🌸作者主页:努力努力再努力wz



💪 今日博客励志语录 :
与其等待完美的风,不如学会在逆风中调整帆的角度------所有伟大航程都始于'此刻出发'的勇气
★★★ 本文前置知识:
匿名管道
前置知识大致回顾(对此十分熟悉的读者可以跳过)
那么在之前的一期博客中,我们主要关注的是父子进程之间如何进行通信,由于进程之间具有独立性,意味着进程之间无法直接访问对方的页表以及task_struct结构体来获取对方的数据,那么操作系统为了保证进程之间的独立性又要满足进程之间通信的需求,那么操作系统让进程能够通信的核心思想就是创建一块公共区域,那么一个进程向这块公共区域写入,那么另一个进程从这块公共区域来读取即可,那么对于父子进程来来说,由于调用fork接口创建子进程的过程中,其中会涉及到拷贝父进程的task_struct结构体,然后修改其中部分属性得到子进程的task_struct结构体,那么意味着子进程会拷贝父进程的文件描述表,那么子进程就可以继承父进程打开的文件,而操作系统让进程之间通信的核心思想就是创建一块公共的区域,那么对于父子进程来说,那么这个公共的区域就可以通过文件来实现,所以父进程可以打开一个文件,然后再创建子进程,那么子进程就会继承并且和父进程共享该被打开的文件
那么这里要注意的是,父子进程通过文件来进行通信的时候,那么不能双方都同时对该文件进行读和写,否则会遭成文件的偏移量的错位以及文件内容的混乱,所以父子进程通过文件来通信的时候,只能单向通信,也就是一个进程往该文件中写入,另一个进程从该文件中读取,其次就是该文件只是用来保存父子进程通信的过程中的一个临时数据,那么不需要刷新到磁盘中来长期存储,那么必然该文件就得是一个内存级别的文件,而刚才说的这些,就是父子进程通信所需要的文件要满足的特点,分别是单向通信以及是它得是一个内存级别的文件,而该文件就是匿名管道文件,那么要创建匿名管道文件就需要pipe系统调用接口
那么这就是前置知识的大致回顾,如果对此内容感到不熟悉或者遗忘的读者,可以去看看我上一期博客
命名管道
认识命名管道
1.什么是命名管道
那么我们知道了父子进程如何进行通信,而今天这期博客围绕则是非父子进程之间如何进行通信,那么有了父子进程通信的经验,那么关于如何实现非父子进程之间的通信其实并不复杂,我们知道父子进程通信是通过文件作为载体,文件保存的就是父子进程通信的内容,那么同样对于非父子进程来说,那么要实现通信,第一步还是得找到一块公共的内存区域,那么这个内存区域依然是通过文件来作为载体,只不过这里的文件和之前的父子进程通信所采取的匿名管道文件会有一些区别,那么这个区别从该文件的名字:命名管道,就能够得知,该文件是有"名字的",那么这个所谓的名字指的就是路径名以及文件名
而对于匿名管道来说,之所以它可以没有文件名以及路径名,是因为子进程的文件描述表是通过拷贝父进程的文件描述表得到的,那么意味着父子进程的文件描述表是相同的,所以父子进程来访问管道文件不需要所谓的路径以及文件名,那么只需要通过文件描述符就能够从匿名管道文件中写入或者读取内容
但是对于非父子进程来说,由于进程之间具有独立性,那么非父子进程不可能照搬父子进程的那套做法,因为陌生进程之间是无法访问彼此的文件描述表以及页表等结构的,所以非父子进程通信,那么采取的方式就是创建一个普通文件,那么一个进程向该普通文件做写入,另一个进程从该普通文件中进行读取,但是该普通文件是一个特殊的普通文件,那么有了父子进程通信的经验,我们也能够知道,该普通文件一定得是一个内存级别的文件,那么它不会将内容刷新到磁盘中,因为该文件是用来临时保存进程之间通信的内容
那么对于非父子进程来说,那么他们要向该命名管道文件进行读取以及写入,那么此时就和我们进程向一个普通文件进行读取和写入的过程是一样的,也就是两个通信的进程需要调用open接口分别一个以只读来打开该命名管道文件,另一个以只写来打开该命名管道文件,那么此时操纵系统会创建该命名管道文件的file结构体,并且扫描进程的文件描述表,然后从文件描述表的起始位置往后线性扫描分配一个最小的未被使用的文件描述符然后返回,之后我们就可以通过open接口返回的文件描述符来调用相应的write接口以及read接口来实现非父子进程的通信了
那么这些步骤实现的前提得是我们得先创建一个命名管道文件,那么创建匿名管道文件,操作系统为我们提供了pipe接口,而对于命名管道文件的创建,那么操作系统则为我们提供了mkfifo接口,那么mkfifo接口则是会接收两个参数分别是你要打开的管道文件的路径加文件名的一个c风格的字符串以及该管道文件对应的一个权限
mkfifo头文件:unistd.h函数声明:int mkfifo(const char* pathname,mode_t mode);返回值:调用成功返回0,调用失败则返回-1
那么mkfifo的第一个参数则是接收一个带有文件路径以及文件名的字符串,那么mkfifo会创建该文件对应的inode结构体,因为管道文件本质上也是一个普通文件,那么既然是一个文件,那么它一定是由两部分所组成的,分别是文件的属性以及文件的内容,而文件的属性则是记录在inode结构体中,而上文我埋了一个伏笔,也就是说管道文件是一个特殊的普通文件,那么之所以说它特殊,就是因为它是一个内存级别的文件,那么这点和匿名管道文件是一致的,那么它的文件内容只是保存进程通信写入的临时数据,不需要加载到磁盘中,所以磁盘没有其对应的映射,但是我们如果输入一个指令:ls -li,那么该指令是查询文件的inode编号,那么现在我创建了一个管道文件,然后接着我输入该指令来查询该管道文件的inode编号,我们会发现该管道文件竟然有对应的inode编号,其inode编号是918097

而之前学习文件系统的时候,我们知道操作系统为了管理磁盘这个外部设备,那么为磁盘建立了一个一维的线性数组的逻辑映射,那么该一维线性数组的每一个元素就是由几个磁盘的基本存储单元也就是扇区组合而成的逻辑块,并且由于磁盘容量极大,那么操作系统为了便于管理,将该一维的线性数组进行分区管理,对于每一个区又进行更为细致的划分,分成了不同的块组,而这里为了区分在同一个分区中不同位置的逻辑块,那么这里就会以逻辑块的数组下标作为标识符,那么该标识符就是是逻辑块的逻辑地址,那么知道了该逻辑块的逻辑地址,那么内核会通过特定的算法将其转换磁盘中的物理地址从而来定位获取数据,而所谓的inode编号就是其中inode对应的逻辑块的逻辑地址,所以只要我们知道一个文件的inode编号,那么我们就可以将inode编号转化为其在磁盘中的物理地址,并且inode结构体中还有其相关联的数据块的索引数组,那么意味着只要你持有该文件对应的inode编号,那么你就能够同时获取其文件在磁盘中的inode逻辑块以及数据块
所以这里可能有的读者会觉得有点矛盾,因为我这里命名管道文件不是内存级别文件吗?按照道理来说,命名管道文件在磁盘中没有对应的映射,因为我压根就不需要将数据刷新到磁盘中去,所以不需要inode编号,因为inode编号的作用就是会转化为磁盘中的物理地址来定位数据,但事实是命名管道文件确实有对应的inode编号,那么岂不是有点矛盾?
