在当今数据驱动的时代,高效的数据存储和检索已成为互联网应用的基石。作为最流行的开源关系型数据库之一,MySQL的存储架构设计体现了数十年数据库理论的精华。想象一下,如果没有良好的存储结构,查询一个拥有百万条记录的用户表就像在一间杂乱无章的仓库中寻找特定物品,而优秀的存储架构则像为仓库建立了精密的货架系统和检索目录。
本文将深入解析MySQL的存储架构设计,重点探讨其核心------B+树索引结构。通过追溯技术演进历程、分析实际案例和代码示例,揭示MySQL如何高效管理数据存储,以及这种设计背后的深层原理。
前MySQL时代的数据管理困境
原始数据存储方式
在理解现代数据库存储架构之前,让我们先回顾早期的数据管理方法。最初,数据通常以简单文件形式顺序存储:
// 早期数据文件示例 - 简单的CSV格式
1,张三,28,工程师
2,李四,32,设计师
3,王五,25,产品经理
4,赵六,29,架构师
// ... 更多数据这种存储方式存在明显问题:
-
查询效率低下:查找特定记录需要遍历整个文件
-
插入删除困难:在文件中间插入或删除数据需要重写整个文件
-
并发访问冲突:多用户同时访问时容易产生数据不一致
早期索引尝试:链表结构
为解决全表扫描的效率问题,早期系统尝试使用链表结构建立索引:
cpp
// 简化的链表索引结构
struct LinkedListIndex {
int key; // 键值
long offset; // 数据文件中的偏移量
struct LinkedListIndex* next; // 指向下一个节点
};虽然链表结构提高了特定场景的查询效率,但随机访问性能仍然很差。查找第N个节点需要遍历前N-1个节点,时间复杂度为O(N)。
二分查找与数组索引
有序数组结合二分查找提供了O(logN)的查询性能:
cpp
// 数组索引结构
struct ArrayIndex {
int key; // 键值
long offset; // 数据偏移量
};
// 二分查找实现
int binary_search(struct ArrayIndex index[], int n, int target) {
int left = 0, right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (index[mid].key == target) {
return mid; // 找到目标
} else if (index[mid].key < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1; // 未找到
