XML(可扩展标记语言)是一种广泛用于存储和传输数据的格式,因其具有良好的可读性和可扩展性,在许多领域都有应用。
实现思路:
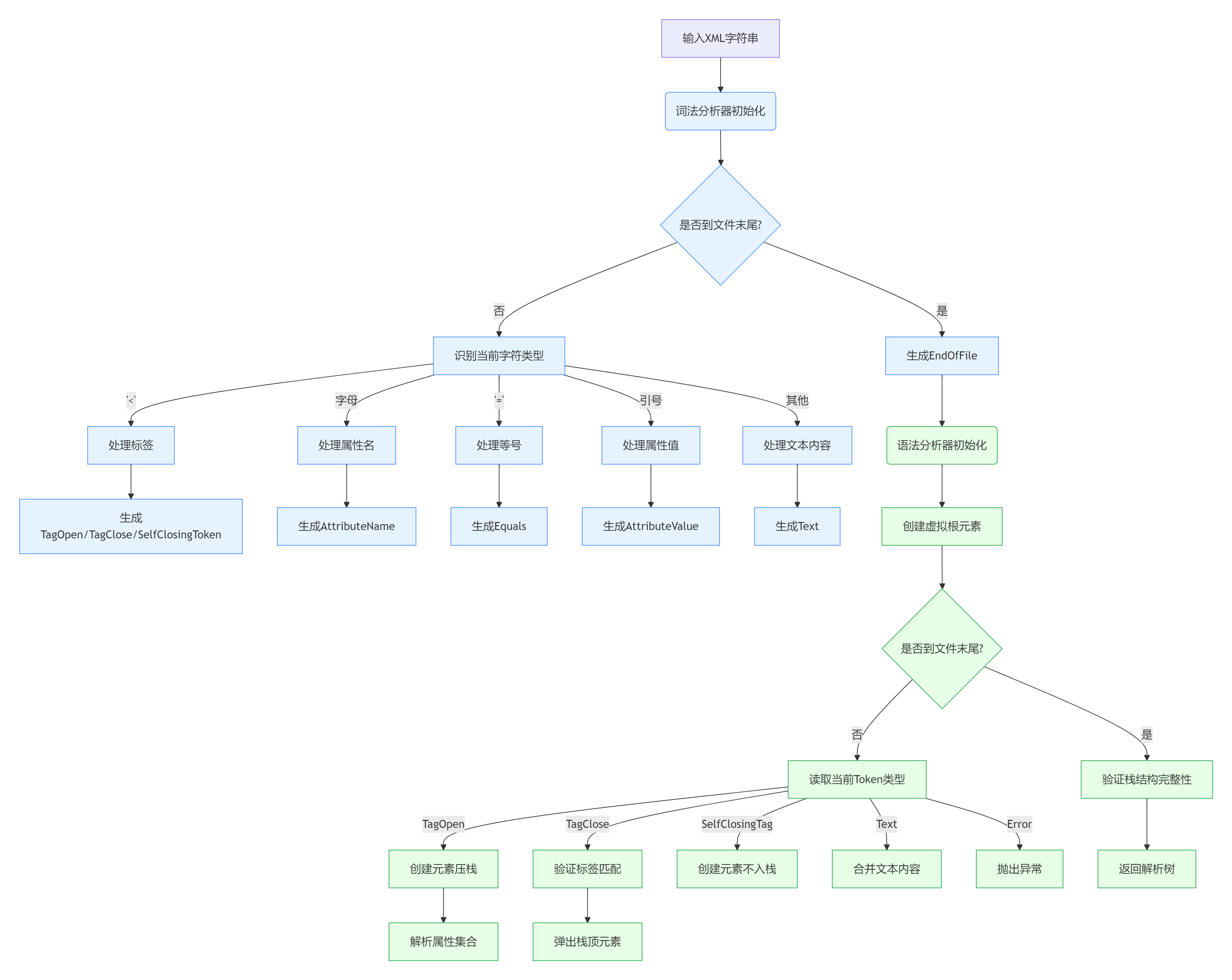
词法分析
词法分析的目的是将输入的 XML 字符串分解为一个个的词法单元,例如开始标签、结束标签、属性、文本等。我们可以定义一个XMLToken类来表示词法单元,以及一个Scanner类来进行词法分析。
语法分析
语法分析的目的是根据词法单元构建 XML 文档的树形结构。我们可以定义一个MXmlParser类来进行语法分析,它将接收一个XMLToken作为输入,并返回解析后的 XML 文档树。
流程图:
代码实现:
1.定义XMLToken类:
cs
// -------------------- 词法分析器部分 --------------------
public enum XMLTokenType
{
TagOpen, // 开始标签 <element
TagClose, // 闭合标签 </element
SelfClosingTag, // 自闭合标签 <element/>
AttributeName, // 属性名 name
Equals, // 等号 =
AttributeValue, // 属性值 "value"
Text, // 文本内容
EndOfFile, // 文件结束
Error // 错误标记
}
public class XMLToken
{
public XMLTokenType Type { get; }
public string Value { get; }
public int Position { get; } // 用于错误定位
public XMLToken(XMLTokenType type, string value = null, int pos = -1)
{
Type = type;
Value = value;
Position = pos;
}
}2.定义XML元素类:
cs
// -------------------- 数据结构 --------------------
public class XMLElement
{
public string Name { get; set; }
public Dictionary<string, string> Attributes { get; } = new Dictionary<string, string>();
public List<XMLElement> Children { get; } = new List<XMLElement>();
public string TextContent { get; set; }
public bool IsSelfClosing { get; set; }
public int StartPosition { get; set; }
}
public class XMLParseException : Exception
{
public int ErrorPosition { get; }
public XMLParseException(string message, int position) : base($"{message} (at position {position})")
{
ErrorPosition = position;
}
}2.定义扫描类:
cs
public class XMLScanner : MonoBehaviour
{
private int _position; // 当前扫描位置
private string _input; // 输入XML字符串
// 构造函数
public XMLScanner(string input)
{
_input = input.Trim(); // 去除首尾空白
_position = 0; // 初始化扫描位置
}
// 获取下一个词法单元
public XMLToken NextToken()
{
while (true)
{ // 使用循环代替递归防止栈溢出
SkipWhitespace(); // 跳过空白字符
// 检查是否到达文件末尾
if (_position >= _input.Length)
{
return new XMLToken(XMLTokenType.EndOfFile, pos: _position);
}
char current = _input[_position]; // 获取当前字符
// 处理标签结构 -------------------------------------------------
if (current == '<')
{
_position++; // 跳过'<'
// 处理闭合标签 </tag>