那么对于有该疑问的读者,我想回答的就是:确实命名管道文件在磁盘中没有对应的映射,但是没有对应的映射不代表其就没有inode编号,或者换句话说,此时对于管道文件来说,那么它的inode编号的作用不是用来转换为物理地址定位到磁盘,而仅仅是作为一个标识符:
那么不知道读者有没有想过一个问题,那么就是我如果在代码中多次调用open接口打开同一个文件,那么此时该代码能否成功能否成功运行,也就是是否能够成功多次打开同一个文件
cpp
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
int main()
{
int fd1=open("log.txt",O_RDONLY|O_CREAT,0666);
int fd2=open("log.txt",O_RDONLY);
int fd3=open("log.txt",O_WRONLY);
printf("fd1:%d fd2:%d fd3:%d\n",fd1,fd2,fd3);
return 0;
}
那么根据结果,答案显而易见,而我们知道open接口背后涉及到工作不仅仅要为该文件创建file结构体,并且还要为进程分配文件描述符,但其中最关键的是,如果该文件是第一次打开的话,那么它还会将其在磁盘中的数据给加载到内存中
那么按照我们的上面的代码的逻辑的话,那么这里我们调用三次open接口,并且三次都是打开同一个文件,那么此时操作系统会不会将该文件的在磁盘当中的元数据加载三份到内存中,那么这个问题,不用想,操作系统肯定不会这么做,因为我们要记住一句话,那就是操作系统绝对不会干一些低效且没有意义的工作,如果操作系统做了,那么这就是操作系统的bug
所以意味着上面调用了三次open接口来打来log.txt,但是实际上log.txt的元数据肯定只会加载一份到内存,说明操作系统肯定有某种机制,能够知道该文件的元数据已经加载一份到内存了,操作系统会通过内核中会维护的一个哈希表的数据结构来实现这个机制,那么该哈希表就是以<inode编号,文件系统>作为键值,那么由于每一个文件可以有多个file结构体,但是它只能有一个inode结构体,也就意味该文件只能对应一个inode编号,那么inode编号在这里的作用就是最为键的一部分来查找该文件是否被加载到内存,那么其对应的val值则是inode结构体
所以这里不管你是什么类型的文件,是普通文件也好还是管道文件也好,那么它必须都得有inode编号来作为标识,只不过对于普通文件来说,那么inode编号还有一个作用就是可以定位在磁盘中的物理位置,而对于内存级别的管道文件来说,那么它的作用仅仅就是作为一个标识符
2.命名管道与匿名管道文件的区别
那么这里知道了命名管道的概念之后,那么我们再来与匿名管道文件进行一个对比
1.生命周期
那么对于匿名管道来说,那么它由于没有文件名以及路径名,所以它没有所谓的硬链接,因为硬链接本质就是目录文件中的一个目录项,而目录项的内容就是文件名与其对应的inode编号的映射,所以匿名管道的硬链接数为0,所以一旦进程退出,那么此时操作系统会清理进程的文件描述表中打开的所有文件,那么匿名管道的引用计数会被清零,而操纵系统清理该文件的资源的前提就是没有进程打开该文件特就是该文件的引用计数为0,并且还要该文件的硬链接数为0,那么系统才会最终清理该文件的inode以及对应的内存块,所以最终匿名管道会被清理,匿名管道的生命周期和进程的生命周期一样
而对于命名管道来说,那么它的生命周期则不是和进程的生命周期一致,那么如果我们没有显示删除该文件,那么该文件将会一直存在,因为虽然的它的引用计数为0,但是硬链接数不为0,那么命名管道对应的inode以及页缓存不会被清理
2.内存级别文件
那么命名管道和匿名管道都是内存级别的文件,意味着它们在磁盘中没有对应的映射,并且他们都是采取环形缓存的一个结构,那么这点匿名管道和命名管道是一致的
自己实现一个命名管道
那么上文我们有了命名管道的知识之后,那么我们可以自己来实现一个用命令管道来通信的一个小项目,那么这里我先来梳理一下这个项目的大致实现思路,也就是梳理分析出该项目会涉及到的各个模块,那么模块梳理完之后,我们再来谈谈具体的实现细节
大致框架
