自适应RAG
我们已经探索了多种改进RAG的方法:更好的分块、添加上下文、转换查询、重排序,甚至整合反馈。
自适应RAG工作流
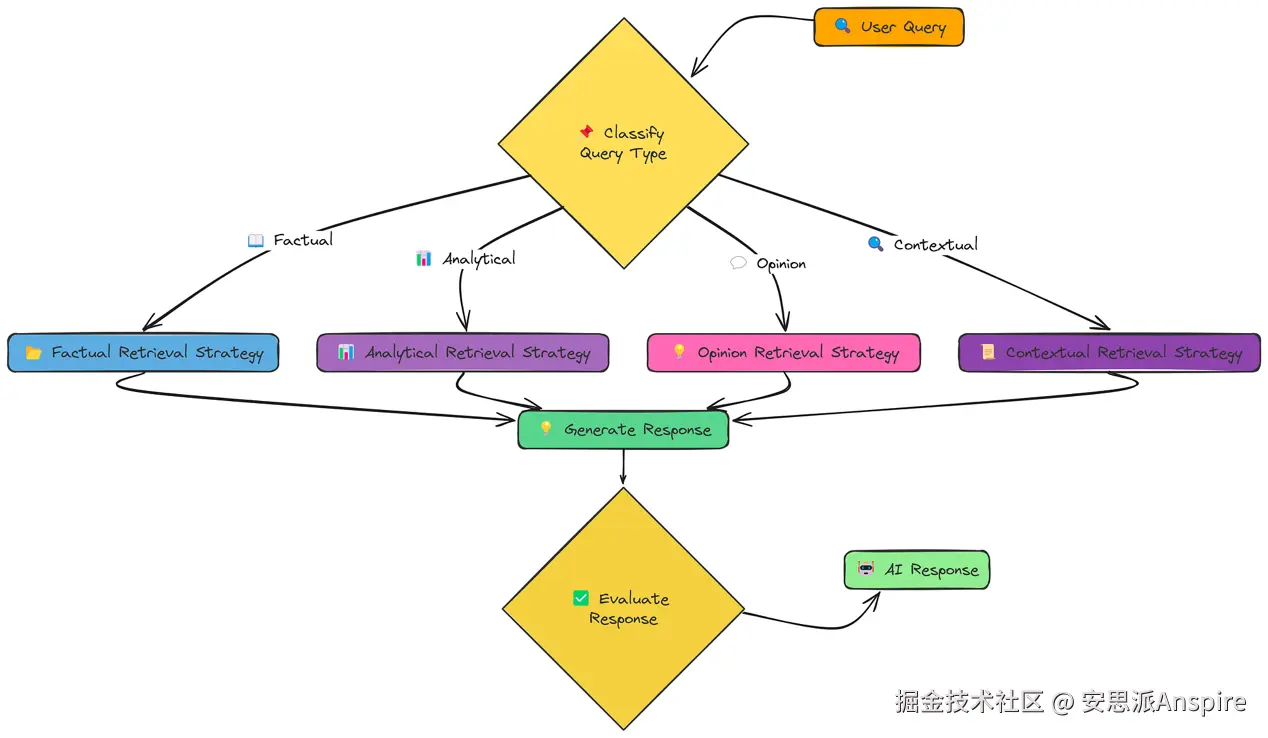
但如果最佳技术取决于所提出的问题类型呢?这就是Adaptive RAG背后的理念。
我们在这里使用四种不同的策略:
-
事实型策略:专注于检索精确的事实和数据。
-
分析型策略:旨在全面覆盖某个主题,探索不同方面。
-
观点型策略:尝试收集关于主观问题的多种观点。
-
语境型策略:整合用户特定的上下文以定制检索。
让我们看看它是如何工作的。我们将使用一个名为rag_with_adaptive_retrieval的函数来处理整个过程:
python
def rag_with_adaptive_retrieval(pdf_path, query, k=4, user_context=None):
"""
具有自适应检索功能的完整RAG管道。
"""
print("\n=== 自适应检索的RAG ===")
print(f"查询: {query}")
# 处理文档以提取文本、分块并创建嵌入
chunks, vector_store = process_document(pdf_path)
# 对查询进行分类以确定其类型
query_type = classify_query(query)
print(f"查询被分类为: {query_type}")
# 根据查询类型使用自适应检索策略检索文档
retrieved_docs = adaptive_retrieval(query, vector_store, k, user_context)
# 基于查询、检索到的文档和查询类型生成响应
response = generate_response(query, retrieved_docs, query_type)
# 将结果编译成字典
result = {
"query": query,
"query_type": query_type,
"retrieved_documents": retrieved_docs,
"response": response
}
print("\n=== 响应 ===")
print(response)
return result它首先使用一个名为classify_query的函数对查询进行分类,该函数与其他辅助函数一起定义。
根据识别出的类型,它选择并执行相应的专门检索策略(factual_retrieval_strategy、analytical_retrieval_strategy、opinion_retrieval_strategy或contextual_retrieval_strategy)。
最后,它使用generate_response来利用检索到的文档生成响应。