if (_position < _input.Length && _input[_position] == '/')
{
_position++; // 跳过'/'
string tagName = ReadName(); // 读取标签名
SkipWhitespace();
// 跳过闭合标签的'>'
if (_position < _input.Length && _input[_position] == '>')
{
_position++;
}
return new XMLToken(XMLTokenType.TagClose, tagName);
}
// 处理开始标签或自闭合标签
else
{
string tagName = ReadName(); // 读取标签名
SkipWhitespace();
return new XMLToken(XMLTokenType.TagOpen, tagName);
}
}
// 处理自闭合标签结尾 -------------------------------------------
if (current == '/' && _position + 1 < _input.Length && _input[_position + 1] == '>')
{
_position += 2; // 跳过'/>'
return new XMLToken(XMLTokenType.SelfClosingTag);
}
// 处理属性名 ---------------------------------------------------
//<name id = ""><name> 和<name> John </name>
if (IsNameStartChar(current) && _input[_position - 1] != '>')
{
string name = ReadName(); // 读取属性名
return new XMLToken(XMLTokenType.AttributeName, name);
}
// 处理等号 -----------------------------------------------------
if (current == '=')
{
_position++; // 跳过'='
return new XMLToken(XMLTokenType.Equals);
}
// 处理属性值 ---------------------------------------------------
if (current == '"' || current == '\'')
{
char quote = current; // 记录引号类型
_position++; // 跳过起始引号
int start = _position; // 记录值起始位置
// 查找闭合引号
while (_position < _input.Length && _input[_position] != quote)
{
_position++;
}
// 错误处理:未闭合的引号
if (_position >= _input.Length)
{
return new XMLToken(XMLTokenType.Error, "Unclosed quotation");
}
string value = _input.Substring(start, _position - start);
_position++; // 跳过闭合引号
return new XMLToken(XMLTokenType.AttributeValue, value);
}
// 处理标签闭合符 -----------------------------------------------
if (current == '>')
{
_position++; // 跳过'>'
continue; // 继续处理后续内容
}
// 处理文本内容 -------------------------------------------------
if (!char.IsWhiteSpace(current))
{
int start = _position;
// 收集直到下一个'<'之前的内容
while (_position < _input.Length && _input[_position] != '<')
{
_position++;
}
string text = _input.Substring(start, _position - start).Trim();
if (!string.IsNullOrEmpty(text))
{
return new XMLToken(XMLTokenType.Text, text);
}
}
// 未知字符处理 -------------------------------------------------