server进程/client进程介绍
那么这里我们要来应用命名管道的场景,那么肯定得有两个非父子进程,那么这里我准备了两个进程,分别是server进程以及client进程,那么server进程的任务就是来创建命名管道文件,并且它是作为该命名管道管道文件的写端,并且还要完成清理管道文件的任务,而client进程则是读取server进程想管道文件写入的内容
server的各个模块
1.创建管道文件
那么首先server对应的源文件中会调用mkfifo接口来创建一个管道文件,那么这里由于server源文件以及client对应的源文件到时候都得调用open接口来打开该管道文件的各自的读写端,所以这里我们会将命名管道文件的路径以及文件名给封装到一个FIFO.hpp头文件中,然后server以及client会各自引用该头文件,从而能够获取该命名管道的路径以及文件名
2.打开管道文件的写端
那么对于server创建完管道文件之后,那么接着下一步就是调用open接口以及只写权限来打开该管道文件,然后获取到该管道文件的写端的文件描述符
3.向管道文件写入
那么获取到管道文件的写端的文件描述符之后,那么接下来我们就是向该管道文件写入消息,那么这里我们将写入的逻辑封装到一个死循环中,并且我们到时候在消息被写入到管道文件之前,那么我们会对消息的内容进行一个解析,由于我们将写入逻辑封装到一个死循环当中,那么到时候我们肯定通过某个特殊的消息或者说字符串,那么该消息不是写入到管道文件当中,而是作为循环的退出条件,所以我们会对写入的字符串进行一个判断,然后判断完不是特殊消息,那么再调用write接口将其写入到管道文件中
4.清理管道文件
那么通信结束后,那么我们需要清理管道文件,其中就包括关闭管道文件的写端的文件描述符以及删除其对应的硬链接,因为一个文件真正被操作系统删除的前提条件是当前没有进程打开它,也就是它的引用计数为0,并且还要满足它的硬链接数为0,而硬链接的本质就是该命名官大文件所处的目录文件中有记录该文件的文件名以及其inode编号的映射的目录项,那么我们要删除该目录项,那么就需要调用unlink接口
unlink头文件:unistd.h函数声明:int unlink(const char* pathname);返回值:调用成功返回0,调用失败则返回-1
client的各个模块
1.打开管道文件的写端
那么在上文我们就说过client对应的源文件会引用一个FIFO.hppd的头文件,那么该头文件会包含管道文件的路径名以及文件名,那么这里client会获取到管道文件的路径以及文件名,那么首先会调用open接口来打开该管道文件,来获取该管道文件的写端的文件描述符
2.读取管道文件
那么这里和上面server写入管道文件的逻辑一样,这里我们还是将管道文件的读取给封装到一个死循环的逻辑中,由于在上一个环节我们已经获取了管道文件的读端的文件描述符,那么这里我们只需要调用read接口来读取管道文件的内容,那么这里我们还要获取read接口的返回值,因为如果管道文件的写端已经被关闭,那么此时read会返回0,而我们此时read是封装在一个死循环的逻辑中,意味着会不断的读取管道文件中的内容,那么read接口返回0就代表着写端关闭,那么不用再读取,即退出循环
3.清理管道文件
那么对于client对应源文件来说,那么它只需要关闭管道文件的读端即可,因为硬链接的关闭已经交给了server来做,所以这里只需关闭读端然后正常退出即可
具体各个模块的实现
前置准备知识
1.日志
那么这里我们在实现的时候就得引入一个日志的概念,日志还有另一个我们更为熟悉的名字,那么便是日记,那么我们知道日记的作用就是记录我们每天的日常生活,而对于计算机的日志来说,那么它的作用便是记录程序运行的某个具体时刻下该程序的某个模块的运行结果,那么这个结果可以打印展示到终端也就是显示屏或者输入到文件当中,那么日志的作用就是实时来监控程序运行时的每一个模块的在不同时刻的状态,那么我们可以通过其输出的一条条日志信息来进行获取其状态
而一条日志信息会包含三个部分内容,分别是日志的等级以及具体时刻和用户自动定义部分
那么先说日志的等级,日志的等级反映了该模块的运行结果的情况,那么它究竟是正常运行还是异常运行,那么就可以通过日志等级来进行反应,那么日志等级具体可以分为以下几种:
info:常规消息debug:调试消息warning:警告消息Fatial:致命消息
那么info等级则是反应我们该模块运行正常,而debug则是代表该日志信息的作用是用来调试从而输出的,而warning则反映了该模块虽然能正常运行,但是可能其中的过程有错误,而Fatial则是代表着当前程序运行到这里时候,无法在继续正常运行了,说明程序在此处遇到了严重的错误
而日志还得包含时间,代表着当前程序在什么时刻运行的
而日志消息的第三部内容则是用户自定义的内容,那么用户可以传递一些比如用于调试的信息,那么这部分都属于自定义部分
2.可变参数
那么这里还得引入一个可变参数的概念,因为到时候日志系统打印用户自定义部分的时候需要用到可变参数,那么要搞懂可变参数,那么首先就得对函数栈帧这个结构有着清晰的认识,那么我们知道当我们调用一个函数的时候,那么底层要设计到的工作就包括在栈区上为该函数创建一份空间,那么我们的栈区是由高地址向低地址分布,那么函数栈帧的分布则是从高地址往下依次创建一个一个函数的栈帧
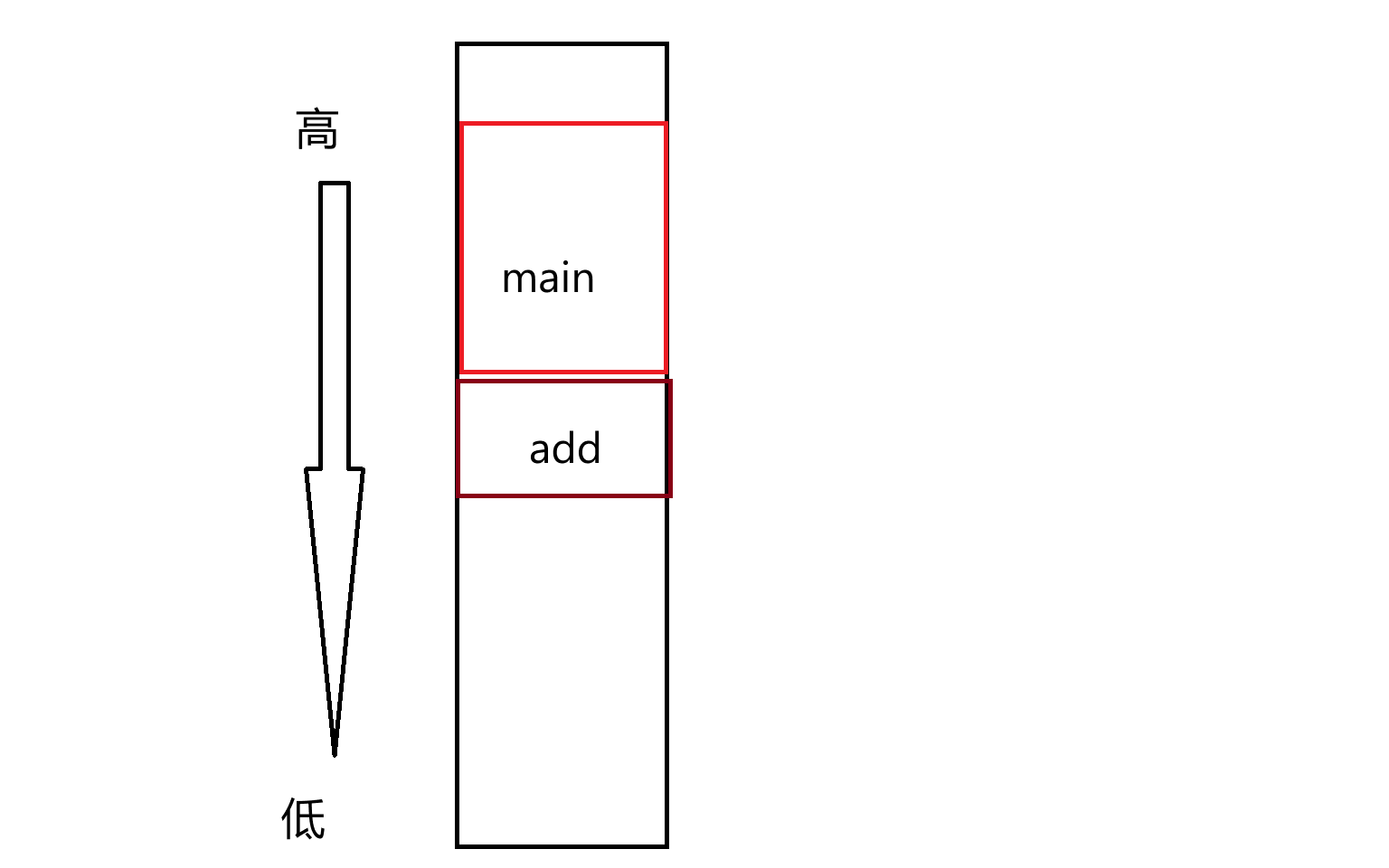
而函数栈帧的维护就需要涉及到CPU的两个寄存器,分别是ebp以及esp寄存器,ebp指向函数栈帧的栈底处也就是函数栈帧的起始位置处,而esp则是指向函数栈帧的栈顶处,那么ebp与esp之间的这块连续区域,维护的就是一个函数的栈帧,那么假设在该函数中调用了一个新的函数,那么此时ebp与esp就要去维护新的函数的栈帧,那么由于esp以及ebp的容量只有几字节,意味着他们只能存储一个有效地址,所以在创建函数栈帧之前,那么调用者函数内部会首先做一个准备工作,那么就是它会先将传入给被调用者函数的参数给先压入栈中,那么压入的位置就是从esp保存的地址开始依次往后压入,并且压参的顺序,是从右往左从esp位置处往低地址处依次压入,比如调用了add(x,y)函数,那么此时调用者函数会将y先压入,然后在压入参数x
高地址 → 低地址
参数y \] \[参数 x\] \[返回地址
那么压完参数之后,接着还会压入调用该函数的下一条指令的地址,那么这就是调用者函数所做的内容
而对于被调用者函数来说,那它所做的就是首先将旧的ebp的值给压入,因为ebp以及esp一次只能维护一个栈帧,那么这里当该被调用者函数调用结束,那么此时要回到调用者函数,那么此时就需要恢复ebp,所以这里会将原本的ebp的值给压栈,那么压完旧的ebp之后,此时esp就会把值赋给ebp,让ebp此时指向被调用者函数的栈底,然后esp往后移动固定的单位长度,这个单位长度则取决于编译器,那么一般在vs下该长度为0E4h,那么此时esp以及ebp之间的这块连续的大小为0E4h长度的空间就是给被调用者函数的局部变量所分配的空间,那么一旦函数调用结束,此时就会清理被调用者函数的栈帧,那么这个时候,会将ebp的值设置给esp,然后再将之前压入的旧的ebp的值给弹出赋给ebp,然后让ebp重新指向调用者函数栈帧的起始位置
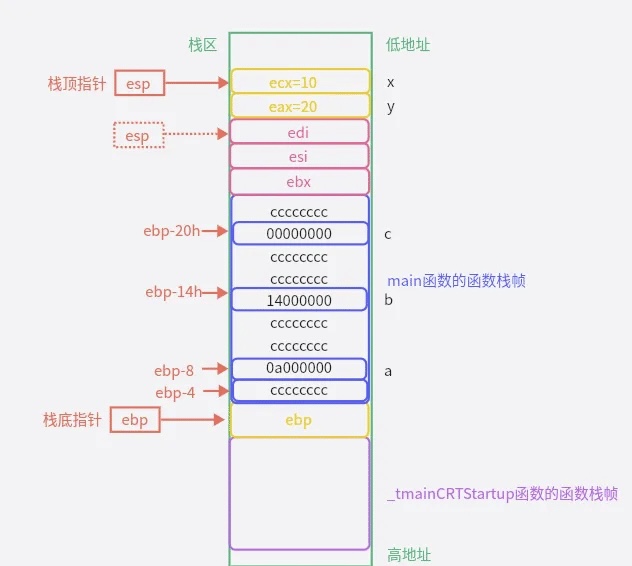
那么以上就是函数栈帧的结构以及创建和销毁的一个大致的流程
那么从上文,我们就可以认识到函数在被调用的时候,那么它的参数是从右往左依次压栈的,那么在以前的编译器下,那么会允许能这么调用函数,就是你可以定义一个函数,然后当你调用这个函数的时候,你实际传递的实参的数量是可以大于函数定义的形参的数量,那么编译器不会给你报一个Error too many arguments to function 的编译错误,因为以前的编译器它支持可变参数,甚至支持我们自己来通过指针来访问可变参数,因为我们上文说过,当调用函数的时候,那么调用者函数是会将传递给被调用者的参数从右往左依次压栈,那么第一个参数也就是最左侧的参数是最后压入的,那么它一定位于这些的参数的最下方,因为参数压栈是从高往下依次压栈
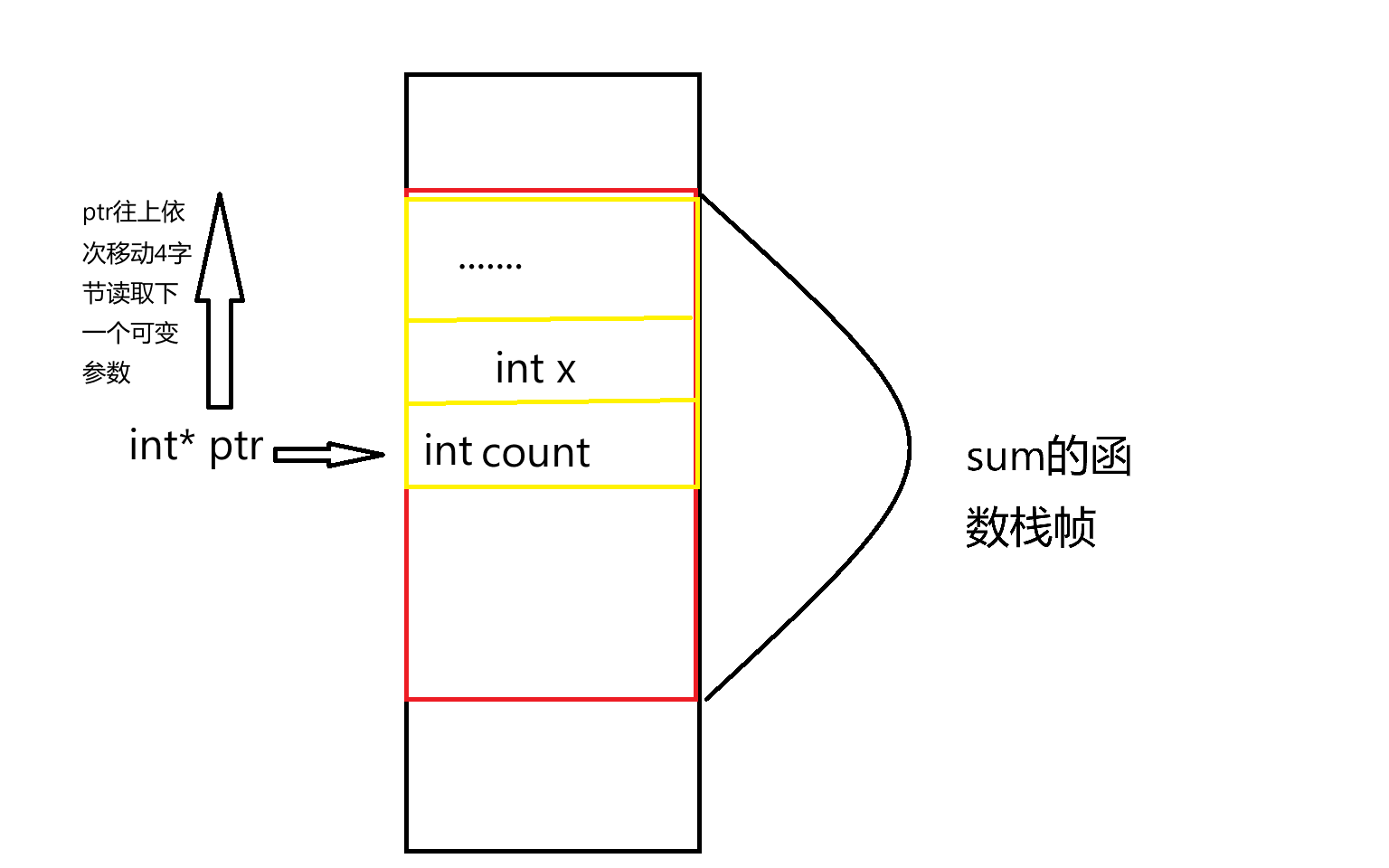