}然而,数组索引在数据插入和删除时面临挑战,需要移动大量元素,维护成本高。
B树与B+树的革命性突破
B树:平衡多路搜索树
B树(Balanced Tree)的出现解决了前面提到的诸多问题。它是一种自平衡的树数据结构,保持数据排序,并允许在O(logN)时间内进行搜索、顺序访问、插入和删除。
B树的核心特性:
-
每个节点最多包含m个子节点(m阶B树)
-
除根节点外,每个节点至少包含⌈m/2⌉个子节点
-
所有叶子节点位于同一层次
-
节点中的数据键值按升序排列
B+树:数据库索引的理想选择
B+树在B树基础上进行了优化,成为数据库索引的事实标准。与B树相比,B+树有以下重要区别:
-
所有数据记录都存储在叶子节点,内部节点只存储键值和子节点指针
-
叶子节点通过指针连接形成有序链表,支持高效的范围查询
-
内部节点不存储数据指针,因此可以容纳更多键值,降低树高度
B+树在磁盘存储中的优势
数据库系统主要运行在磁盘介质上,而磁盘I/O是主要性能瓶颈。B+树的设计充分考虑了磁盘访问特性:
-
节点大小与磁盘页对齐:减少I/O次数
-
高扇出性:减少树高度,降低查询时的磁盘访问次数
-
顺序访问优化:叶子节点链表支持高效范围扫描
MySQL存储架构深度解析
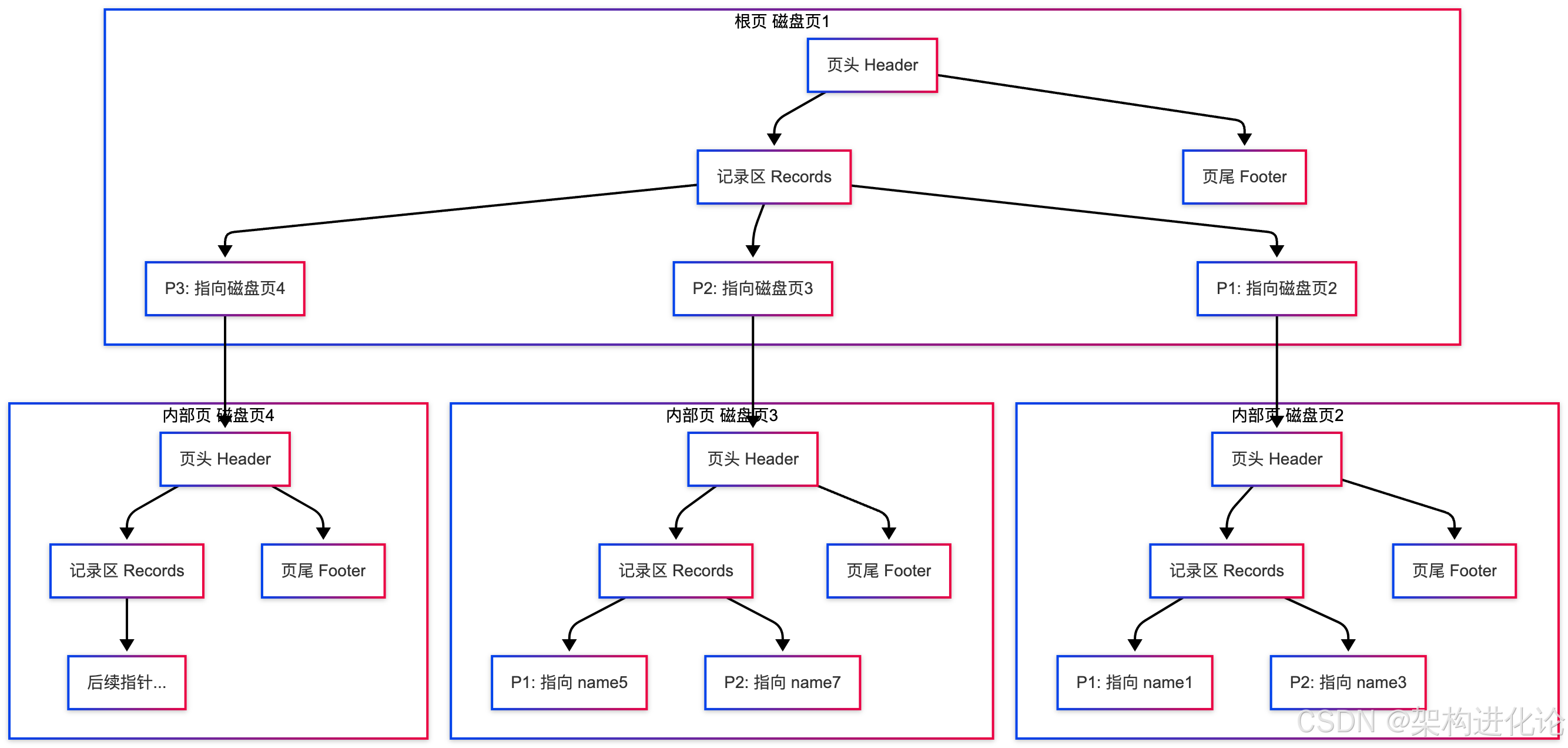
InnoDB存储引擎架构
MySQL的InnoDB存储引擎使用B+树作为其主要索引结构。让我们通过具体的架构图来理解这一设计:

磁盘页结构与指针系统
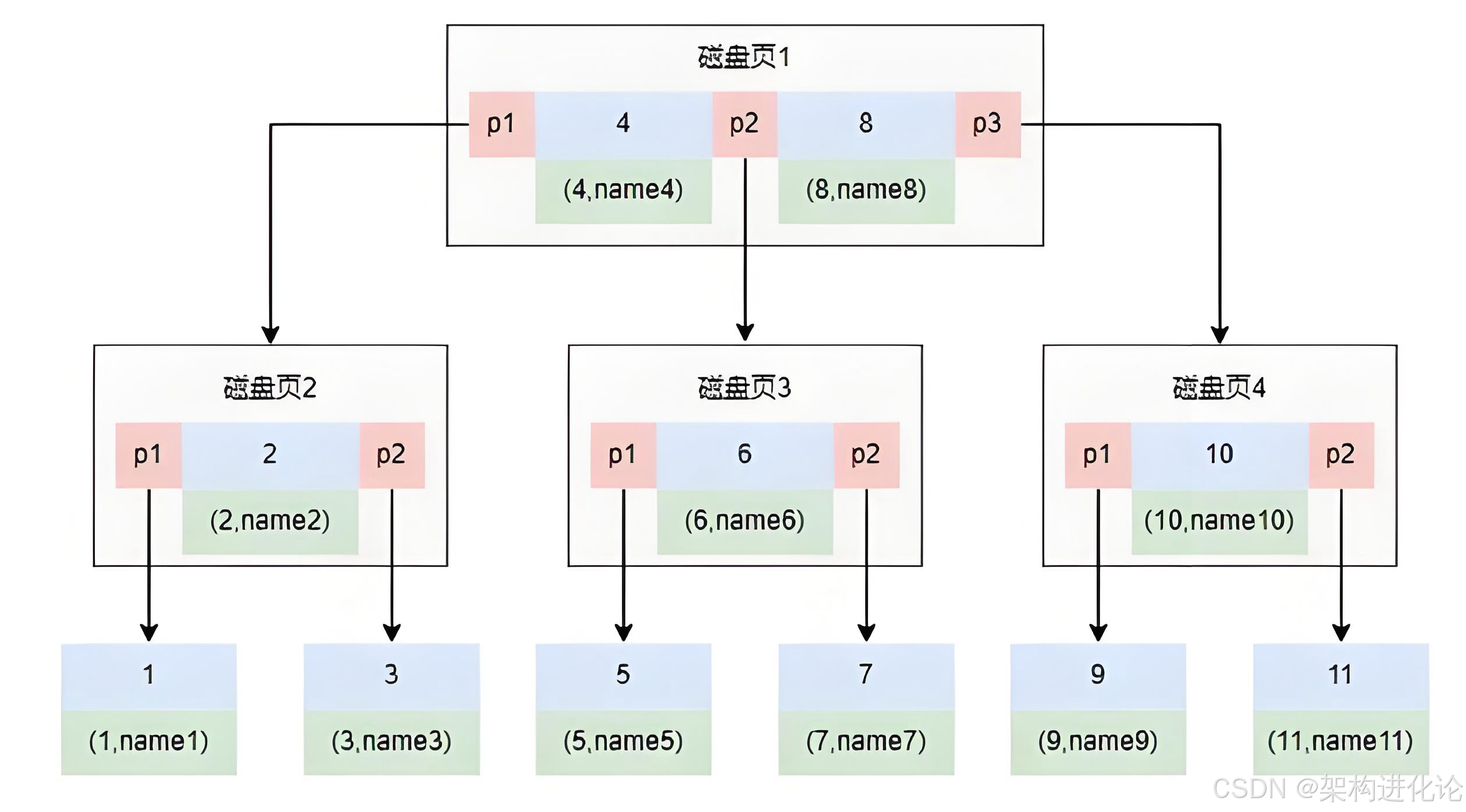
现在让我们详细分析具体磁盘页结构示例:
在这个结构中:
-
**磁盘页1(根页)**包含三个指针P1、P2、P3,分别指向磁盘页2、3、4
-
磁盘页2包含键值对(1, name1)和(3, name3),其中1和3是索引键,name1和name3是对应的数据或指针
-
磁盘页3包含键值对(5, name5)和(7, name7)
这种设计允许高效的查找操作。例如,查找键值为4的记录:
-
从根页(磁盘页1)开始,确定4在P2和P3之间,因此选择P2指向的磁盘页3
-
在磁盘页3中,4在5之前,因此选择P1指向的数据位置
-
最终找到或确认不存在键值为4的记录
页内部结构详解
每个磁盘页(通常16KB)有精密的内部结构:
cpp
// 简化的页结构表示
struct InnoDBPage {
// 页头 (38字节)
uint32_t checksum; // 校验和
uint32_t page_number; // 页号
uint8_t page_type; // 页类型
uint32_t previous_page; // 上一页