该函数返回一个包含结果的字典,包括查询、查询类型、检索到的文档和生成的响应。
让我们使用这个函数并对其进行评估:
ini
# 运行自适应RAG管道
result = rag_with_adaptive_retrieval(pdf_path, query)
# 评估。
evaluation_prompt = f"用户查询: {query}\nAI响应:\n{result['response']}\n真实响应: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
评估分数为0.86这次我们获得了约0.856的分数。
通过根据特定的查询类型调整我们的检索策略,我们可以获得比"一刀切"方法显著更好的结果。这凸显了理解用户意图并相应地定制RAG系统的重要性。
Adaptive RAG不是一个固定的流程,它是一个框架,让我们能够根据查询选择最佳策略。
Self RAG
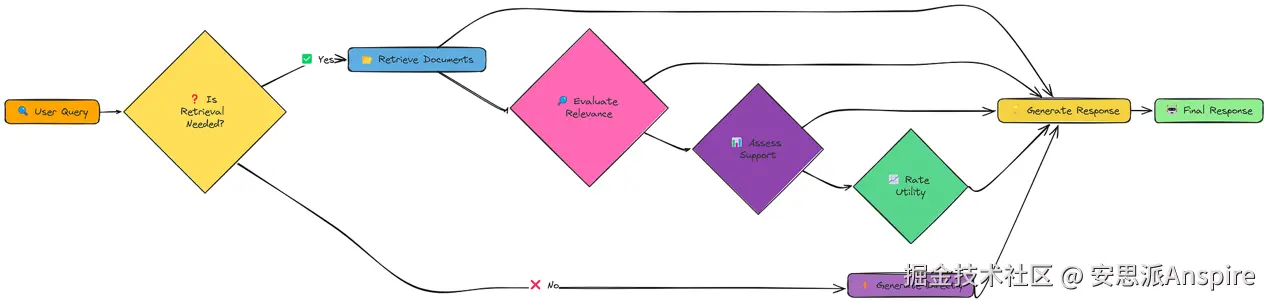
到目前为止,我们的RAG系统在很大程度上都是被动响应式 的。它们接收查询、检索信息,然后生成响应。而Self RAG采用了不同的方法:它是主动式 且具有反思能力的。
它不只是简单地检索和生成内容,还会思考是否需要检索、检索什么内容,以及如何使用检索到的信息。
Self RAG工作流
这些"反思"步骤使Self RAG比传统RAG更具动态性和适应性。它可以决定:
-
完全跳过检索。
-
采用不同策略进行多次检索。
-
丢弃不相关的信息。
-
优先处理有充分依据且有用的信息。
Self RAG的核心在于其生成"反思标记(reflection tokens)"的能力。这些是模型用于对自身流程进行推理的特殊标记。例如,它会为retrieval_needed(是否需要检索)、relevance(相关性)、support_rating(支持度评分)和utility_ratings(有用性评分)使用不同的标记。
模型通过组合这些标记来决定何时需要检索、何时不需要,以及LLM应基于什么依据生成最终响应。
首先,判断是否需要检索:
python
def determine_if_retrieval_needed(query):
"""
(示例说明 - 并非完全可运行)
判断给定查询是否需要检索。
"""
system_prompt = """你是一个判断回答查询是否需要检索的AI助手。
对于事实性问题、特定信息请求,或关于事件、人物、概念的问题,回答"Yes"。
对于观点类问题、假设性场景,或基于常识的简单查询,回答"No"。
仅用"Yes"或"No"回答。"""
user_prompt = f"Query: {query}\n\nIs retrieval necessary to answer this query accurately?"