所以要使用可变参数,就要求我在至少给一个最左侧的固定参数,因为我们需要一个起始地址,那么接下来我们可以通过指针来指向它,然后通过移动该指针,然后依次访问到右侧的参数,但是为了不引发越界,我们一般可以采取两种方式,第一种方式就是最左侧的固定参数的值设置为可变参数的数量,然后我们首先获取到左侧的固定参数从而获取指针移动的次数,那么以下面的sum函数为例子:
c
int sum(int count,...)
{
int* ptr=&count;
int x=0;
for(int i=1;i<=count;i++)
{
x+=*(ptr+i);
}
return x;
}
int main()
{
int x=sum(2,5,7);
}那么给一个函数的栈帧的布局来帮组我们理解这种访问方式:
那么第二种方式就是我们传递的最后一个实参的值可以设置为一个特殊的值比如-1或者NULL,那么一旦我们遍历到这个值的时候,意味着遍历到可变参数的最右侧
c
sum(1,2,3,NULL);//从1加到3
c
int sum(int num,...)
{
int* ptr=#
int x=0;
for(int i=0;(*ptr)!=NULL;i++)
{
x+=*(ptr+i);
}
return x;
}但是现代的编译器进行了优化,因为现在的调用者函数压入的参数不一定是压入函数的栈帧中,有可能是写入到CPU的寄存器中,并且即使压入栈帧,还可能存在内存对齐,所以此时我们便无法采取简单的指针来访问,幸运的是,c语言的库中已经帮组我们实现好了针对于可变参数的一系列的宏,那么他们都封装在stdarg.h头文件中,能够更简单并且更安全的遍历可变参数

其中提供了一个va_list类型,那么这个类型的变量就可以理解为一个指针,指向栈或者寄存器
那么该指针需要进行初始化,那么初始化的函数就交给了va_start函数来完成,那么该函数就是将该va_list类型的变量指向固定参数紧挨着的下一个可变参数
c
void va_start (va_list ap, paramN);而遍历可变参数的宏则是交给了va_arg函数,那么该函数则是返回当前va_list类型变量指向的值,然后将其移动到下一个可变参数,那么其移动的单位则是得由第二个参数来决定,是一次移动4个字节也就是一个int类型还是8个字节也就是double类型
c
type va_arg (va_list ap, type)最后则是va_end,那么这个函数就是将va_list类型的指针给置空,避免继续访问导致越界问题
c
void va_end (va_list ap);而这里不难发现,这里va_arg只能移动固定的单位长度,那么就要求所有的可变参数的数据类型是相同的,比如都是int或者都是double,但是如果你调用函数传递的参数是这种情况的话:
c
print(1,"hello",3.14);那么此时便无法通过仅仅通过va_arg来解决,因为你不知道到时用户调用该函数传递的可变参数的数量以及类型,所以你现在知道对于printf函数来说,它就是支出可变参数,但是它的巧妙之处就在于它通过一个格式化的字符串作为固定参数通过其占位符来告诉你可变参数的数量以及可变参数的类型,那么这就是可变参数的讲解,那么在打印日志需要用到这部分知识
3.枚举类型
那么这里我们到时候会将定义出日志类的四个日志等级,那么这4个日志等级会作为常量将其封装在一个枚举体中,那么我们也可以直接用define的方式定义4个日志等级常量,但是我更喜欢将这4个日志等级常量封装在枚举体中
而这里的枚举体中的成员变量都是常量,那么假设枚举体中的成员变量的个数为n,那么枚举体中的成员会按照声明的顺序对应0到n-1的常量值
c
#include <stdio.h>
// 定义枚举类型
enum Weekday {
MONDAY, // 默认值 0
TUESDAY, // 1
WEDNESDAY, // 2
THURSDAY, // 3
FRIDAY, // 4
SATURDAY, // 5
SUNDAY // 6
};
int main() {
enum Weekday today = WEDNESDAY;
if (today == WEDNESDAY) {
printf("Today is Wednesday!\n"); // 输出: Today is Wednesday!
