Kafka 生产者(Producer)是 Kafka 生态系统中的核心组件之一,负责将消息发送到 Kafka 集群。它的架构设计充分考虑了高吞吐量、可靠性和可扩展性等要求。生产者采用分层架构,从应用层到网络层,每一层都承担特定的职责。通过消息批次(Batch)处理、异步发送、压缩传输等机制,实现了高效的消息发送。同时,通过可配置的确认机制(acks)、重试策略和幂等性支持,保证了消息传输的可靠性。生产者还提供了拦截器、序列化器和分区器等扩展点,使用户可以根据业务需求进行定制。整个架构通过缓冲区和内存池的管理,既控制了资源的使用,又优化了性能表现。
下面是Kafka生产者架构图:
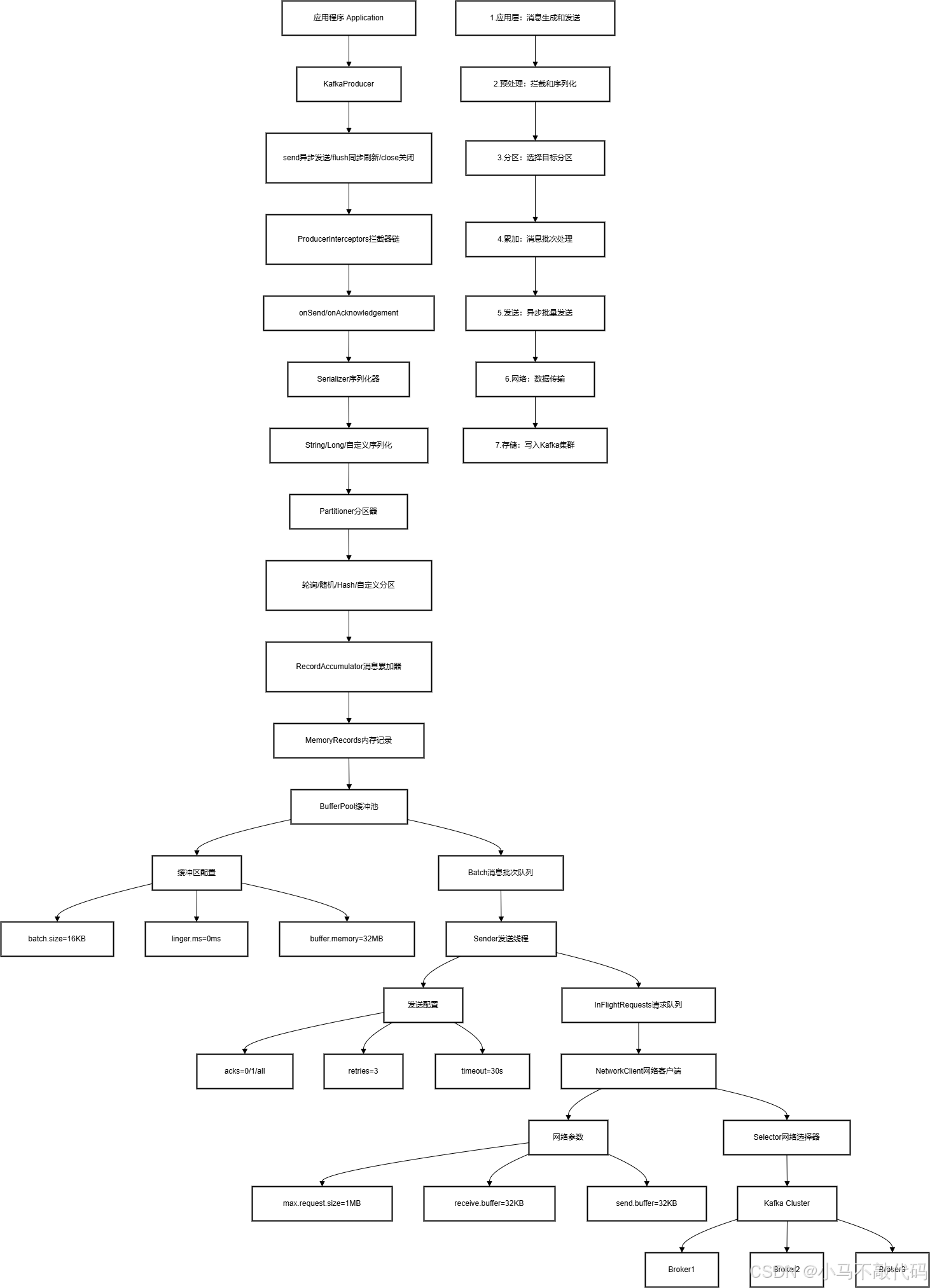
1、生产者应用层 (Producer Application Layer)
生产者应用层是整个 Kafka 生产者架构的入口,主要包含用户代码和 KafkaProducer 实例。在这一层,开发者通过 KafkaProducer 提供的 API 进行消息发送操作。主要包含三个核心方法:send() 用于异步发送消息,flush() 用于同步刷新确保消息发送完成,close() 用于安全关闭生产者释放资源。这一层的配置直接影响着消息发送的可靠性和性能,例如可以配置生产者的幂等性、事务特性等。开发者需要根据业务场景选择合适的配置参数,在可靠性和性能之间找到平衡点。
java
// 这段代码展示了生产者的核心发送流程:
// 1. 消息发送入口 send() 方法
// 2. 消息拦截器的调用
// 3. 序列化和分区选择
// 4. 消息追加到累加器
// 5. 唤醒发送线程
//KafkaProducer.java 的核心发送方法
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 检查生产者是否已经关闭
throwIfProducerClosed();
// 开始记录发送时间
long nowMs = time.milliseconds();
// 调用拦截器
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
// 执行序列化和分区选择
return doSend(interceptedRecord, callback, nowMs);
}
// 异步发送的具体实现
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback, long timestamp) {
// 获取或创建topic元数据
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 序列化key和value
byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 选择分区
int partition = partition(record, serializedKey, serializedValue, cluster);
// 构建消息批次并追加到累加器
RecordAccumulator.RecordAppendResult result = accumulator.append(...)
// 如果需要,唤醒sender线程
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
}2、消息预处理 (Message Preprocessing)
消息预处理层主要负责在消息发送前的拦截和序列化工作。ProducerInterceptors 拦截器链允许在消息发送前后进行自定义处理,比如添加时间戳、进行消息过滤、修改消息内容等。序列化器(Serializer)将用户的消息对象转换为字节数组,以便在网络上传输。Kafka 提供了多种内置的序列化器(如 String、Long 等),同时也支持自定义序列化器以满足特定的业务需求。这一层的处理对消息的格式和内容有直接影响,需要确保序列化和反序列化的一致性。
java
// 这部分代码展示了:
// 1. 拦截器链的执行过程
// 2. 序列化器的接口定义
// 3. 具体序列化器的实现示例
// ProducerInterceptors.java
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// 处理异常
}
}
return interceptRecord;
}
// Serializer接口
public interface Serializer<T> extends Closeable {
void configure(Map<String, ?> configs, boolean isKey);
byte[] serialize(String topic, T data);
byte[] serialize(String topic, Headers headers, T data);