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0
)
answer = response.choices[0].message.content.strip().lower()
return "yes" in answer这个determine_if_retrieval_needed函数(同样是简化版)使用LLM来判断是否需要外部信息。
-
对于像"法国的首都是什么?"这样的事实性问题,它可能返回False(LLM很可能已经知道答案)。
-
对于像"写一首诗......"这样的创作任务,它也可能返回False。
-
但对于更复杂或小众的查询,它会返回True。
下面是一个简化的相关性评估示例:
ini
def evaluate_relevance(query, context):
"""
(示例说明 - 并非完全可运行)
评估上下文与查询的相关性。
"""
system_prompt = """你是一个AI助手。判断一份文档是否与某个查询相关。
仅用"Relevant"或"Irrelevant"回答。"""
user_prompt = f"""Query: {query}
Document content:
{context[:500]}... [truncated]
Is this document relevant to the query? Answer with ONLY "Relevant" or "Irrelevant".
"""
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0
)
answer = response.choices[0].message.content.strip().lower()
return answer这个evaluate_relevance函数(同样是简化版)使用LLM来判断检索到的文档是否与查询相关。
这使Self RAG能够在生成响应之前过滤掉不相关的文档。
最后,我们可以这样调用所有这些功能:
ini
# 我们可以调用`self_rag`函数来实现self-rag,它会自动
# 决定何时检索、何时不检索。
result = self_rag(query, vector_store)
print(result["response"])
### 输出 ###
AI响应的评估分数为0.65我们在这里得到了0.6的分数。
这反映出:
-
Self RAG具有巨大的潜力,但完整实现非常复杂。
-
即便是我们展示的"是否需要检索"这一步骤,有时也可能出错。
-
我们尚未展示完整的"反思"过程,因此无法声称更高的分数。
关键要点是,Self RAG旨在让RAG系统更智能、更具适应性。它朝着能够对自身知识和检索需求进行推理的LLM迈出了一步。
知识图谱
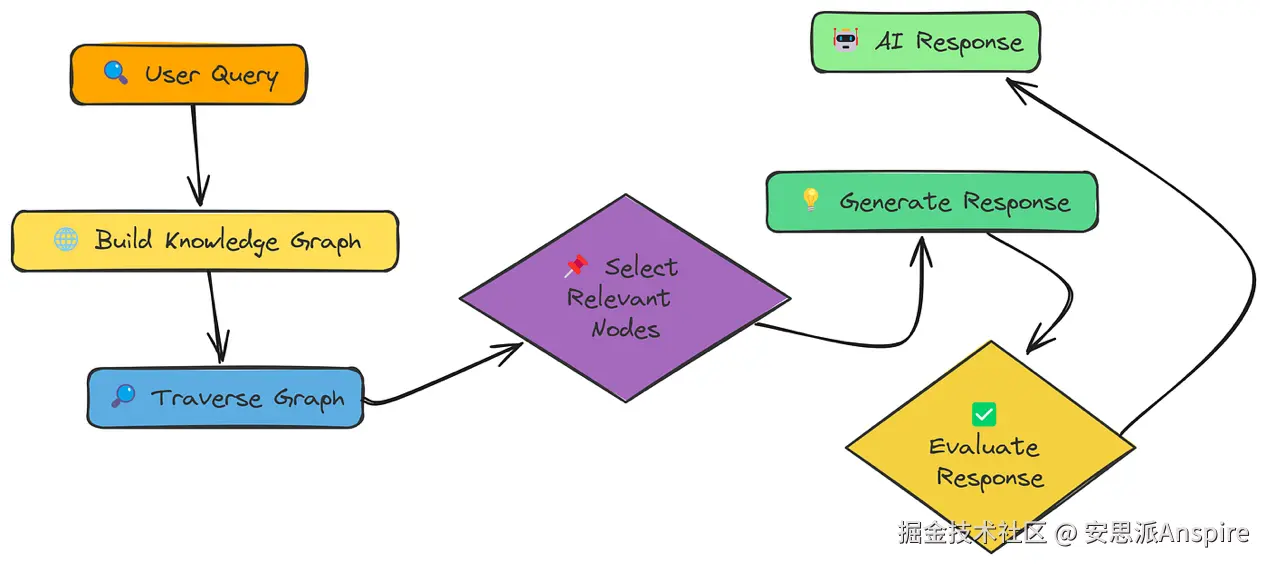
到目前为止,我们的RAG系统一直将文档视为独立chunk的集合。但如果信息之间是相互关联的呢?如果理解一个概念需要先理解相关概念呢?这就是图RAG(Graph RAG)的用武之地。
图RAG并非将信息组织成扁平的chunk列表,而是以知识图谱的形式来整合信息。可以把它想象成一个网络:
-
节点(Nodes):代表概念、实体或信息片段(类似我们的文本chunk)。
-
边(Edges):代表这些节点之间的关系。
知识图谱工作流
其核心思想是,通过遍历这个图谱,我们不仅能找到直接相关的信息,还能发现提供关键上下文的间接相关信息。
让我们通过一些简化代码来看看核心步骤是如何工作的。首先,构建知识图谱:
python
def build_knowledge_graph(chunks):
"""
使用嵌入和概念提取从文本chunk构建知识图谱。
参数:
chunks(dict列表):文本chunk列表,每个都包含一个"text"字段。
返回:
元组:(以文本chunk为节点的图谱,嵌入列表)
"""
graph, texts = nx.Graph(), [c["text"] for c in chunks]
embeddings = create_embeddings(texts) # 计算嵌入
# 添加带有提取的概念和嵌入的节点
for i, (chunk, emb) in enumerate(zip(chunks, embeddings)):
graph.add_node(i, text=chunk["text"], concepts := extract_concepts(chunk["text"]), embedding=emb)
# 基于共享概念和嵌入相似度创建边
for i, j in ((i, j) for i in range(len(chunks)) for j in range(i + 1, len(chunks))):
if shared_concepts := set(graph.nodes[i]["concepts"]) & set(graph.nodes[j]["concepts"]):
sim = np.dot(embeddings[i], embeddings[j]) / (np.linalg.norm(embeddings[i]) np.linalg.norm(embeddings[j]))
weight = 0.7 * sim + 0.3 * (len(shared_concepts) / min(len(graph.nodes[i]["concepts"]), len(graph.nodes[j]["concepts"])))
if weight > 0.6:
graph.add_edge(i, j, weight=weight, similarity=sim, shared_concepts=list(shared_concepts))
print(f"图谱构建完成:{graph.number_of_nodes()}个节点,{graph.number_of_edges()}条边")
return graph, embeddings它接收查询、图谱和嵌入,返回相关节点列表和遍历路径。
最后,我们有一个graph_rag_pipeline函数,它会用到上述两个函数:
python
def graph_rag_pipeline(pdf_path, query, chunk_size=1000, chunk_overlap=200, top_k=3):
"""
从文档到答案的完整图RAG流程。
"""
# 从PDF文档中提取文本
text = extract_text_from_pdf(pdf_path)
# 将提取的文本分割为重叠的chunk
chunks = chunk_text(text, chunk_size, chunk_overlap)
# 从文本chunk构建知识图谱
graph, embeddings = build_knowledge_graph(chunks)
# 遍历知识图谱以找到与查询相关的信息
relevant_chunks, traversal_path = traverse_graph(query, graph, embeddings, top_k)