}
return 0;
}那么我们也可以对枚举体中的成员变量来显示赋值,但是注意,你给其中一个成员变量假设赋值为n,而原本该成语变量的默认值假设为m,那么它赋值之后,那么从它开始的之后的成员变量的值则是默认值则是从n+1而不是m+1,所以之后的默认值就是从n+1开始递增
c
enum CustomEnum { X = 5, Y, Z }; // X=5, Y=6, Z=7那么这样做其实会导致枚举体中有的成语变量的值是相同的,那么就得注意这点,那么枚举体的好处就是便于维护,那么不要我们手动来define多个常量了
具体实现
1.日志类
那么这里我们采取的是c/c++混编的代码来实现,所以这里日志的打印,我将其包装成一个日志类,那么日志类的四个等级,那么他们分别对应4个常量的值,那么我将其定义在一个匿名枚举体中,那么匿名枚举体就不要我们显示定义枚举类型的变量,然后通过该枚举类型的变量来访问其枚举体中的成员变量,因为匿名枚举体中的成员变量会直接展开到其所处的作用域中,那么直接通过其成员变量名来访问即可
c
enum
{
info,
debug,
warning,
Fatal,
};其次就是我们的log类,那么这里我上文说过,我们日志信息可以输入到终端,也可以输出到一个文件中,还可以根据其日志的等级分类输出到不同的文件中,那么这里我们就得准备一个成员变量来作为标记,代表当前日志选择哪种输出类型,其次就是一个打印日志信息的logmessage的成员函数,那么这里我们可以将我们的日志信息分为两部分,一个是默认部分一个是用户自定义部分
那么其中默认部分,也就是一个日志信息必须要要包含的内容,那么就是日志的等级以及日志的时间
而这里我们logmessage函数设计的时候,就得采取可变参数,所以这里的logmessage的参数列表就可以分为两部分,第一部分是固定参数,那么第一个固定参数就是当前的日志信息的等级是一个整数,而第二个固定参数,就是用户自定义部分的信息的格式化字符串,那么第二部分就是格式化字符串所涉及到的可变参数
而对于logmessage函数体内部,那么我们就要首先获取到第一个固定参数,也就是一个整形的变量,然后将其转换为对应的日志等级的字符串然后用一个字符指针来接收指向该字符串,接着就是时间,那么这里就需要用到时间戳,那么时间戳就是指的是从1900年1月1日00:00到现在目前时间的秒数,那么这里就需要用到<time.h>中的time函数,那么它会接收一个time_t类型的指针,然后将时间戳写入该指针,那么该指针其实就是一个输出型参数,那么该函数的返回值其实也是时间戳,所以我们没必要传入参数,直接使用返回值即可
c
time_t time (time_t* timer);那么这里时间戳是从1900到现在的秒数,那么我们肯定看不懂,我们得需要具体的时间,也就是几年几月几号几时几分,那么这里就需要我们将其转换为我们能够读懂的时间,所以这里就需要调用localtime函数
c
struct tm * localtime (const time_t * timer);那么localtime函数会返回一个结构体类型的指针,其指向一个struct tm结构体,那么我们可以来看一下该结构体里面的成语变量:
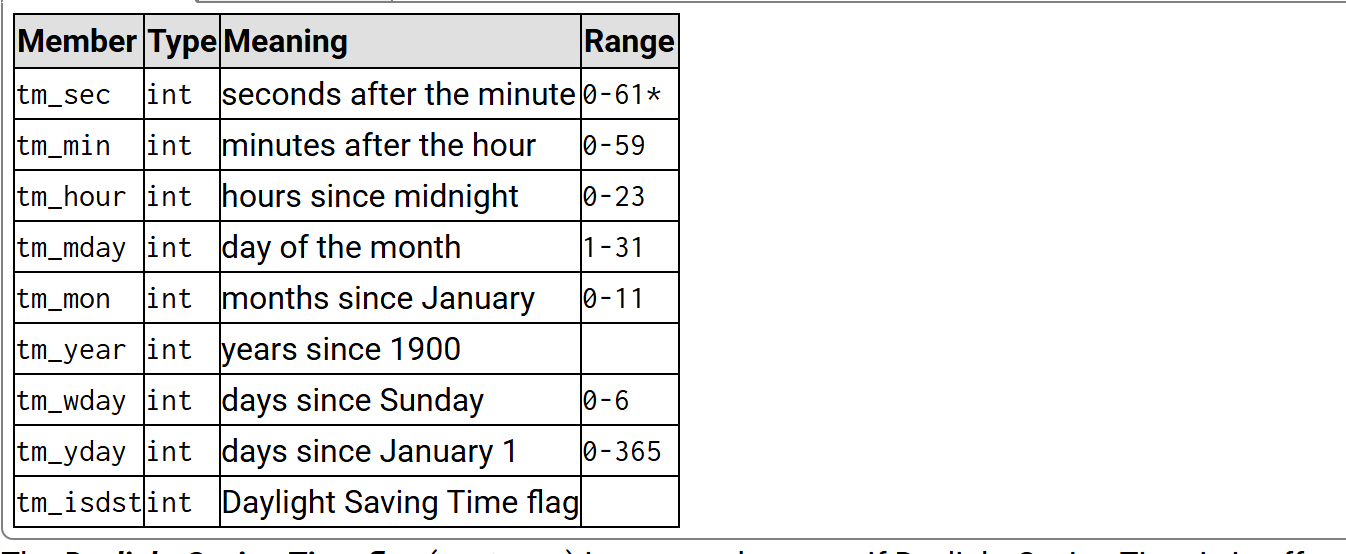
那么这里封装了年月日以及时分秒,但是要注意,这里的年也就是tm_year,那么它的值是今年到1900的差值,比如今年是2025,那么此时tm_year的是就是125,所以我们在使用tm_year的时候,一定得加一个1900,而其次就是月,那么这里的tm_mon的值是在0到11,所以1月对应的tm_mon的值是0,所以我们在使用tm_month的时候,得加1
那么这里调用localtime得到了struct tm结构体之后,那么接下来我们就要格式话我们的时间字符串然后保存到一个字符数组中,那么这里就需要调用snprintf函数,那么snprint函数接收一个字符指针,指向该数组的首元素的地址,以及你要往该数组写入的字节数,还会接收一个用于格式化的字符串,那么他会按照格式化字符串的内容,将其可变参数填入最终写入数组中
c
int snprintf ( char * s, size_t n, const char * format, ... );那么日志的默认部分的内容就做完了,那么接下来就是自定义部分,那么自定义部分,就需要调用vsnprintf函数,那么这里与snprintf函数的区别就是,这里vsnprintf函数的最后一个参数是指向第一个可变参数的指针,那么这里我们只需要给它该指针,那么它会自动的遍历其后面的所有可变参数,将这些可变参数依次填入前面的格式化字符串当中
c
int vsnprintf (char * s, size_t n, const char * format, va_list arg );那么最后我们会得到三个部分的字符串,分别是日志等级,以及日志时间,以及用户自定义部分,那么最后我们再调用snprintf将这三个比分的字符串拼接在一起即可
log类完整实现:
cpp
#define SIZE 1024
#define screen 0
#define File 1
#define ClassFile 2
enum
{
info,
debug,
warning,
Fatal,
};
class log
{
private:
std::string memssage;
int method;
public:
log(int _method=screen)
:method(_method)
{
}
void logmessage(int leval,char* format,...)