uint32_t next_page; // 下一页
uint16_t free_space; // 空闲空间
uint16_t records_count; // 记录数量
// 记录内容区
byte records[16384 - 38 - 8]; // 16KB - 页头 - 页尾
// 槽目录 (可变长度)
uint16_t slot_directory[];
// 页尾 (8字节)
uint32_t lsn_low; // LSN低32位
uint16_t page_type_copy; // 页类型副本
uint16_t checksum_copy; // 校验和副本
};记录格式与行存储
InnoDB支持两种行格式:COMPACT和DYNAMIC。以COMPACT格式为例:
cpp
// COMPACT行格式结构
struct CompactRecord {
// 变长字段长度列表 (逆序存储)
uint8_t var_len_fields[];
// NULL标志位
uint8_t null_flags;
// 记录头信息 (5字节)
uint8_t info_bits; // 信息位
uint8_t record_type; // 记录类型
uint16_t heap_number; // 堆号
uint16_t next_record_offset;// 下一条记录偏移量
// 事务ID (6字节)
uint64_t transaction_id;
// 回滚指针 (7字节)
uint64_t roll_pointer;
// 列数据
byte column_data[];
};实际案例与性能分析
图书馆检索系统案例
为了更好地理解B+树在实际中的应用,让我们考虑一个图书馆图书检索系统的例子。
在没有索引的情况下,查找特定书籍需要遍历整个书架:
python
# 线性搜索 - O(N)时间复杂度
def find_book_linear(books, isbn):
for book in books:
if book.isbn == isbn:
return book
return None使用B+树索引后:
python
# B+树搜索 - O(logN)时间复杂度
def find_book_bplus_tree(root_page, isbn):
current_page = root_page
# 从根页到叶子页的搜索
while not current_page.is_leaf:
# 在当前页中查找合适的子页指针
next_page_ptr = find_child_pointer(current_page, isbn)