# 基于查询和相关chunk生成响应
response = generate_response(query, relevant_chunks)
# 返回查询、响应、相关chunk、遍历路径和图谱
return {
"query": query,
"response": response,
"relevant_chunks": relevant_chunks,
"traversal_path": traversal_path,
"graph": graph
}让我们用它来生成响应:
ini
# 执行图RAG流程以处理文档并回答查询
results = graph_rag_pipeline(pdf_path, query)
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{results['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
0.78我们得到了约0.78的分数。
图RAG的表现虽未超过更简单的方法,但它能够捕捉信息片段之间的关系,而不仅仅是单个信息片段本身。
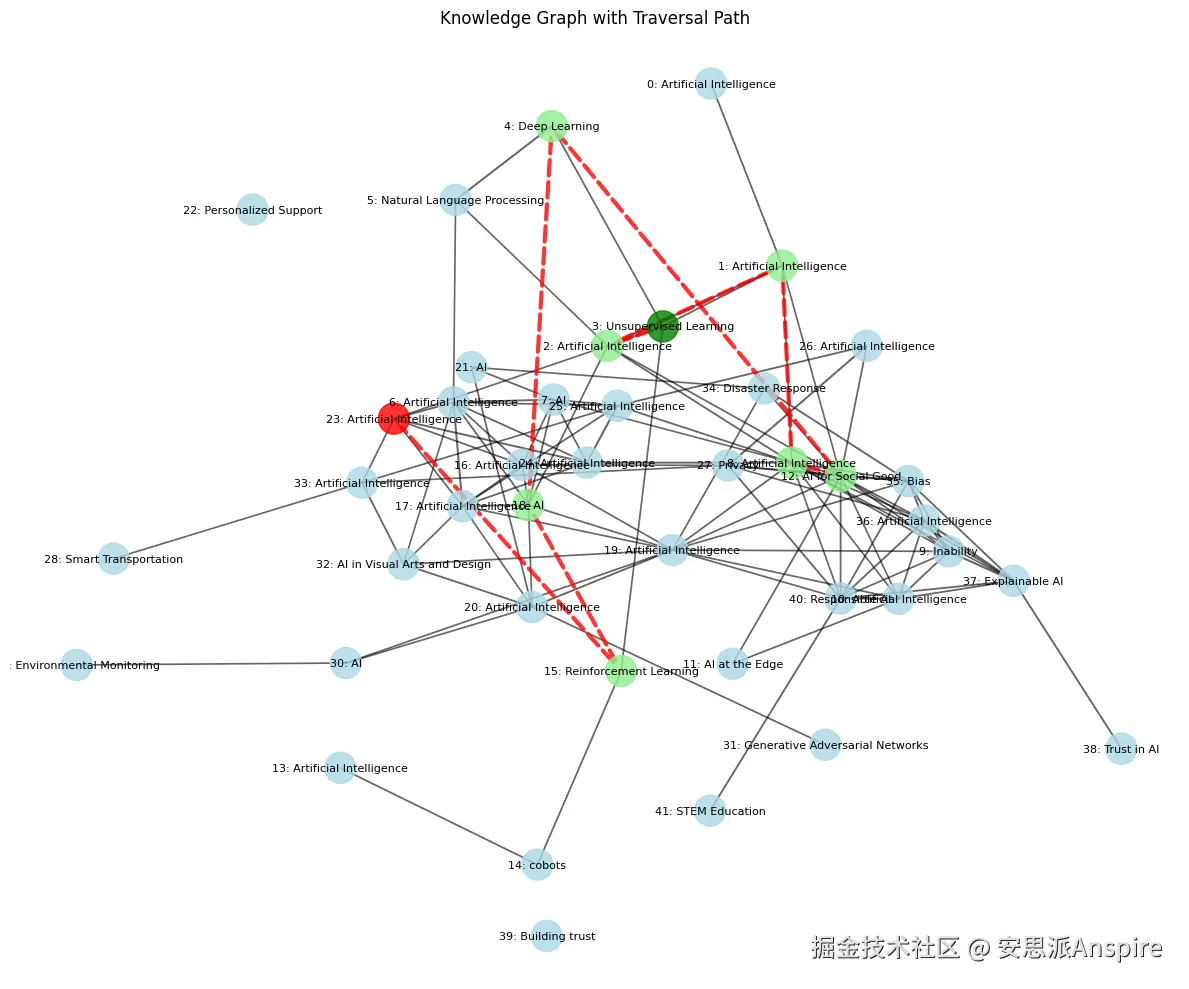
验证用PDF上的知识图谱
这对于需要理解概念间联系的复杂查询来说尤其有用。
层级索引
我们已经探索了多种改进RAG的方法:更好的分块、上下文增强、查询转换、重排序,甚至基于图的检索。但这里存在一个根本性的权衡:
-
小分块:有利于精确匹配,但会丢失上下文。
-
大分块:能保留上下文,但可能导致检索相关性降低。
层级索引(Hierarchical Indices)提供了一种解决方案:我们创建两个层级的表示形式:
-
摘要(Summaries):文档较大章节的简洁概述。
-
详细分块(Detailed Chunks):这些章节内的更小分块。
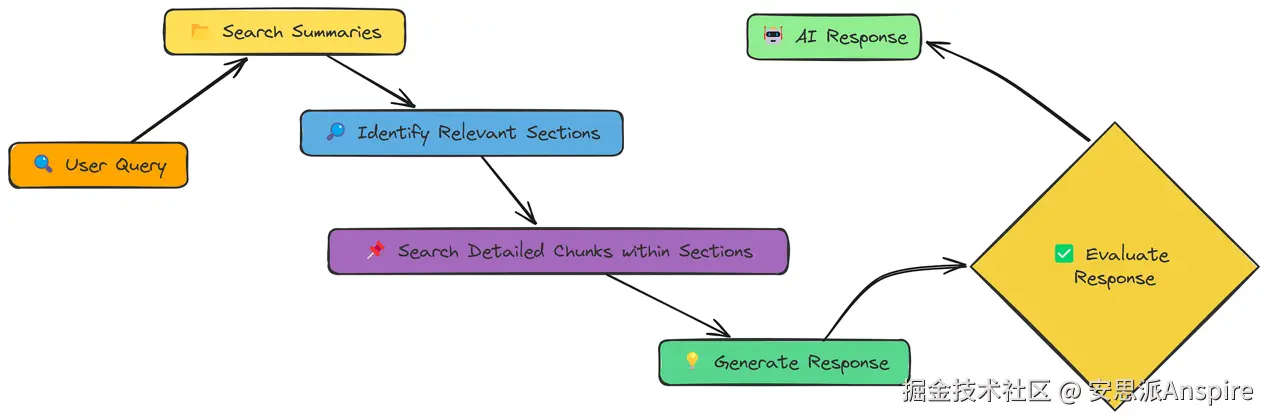
层级索引工作流
-
首先,搜索摘要:这能快速缩小文档的相关章节范围。
-
然后,仅在这些章节内搜索详细分块:这既保证了小分块的精确性,又保留了较大章节的上下文。
让我们通过一个名为hierarchical_rag的函数来看看它的实际应用:
python
def hierarchical_rag(query, pdf_path, chunk_size=1000, chunk_overlap=200,
k_summaries=3, k_chunks=5, regenerate=False):
"""
完整的层级检索增强生成(RAG)流程。
参数:
query(str):用户查询。
pdf_path(str):PDF文档的路径。
chunk_size(int):用于处理的文本chunk大小。
chunk_overlap(int):连续chunk之间的重叠部分。
k_summaries(int):要检索的顶级摘要数量。
k_chunks(int):每个摘要下要检索的详细chunk数量。
regenerate(bool):是否重新处理文档。
返回:
dict:包含查询、生成的响应、检索到的chunk,以及摘要和详细chunk的数量。
"""
# 定义用于缓存摘要和详细向量存储的文件名
summary_store_file = f"{os.path.basename(pdf_path)}_summary_store.pkl"
detailed_store_file = f"{os.path.basename(pdf_path)}_detailed_store.pkl"