{
char* _leval;
switch(leval)
{
case info:
_leval="info";
break;
case debug:
_leval= "debug";
break;
case warning:
_leval="warning";
break;
case Fatal:
_leval="Fatal";
break;
}
char timebuffer[SIZE];
time_t t=time(NULL);
struct tm* localTime=localtime(&t);
snprintf(timebuffer,SIZE,"[%d-%d-%d-%d:%d]",localTime->tm_year+1900,localTime->tm_mon+1,localTime->tm_mday,localTime->tm_hour,localTime->tm_min);
char rightbuffer[SIZE];
va_list arg;
va_start(arg,format);
vsnprintf(rightbuffer,SIZE,format,arg);
char finalbuffer[2*SIZE];
snprintf(finalbuffer,sizeof(finalbuffer),"[%s]%s:%s",_leval,timebuffer,rightbuffer);
int fd;
switch(method)
{
case screen:
std::cout<<finalbuffer<<std::endl;
break;
case File:
fd=open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd>=0)
{
write(fd,finalbuffer,sizeof(finalbuffer));
close(fd);
}
break;
case ClassFile:
switch(leval)
{
case info:
fd=open("log/info.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
write(fd,finalbuffer,sizeof(finalbuffer));
break;
case debug:
fd=open("log/debug.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
write(fd,finalbuffer,sizeof(finalbuffer));
break;
case warning:
fd=open("log/Warning.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
write(fd,finalbuffer,sizeof(finalbuffer));
break;
case Fatal:
fd=open("log/Fat.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
break;
}
if(fd>0)
{
write(fd,finalbuffer,sizeof(finalbuffer));
close(fd);
}
}
}
};2.server
(1).创建管道文件
那么创建管道文件这里就调用mkfifo,然后这里我们要对mkfifo的返回值进行一个判断如果其为-1,那么说明调用失败,那么这个错误是对应的日志等级是Fatal,那么这里我们就得调用logmessage写入这条信息,这条信息就包括日志等级以及时间和错误码以及对应的错误解释,那么调用logmessage的前提是你得创建了一个log对象,通过该log对象去调用其成员函数
cpp
int n=mkfifo(FIFO_FILE,0666);
log a;
if(n<0)
{
a.logmessage(Fatal,"mkfifo fail: the errno: %d and strerror:%s ",errno,sterrno(errno));
exit(mkfifo_FAILIRE);
}(2).打开管道文件
那么创建完管道文件的下一步肯定就是打开管道文件了,那么这里会调用open接口,这里有一个小细节,就是这里open一个命名管道文件,那么这里如果只有读端或者写端被打开了,那么此时进程会陷入阻塞状态,因为这里要成功打开管道文件,得是读写端同时打开,那么才能打开管道文件,那么至于底层open是如何做到了,那么是因为管道文件的inode结构体中会维护两个字段,分别是读端的引用计数以及写端的引用计数,那么此时打开读端,那么如果写端的引用计数为0,那么此时会陷入阻塞,反之同理,只有检测到读写端都不为0后,那么才能打开管道文件,从而获取到写端的文件描述符
那么这里我还是加了一个调试用的日志信息在open接口调用之前,那么open失败这里也要输出一个致命的日志信息
cpp
a.logmessage(debug,"server waiting client to open fifo");
int fd=open(FIFO_FILE,O_WRONLY);
a.logmessage(debug,"server open fifo successfully");
if(fd<0)
{
a.logmessage(Fatal,"server open fail:the errno is %d and strerror: %s ",errno,strerror(errno));
unlink(FIFO_FILE);
exit(open_FAILIRE);
}(3).向管道文件写入
那么这一步我将其封装到了一个while死循环中,那么这里定义了一个string对象来保存用户输入的字符串,但是这里注意只能用getline来接收,因为用户输入的字符串会含有空格,那么如果是用cin来读取的话,那么这里读取到空格就结束了,那么这里我们由于是一个死循环的逻辑,那么正常情况下,server进程是会一直往管道文件做写入,那么用户如果不想对client进程通信了,那么此时输入"stop sending"这个字符串就表示退出,所以这里我们会对string对象保存的字符串内容做一个比较,如果不是"stop sending"就调用write接口写入向管道文件写入
cpp
while(true)
{
std::string message;
std::cout<<"请输入要发送的信息:"<<std::endl;
std::getline(std::cin,message);
if(message=="stop sending")
{
a.logmessage(debug,"server quit successfully");
break;
}
int n=write(fd,message.c_str(),message.size());
if(n<0)
{
a.logmessage(Fatal,"server write fail:the errno is %d and strerror: %s ",errno,strerror(errno));
exit(write_FAILIRE);
}
a.logmessage(info,"server send a message succfully:%s",message.c_str());
}(4).清理管道
那么清理管道这一步就很简单了就是关闭读端的文件描述符以及删除管道文件即可
cpp
close(fd);
unlink(FIFO_FILE);
exit(0);3.clinet
(1).打开管道文件
那么这里client就只需打开管道文件的读端,那么就调用open接口来打开获取文件描述符,并且做相应的日志信息的打印
(2).读取管道文件
那么这里同样读取管道文件的内容封装到一个while死循环中,那么这里我们会定义一个临时的字符数组来保存读取的内容,那么这里注意一个关键点,那么就是我们需要将字符数组给显示的将其所有元素用0覆盖,因为如果没有这步,那么字符数组里面的元素都是随机值,到时候读取了管道文件之后打印该字符数组的内容会有可能有错误
那么我们还要对read的返回值进行一个判断,如果read返回0,那么则代表写端被关闭了,那么就退出循环
cpp
while(true)
{
char buffer[1024]={0};
int n=read(fd,buffer,sizeof(buffer));
if(n<0)
{
a.logmessage(Fatal,"client open fail:the erron is %d and strerror: %s ",errno,strerror(errno));
exit(read_FAILIRE);
}
if(n==0)
{
a.logmessage(info,"client quit successfully");
break;
}
a.logmessage(info,"client get a message:%s",buffer);
}(3).关闭读端
cpp
close(fd);
exit(0);源码
FIFO.hpp
cpp
#pragma once
#include<unistd.h>
#include<sys/stat.h>
#include<fcntl.h>
#define FIFO_FILE "./myfifo"
#define mkfifo_FAILIRE 1
#define open_FAILIRE 2
#define write_FAILIRE 3
#define read_FAILIRE 4log.hpp
cpp
#include<iostream>
#include<string>
#include<time.h>
#include<stdarg.h>
#define SIZE 1024
#define screen 0
#define File 1
#define ClassFile 2
enum
{
info,
debug,
warning,
Fatal,
};
class log
{
private:
std::string memssage;
int method;
public:
log(int _method=screen)
:method(_method)
{
}
void logmessage(int leval,char* format,...)