current_page = load_page_from_disk(next_page_ptr)
# 在叶子页中查找具体记录
return find_record_in_leaf(current_page, isbn)性能对比实验
让我们通过具体数据来对比不同存储结构的性能差异。假设我们有一个包含100万条记录的用户表:
| 存储结构 | 平均查询时间 | 插入性能 | 范围查询性能 | 空间开销 |
|---|---|---|---|---|
| 无序数组 | O(N) - 慢 | O(1) - 快 | O(N) - 慢 | 低 |
| 有序数组 | O(logN) - 中 | O(N) - 慢 | O(logN + K) - 中 | 低 |
| 二叉搜索树 | O(logN) - 中 | O(logN) - 中 | O(N) - 慢 | 中 |
| B树 | O(logN) - 快 | O(logN) - 快 | O(logN + K) - 中 | 中 |
| B+树 | O(logN) - 快 | O(logN) - 快 | O(logN + K) - 快 | 稍高 |
从对比可以看出,B+树在综合性能上表现最优,特别是在范围查询方面。
实际SQL执行分析
通过EXPLAIN命令可以查看MySQL如何使用B+树索引:
sql
-- 创建测试表
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
age INT,
INDEX idx_age_name (age, name)
) ENGINE=InnoDB;
-- 分析查询执行计划
EXPLAIN SELECT * FROM users WHERE age BETWEEN 25 AND 35 AND name LIKE '张%';
-- 结果将显示:
-- type: range (使用索引范围扫描)
-- key: idx_age_name (使用复合索引)
-- rows: 估计需要检查的行数
-- Extra: Using index condition (使用索引条件下推)高级特性与优化策略
聚簇索引与二级索引
InnoDB使用聚簇索引组织表数据,这意味着数据行实际上存储在聚簇索引的叶子页中:
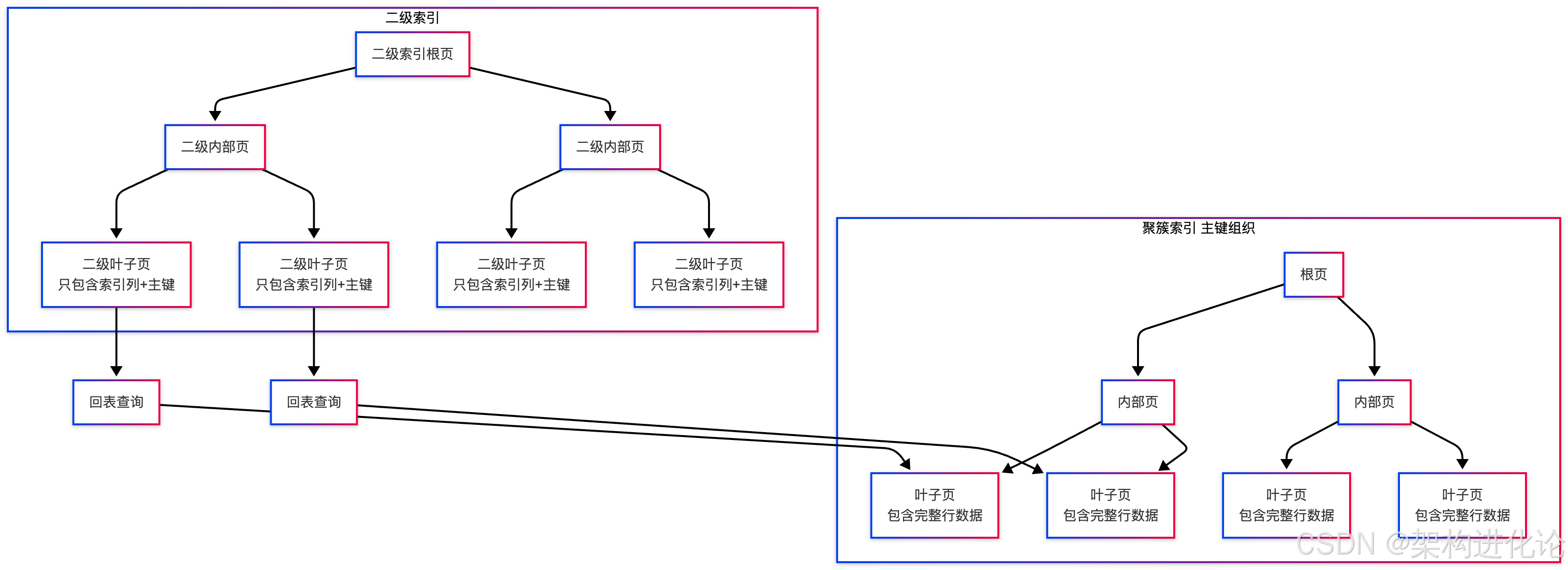
自适应哈希索引
InnoDB会自动为频繁访问的索引页创建哈希索引,加速查询:
cpp
// 自适应哈希索引结构简化表示
struct AdaptiveHashIndex {
uint64_t block_address; // 数据页地址
uint32_t fold_value; // 哈希值
