识别世界到重构世界
| 传统视觉路径 | AIGC增强路径 | 能力演化方向 |
|---|---|---|
| 图像识别(Object Detection) | 语义生成(Image Captioning, Diffusion) | 从识别"是什么"到表达"是什么样" |
| 视频分析(Action Recognition) | 视频生成(Image-to-Video, Prompt-to-Video) | 从理解行为到重建动态场景 |
| 缺陷检测(Quality Inspection) | 异常合成 + 对比生成 | 从被动比对到主动预演与判别 |
| 3D建模(SLAM / Photogrammetry) | 文本驱动建模(Text-to-3D) | 从点云构造到语义建模 |
| 多模态融合(图+语+声) | 联合生成(Multimodal Generation) | 从数据对齐到内容协同生成 |
AIGC 的本质冲击,不仅体现在模型层面,更在于它迫使我们重新设计视觉系统的输入输出边界,并提出了对视频链路时效性、稳定性、交互性的更高要求。
📌 趋势洞察
-
视觉系统正从"解释现实"向"生成现实"演进
-
内容生成能力正在成为视觉智能的"核心输出之一"
-
实时视频数据成为AIGC模型与真实世界互动的关键桥梁
🚀 三、大牛直播SDK:构建视频-AI生成间的实时感知通路
✅ 技术特点
| 能力 | 描述 |
|---|---|
| 🔴 实时推拉流支持 | 支持 RTSP / RTMP / GB28181 等协议,毫秒级低延迟 |
| 🟢 跨平台支持 | 覆盖 Android / iOS / Windows / Linux / Unity3D |
| 🔵 本地录像 / 快照 / 水印处理 | 支持边缘侧智能终端数据留存 |
| 🟣 多通路并发 | 支持多路推流、多实例播放,适配 AIGC 模型多流输入需求 |
| 🟡 GPU/OpenGL渲染加速 | 提升视频处理效率,适配图像生成任务 |
📦 示例集成路径
以 YOLO + Sora + 大牛直播SDK 为例构建链路:
css
[摄像头采集] → 大牛SDK RTSP服务 → AI视觉模型识别(YOLO)+ AIGC生成(Sora) → 业务反馈控制可支持以下典型能力:
-
模型生成缺失画面 → 实时插帧补全
-
多模态理解 → 语音/图像协同感知
-
视频转3D语义 → 虚拟场景构建
🔍 四、典型落地场景:AIGC × 实时视频,如何重塑行业应用?
AIGC 与实时视频感知的结合,正在重构多个行业的感知---理解---决策链条。传统视觉系统往往以"识别"为终点,而引入 AIGC 后,视觉系统开始具备"生成---预测---重构"能力,显著提升了智能体的响应效率与场景适应性。
以下是几个关键行业中,这一技术融合所带来的本质性转变:
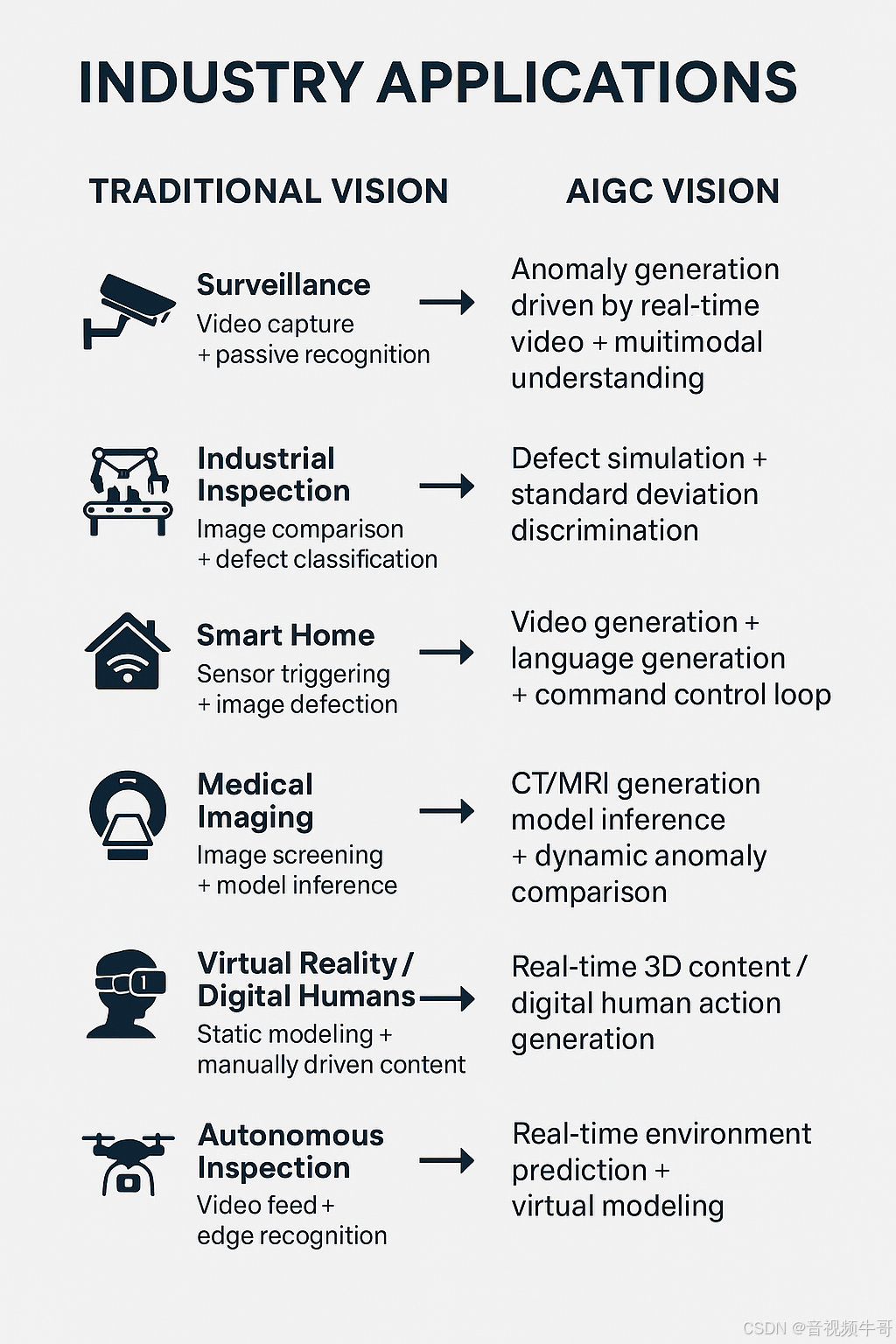
| 行业场景 | 传统视觉逻辑 | AIGC融合后的新范式 | 技术价值提升 |
|---|---|---|---|
| 🛡️ 安防监控 | 视频采集 + 被动识别 | 实时视频驱动的异常生成 + 多模态语义理解 | 告警更早、误报更低、语义更清晰 |