{
char* _leval;
switch(leval)
{
case info:
_leval="info";
break;
case debug:
_leval= "debug";
break;
case warning:
_leval="warning";
break;
case Fatal:
_leval="Fatal";
break;
}
char timebuffer[SIZE];
time_t t=time(NULL);
struct tm* localTime=localtime(&t);
snprintf(timebuffer,SIZE,"[%d-%d-%d-%d:%d]",localTime->tm_year+1900,localTime->tm_mon+1,localTime->tm_mday,localTime->tm_hour,localTime->tm_min);
char rightbuffer[SIZE];
va_list arg;
va_start(arg,format);
vsnprintf(rightbuffer,SIZE,format,arg);
char finalbuffer[2*SIZE];
snprintf(finalbuffer,sizeof(finalbuffer),"[%s]%s:%s",_leval,timebuffer,rightbuffer);
int fd;
switch(method)
{
case screen:
std::cout<<finalbuffer<<std::endl;
break;
case File:
fd=open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd>=0)
{
write(fd,finalbuffer,sizeof(finalbuffer));
close(fd);
}
break;
case ClassFile:
switch(leval)
{
case info:
fd=open("log/info.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
write(fd,finalbuffer,sizeof(finalbuffer));
break;
case debug:
fd=open("log/debug.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
write(fd,finalbuffer,sizeof(finalbuffer));
break;
case warning:
fd=open("log/Warning.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
write(fd,finalbuffer,sizeof(finalbuffer));
break;
case Fatal:
fd=open("log/Fat.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
break;
}
if(fd>0)
{
write(fd,finalbuffer,sizeof(finalbuffer));
close(fd);
}
}
}
};server.cpp
cpp
#include"FIFO.hpp"
#include"log.hpp"
#include<cerrno>
#include<cstring>
int main()
{
int n=mkfifo(FIFO_FILE,0666);
log a;
if(n<0)
{
a.logmessage(Fatal,"mkfifo fail: the errno: %d and strerror:%s ",errno,sterrno(errno));
exit(mkfifo_FAILIRE);
}
a.logmessage(debug,"server waiting client to open fifo");
int fd=open(FIFO_FILE,O_WRONLY);
a.logmessage(debug,"server open fifo successfully");
if(fd<0)
{
a.logmessage(Fatal,"server open fail:the errno is %d and strerror: %s ",errno,strerror(errno));
unlink(FIFO_FILE);
exit(open_FAILIRE);
}
while(true)
{
std::string message;
std::cout<<"请输入要发送的信息:"<<std::endl;
std::getline(std::cin,message);
if(message=="stop sending")
{
a.logmessage(debug,"server quit successfully");
break;
}
int n=write(fd,message.c_str(),message.size());
if(n<0)
{
a.logmessage(Fatal,"server write fail:the errno is %d and strerror: %s ",errno,strerror(errno));
exit(write_FAILIRE);
}
a.logmessage(info,"server send a message succfully:%s",message.c_str());
}
close(fd);
unlink(FIFO_FILE);
exit(0);
}client.cpp
cpp
#include"FIFO.hpp"
#include"log.hpp"
#include<cstring>
#include<cerrno>
int main()
{
log a;
int fd=open(FIFO_FILE,O_RDONLY);
a.logmessage(info,"client open fifo successfully");
if(fd<0)
{
a.logmessage(Fatal,"clinet open fail:the erron is %d and strerror: %s ",errno,strerror(errno));
exit(open_FAILIRE);
}
while(true)
{
char buffer[1024]={0};
int n=read(fd,buffer,sizeof(buffer));
if(n<0)
{
a.logmessage(Fatal,"client open fail:the erron is %d and strerror: %s ",errno,strerror(errno));
exit(read_FAILIRE);
}
if(n==0)
{
a.logmessage(info,"client quit successfully");
break;
}
a.logmessage(info,"client get a message:%s",buffer);
}
close(fd);
exit(0);
}运行截图:
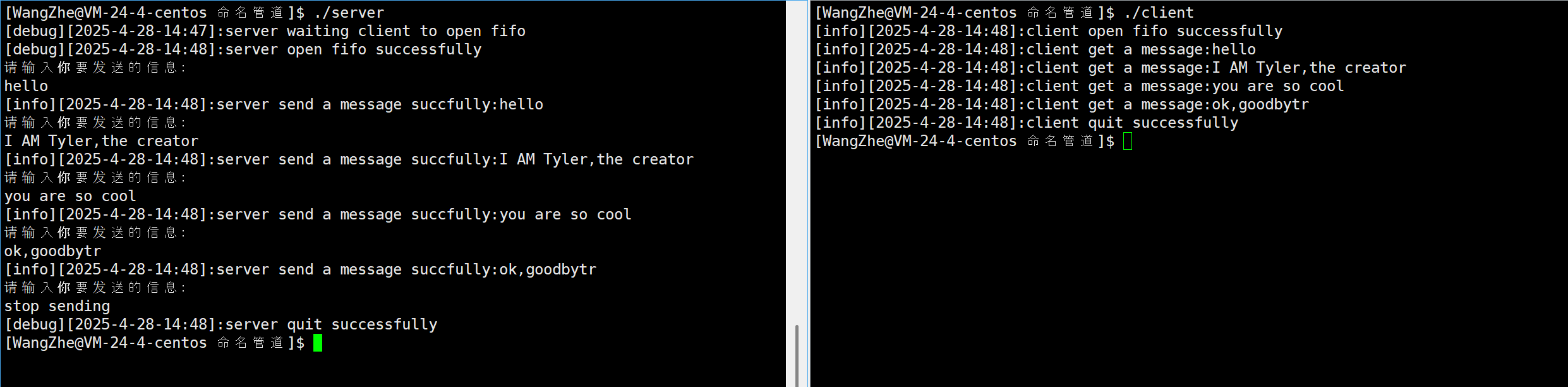
结语
那么这就是本期关于命名管道的所有内容,从多个维度带你全方位解析命名管道,那么希望读者下去也能够自己实现一个自己的命名管道,那么我的下一期博客将讲解共享内存,那么我会持续更新,希望你能够多多关注,那么如果本文有帮组到你的话,还请多多支持哦,你的支持就是我创作的最大的动力!