void close();
}
// StringSerializer示例
public class StringSerializer implements Serializer<String> {
@Override
public byte[] serialize(String topic, String data) {
if (data == null)
return null;
return data.getBytes(StandardCharsets.UTF_8);
}
}3、分区管理 (Partition Management)
分区管理层决定消息将被发送到主题的哪个分区。Partitioner 分区器提供了多种分区策略:轮询分区(Round-Robin)确保消息均匀分布,随机分区(Random)提供随机性,基于 key 的 Hash 分区确保相同 key 的消息总是发送到相同分区,还支持自定义分区策略以满足特定的业务需求。合理的分区策略对于负载均衡和消息顺序性有重要影响,特别是在需要保证某些消息顺序性的场景下,选择合适的分区策略尤为重要。
java
// 分区器代码展示了:
// 1.默认分区策略的实现
// 2.基于key的hash分区
// 3.无key时的轮询分区
// DefaultPartitioner.java
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 如果没有key,使用轮询策略
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// 没有可用分区时,随机选择
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 有key时,使用hash策略
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}4、消息累加器 (Record Accumulator)
消息累加器是 Kafka 生产者性能优化的关键组件,它将多个小消息累积成批次后再发送,以提高传输效率。RecordAccumulator 维护了一个内存缓冲区(BufferPool),通过 batch.size(默认16KB)和 linger.ms(默认0ms)两个关键参数控制消息批次的累积策略。buffer.memory(默认32MB)参数限制了生产者可以使用的总内存大小。这种批量发送机制显著减少了网络传输的次数,提高了吞吐量,但也会带来一定的延迟,需要根据实际场景权衡配置。
java
// 这段代码展示了:
// 消息批次的管理
// 批次大小的控制
// 消息追加的过程
// RecordAccumulator.java
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) {
// 获取或创建消息批次
ProducerBatch batch = getOrCreateBatch(tp, ...);
// 追加记录到批次
RecordAppendResult appendResult = batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
// 处理追加结果
if (appendResult != null) {
return appendResult;
}
// 如果当前批次已满,创建新批次
byte[] serializedKey = key;
byte[] serializedValue = value;
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(magic, compression, serializedKey, serializedValue, headers));
batch = createBatch(tp, size);
// 再次尝试追加
appendResult = batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
return appendResult;
}5、发送线程 (Sender Thread)
发送线程是一个独立的线程,负责将消息批次发送到 Kafka 集群。它维护了一个 InFlightRequests 队列,用于跟踪已发送但尚未收到响应的请求。关键配置包括 acks(确认级别)、retries(重试次数)和 timeout(超时时间)等。acks=0 表示不等待确认,acks=1 表示等待领导者确认,acks=all 表示等待所有副本确认。这些配置直接影响消息的可靠性和延迟,需要根据业务对可靠性的要求来设置。
java
// 发送线程代码展示了:
// 发送循环的实现
// 批次的获取和发送
// 网络请求的处理
// Sender.java
public void run() {