uint16_t n_fields; // 字段数量
uint16_t n_bytes; // 字节数
uint8_t index_id; // 索引ID
};变更缓冲区优化
对于非唯一二级索引的插入、更新操作,InnoDB使用变更缓冲区延迟写入:
sql
-- 查看变更缓冲区状态
SHOW ENGINE INNODB STATUS;
-- 在输出中查找INSERT BUFFER AND ADAPTIVE HASH INDEX部分
-- Ibuf: size 1, free list len 0, seg size 2, 0 merges
-- merged operations:
-- insert 0, delete mark 0, delete 0现代存储架构的演进与未来
InnoDB的持续改进
从MySQL 5.7到8.0,InnoDB存储引擎经历了重大改进:
-
原生JSON支持:提供高效的JSON文档存储和查询
-
窗口函数:支持复杂的分析查询
-
通用表表达式:提高复杂查询的可读性和性能
-
不可见索引:允许临时禁用索引而不删除
-
倒序索引:优化降序排序查询
云原生与分布式存储
随着云计算的普及,MySQL存储架构也在向云原生方向演进:
-
读写分离:通过复制技术实现读扩展
-
分片技术:水平分割数据到多个数据库实例
-
多主复制:支持多节点写入
-
自动故障转移:提高系统可用性
新硬件技术的挑战与机遇
新兴硬件技术正在改变数据库存储的设计考量:
-
NVMe SSD:极低延迟的持久化存储
-
持久内存:字节寻址的持久化内存
-
RDMA网络:远程直接内存访问,降低网络延迟
-
智能网卡:将部分计算任务卸载到网络设备
这些新技术促使数据库系统重新思考存储层次结构和事务处理机制。
结论
MySQL的存储架构,特别是基于B+树的InnoDB存储引擎,代表了数十年数据库理论研究和工程实践的结晶。从简单的顺序文件到精密的B+树索引,这一演进过程体现了计算机科学对效率、可靠性和可扩展性的不懈追求。
通过本文的分析,我们了解到:
-
B+树结构如何优化磁盘I/O,降低查询延迟
-
聚簇索引和二级索引的协同工作机制
-
缓冲池、变更缓冲区等组件如何提升整体性能
-
现代硬件和发展趋势对存储架构的影响
作为架构师,深入理解MySQL存储架构不仅有助于优化数据库性能,更能指导我们在设计数据密集型应用时做出合理的技术决策。在数据量持续增长、应用场景日益复杂的今天,这种深入的理解显得尤为宝贵。
随着技术的不断发展,MySQL存储架构将继续演进,但B+树作为其核心数据结构的地位在可预见的未来仍将稳固。理解这一基础,对于我们把握数据库技术的发展方向,设计高效可靠的存储系统,具有长远的意义。