# 如果需要重新生成或缓存文件不存在,则处理文档
if regenerate or not os.path.exists(summary_store_file) or not os.path.exists(detailed_store_file):
print("正在处理文档并创建向量存储...")
summary_store, detailed_store = process_document_hierarchically(pdf_path, chunk_size, chunk_overlap)
# 保存处理后的存储以供将来使用
with open(summary_store_file, 'wb') as f:
pickle.dump(summary_store, f)
with open(detailed_store_file, 'wb') as f:
pickle.dump(detailed_store, f)
else:
# 从缓存加载现有的向量存储
print("正在加载现有的向量存储...")
with open(summary_store_file, 'rb') as f:
summary_store = pickle.load(f)
with open(detailed_store_file, 'rb') as f:
detailed_store = pickle.load(f)
# 使用层级搜索检索相关chunk
retrieved_chunks = retrieve_hierarchically(query, summary_store, detailed_store, k_summaries, k_chunks)
# 基于检索到的chunk生成响应
response = generate_response(query, retrieved_chunks)
# 返回带有元数据的结果
return {
"query": query,
"response": response,
"retrieved_chunks": retrieved_chunks,
"summary_count": len(summary_store.texts),
"detailed_count": len(detailed_store.texts)
}这个hierarchical_rag函数处理两阶段检索流程:
-
首先,它搜索summary_store以找到最相关的摘要。
-
然后,它搜索detailed_store,但只在属于顶级摘要的chunk中进行。这比搜索所有详细chunk效率高得多。
该函数还包含一个regenerate参数,用于决定是创建新的向量存储还是使用现有的。
让我们用它来回答查询并进行评估:
ini
# 运行层级RAG流程
result = hierarchical_rag(query, pdf_path)我们检索并生成响应。最后,看看评估分数:
python
# 评估。
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{result['response']}\n真实响应:{reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出
0.84我们的分数是0.84。
层级检索给出了迄今为止最好的分数。我们既获得了搜索摘要的速度,又获得了搜索小分块的精确性,此外还加上了每个分块所属章节带来的额外上下文。这就是为什么它通常是性能顶尖的RAG策略之一。
今天的内容到此结束了,但我们的RAG主题还未完结,我们将在下一次的文章中继续更新,欢迎持续关注!