while (running) {
try {
runOnce(); // 执行一次发送循环
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
}
void runOnce() {
// 获取准备发送的批次
long currentTimeMs = time.milliseconds();
long pollTimeout = sendProducerData(currentTimeMs);
// 处理响应
client.poll(pollTimeout, currentTimeMs);
}
private long sendProducerData(long now) {
// 获取可发送的消息批次
Map<Integer, List<ProducerBatch>> batches = accumulator.drain(...);
// 发送消息批次
for (Map.Entry<Integer, List<ProducerBatch>> entry : batches.entrySet()) {
sendProducerData(entry.getKey(), entry.getValue());
}
}6、网络层 (Network Layer)
网络层处理与 Kafka 集群的实际网络通信。NetworkClient 负责管理网络连接,Selector 基于 Java NIO 实现非阻塞的网络操作。关键参数包括 max.request.size(限制请求大小)、receive.buffer.bytes 和 send.buffer.bytes(控制网络缓冲区大小)。这一层的配置直接影响网络传输的效率和稳定性,需要根据网络环境和性能需求进行调优。
java
// 网络层代码展示了:
// 网络连接的管理
// 数据发送的实现
// 连接状态的维护
// NetworkClient.java
public boolean ready(Node node, long now) {
// 检查连接状态
if (node.isEmpty())
return false;
// 检查是否需要创建新连接
if (connectionStates.canConnect(node.idString(), now))
return true;
// 检查连接是否就绪
return connectionStates.isReady(node.idString(), now);
}
// KafkaChannel.java
public Send write() throws IOException {
if (send == null)
return null;
int written = send.writeTo(transportLayer);
if (send.completed())
send = null;
return send;
}7、Kafka 集群 (Kafka Cluster)
Kafka 集群是消息的最终存储地,由多个 Broker 组成。每个主题可以有多个分区,每个分区可以有多个副本,分布在不同的 Broker 上。集群通过 ZooKeeper 管理元数据和协调各个组件。生产者的消息最终会被写入到特定分区的领导者副本,然后根据复制机制同步到
其他副本。集群的配置和部署直接影响系统的可用性、可靠性和扩展性。
java
// 这部分代码展示了:
// 生产者与集群的交互
// 元数据的获取和更新
// 集群状态的检查
// KafkaProducer与集群交互的相关代码
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) {
// 获取集群元数据
Cluster cluster = metadata.fetch();
// 检查topic是否存在
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
// 更新元数据
metadata.add(topic);
// 等待元数据更新
cluster = metadata.awaitUpdate(version, maxWaitMs);
return new ClusterAndWaitTime(cluster, remainingWaitMs);
}Kafka 生产者的架构设计体现了分布式系统的精髓,通过分层设计实现了高内聚低耦合的架构特点。从消息生成到最终存储,每一层都可以独立优化和扩展。生产者的性能优化策略(如批量发送、异步处理、压缩传输等)和可靠性保证机制(如消息确认、重试策略、幂等性等)相互平衡,为不同场景提供了灵活的配置选项。通过源码分析,我们可以看到 Kafka 在工程实现上的精妙之处,比如通过 RecordAccumulator 实现高效的批次管理,通过 Sender 线程实现异步发送,通过网络层的精心设计保证了高吞吐量。这些设计思想和实现方式,为我们构建高性能、可靠的分布式消息系统提供了宝贵的参考。