| 🏭 工业质检 | 图像比对 + 缺陷分类 | 缺陷模拟生成 + 标准差异判别 | 缺陷识别泛化强、支持小样本学习 |
| 🏠 智能家居 | 传感器触发 + 图像检测 | 视频生成+语言生成+指令控制闭环 | 实现更自然的人机交互与主动响应 |
| 🧠 医疗辅助诊断 | 图像筛查 + 模型推理 | CT/MRI 生成增强 + 动态异常对比 | 更强诊断支持,适配多模态医影场景 |
| 🎮 虚拟现实 / 数字人 | 静态建模 + 手工驱动内容 | 实时生成3D内容 / 数字人动作 | 降低制作成本,实现智能内容互动 |
| 🛰️ 无人设备 / 巡检 | 视频回传 + 边缘识别 | 实时视频生成环境预测 + 虚拟建模 | 路径预判更精准,支持极端环境模拟 |
📌 场景共性总结:
-
从"记录事实"到"生成语义":视频数据不仅是感知来源,也是可控生成的语义源泉。
-
从"事后处理"到"实时互动":AIGC加持下的视频系统具备即时反馈与推理能力,适配更多闭环控制系统。
-
从"数据孤岛"到"多模态协同":视频、语音、文本、3D 数据通过生成模型汇聚统一语义空间,支持更复杂的交互行为。
⚙️ 大牛直播SDK在场景中的作用
Windows平台 RTSP vs RTMP播放器延迟大比拼
在上述各类场景中,大牛直播SDK 提供了稳定、高效、低延迟的视频数据通路,满足 AIGC 模型对输入质量、延迟容忍度、协议多样性等方面的要求:
-
实时视频采集与编码 → 提供清晰、高帧率画面
-
多协议推流与播放 → 适配边缘与云端模型协同部署
-
本地存储与快照 → 支持生成模型回溯与对比
-
跨平台兼容 → 可嵌入无人机、工业设备、头显终端等
Android平台Unity共享纹理模式RTMP播放延迟测试
🌐 五、系统架构示意图(AIGC × 视频SDK)
css
┌──────────────┐
│ 摄像头 Sensor│
└─────┬────────┘
▼
┌─────────────┐
│ 大牛直播SDK │───► 支持实时视频推送/播放/转码
└─────┬───────┘
▼
┌──────────── AI分析引擎 ─────────────┐
│ YOLO、OpenCV、MMDetection等 │
│ ↘ 多模态生成模型(如Sora、LLaVA │
└────────────┬──────────────────────┘
▼
业务逻辑 / 控制系统🔚 总结与展望:视频是生成智能的"感官延伸"
AI生成能力的增强,正在倒逼视觉系统从"输入型管道"升级为"交互型神经"。视频,不再是只能采集和识别的静态介质,而是可被"理解、生成、反馈"的多模态入口。
大牛直播SDK 提供的实时视频接入、推流、播放、渲染等能力,正成为这一新时代中 AI 系统的视觉"神经元通道"。
✅ 视频,是AIGC的感官延伸;
✅ 大牛直播SDK,是这条感官神经的通路核心;
✅ 让每一帧数据都具备生成能力,让每一次生成都能即时呈现。
未来,AIGC 与实时视觉的深度融合,将催生更多前所未有的应用形态------从生成内容,到生成现实。
📎 CSDN官方博客:音视频牛哥-CSDN博客****