return new XMLToken(XMLTokenType.Error, $"Unexpected character: {current}");
}
}
// 读取符合XML规范的名称(标签名/属性名)
private string ReadName()
{
var sb = new StringBuilder();
while (_position < _input.Length && IsNameChar(_input[_position]))
{
sb.Append(_input[_position]);
_position++;
}
return sb.ToString();
}
// 检查是否为名称起始字符
private bool IsNameStartChar(char c)
{
// char.IsLetter(c) 指示指定的 Unicode 字符是否属于 Unicode 字母类别。
return char.IsLetter(c) || c == '_' || c == ':'; // 允许字母、下划线和冒号
}
// 检查是否为名称有效字符
private bool IsNameChar(char c)
{
return IsNameStartChar(c) || // 包含起始字符
char.IsDigit(c) || // 允许数字
c == '-' || // 允许连字符
c == '.'; // 允许点号
}
// 跳过空白字符
private void SkipWhitespace()
{
while (_position < _input.Length && char.IsWhiteSpace(_input[_position]))
{
_position++;
}
}
}3.定义解析类:
cs
// -------------------- 语法解析器部分 --------------------
using System.Collections.Generic;
using System.Linq;
public class XMLParser
{
private XMLScanner _scanner;
private XMLToken _currentToken;
private Stack<XMLElement> _stack = new Stack<XMLElement>();
private XMLElement _root;
public XMLElement Parse(string xml)
{
_scanner = new XMLScanner(xml);
_currentToken = _scanner.NextToken();
_root = new XMLElement { Name = "__root__" };
_stack.Push(_root);
while (_currentToken.Type != XMLTokenType.EndOfFile)
{
UnityEngine.Debug.Log($"{_currentToken.Type},{_currentToken.Value}");
switch (_currentToken.Type)
{
case XMLTokenType.TagOpen:
ParseOpenTag();
break;
case XMLTokenType.TagClose:
ParseCloseTag();
break;
case XMLTokenType.SelfClosingTag:
ParseSelfClosingTag();
break;
case XMLTokenType.Text:
ParseText();
break;
case XMLTokenType.Error:
throw new XMLParseException(_currentToken.Value, _currentToken.Position);
default:
Advance();
break;
}
}
ValidateStructure();
return _root.Children.FirstOrDefault();
}
private void ParseOpenTag()
{
var element = new XMLElement
{
Name = _currentToken.Value,
StartPosition = _currentToken.Position
};
_stack.Peek().Children.Add(element);
_stack.Push(element);
Advance();
ParseAttributes();
if (_currentToken.Type == XMLTokenType.SelfClosingTag)
{
_stack.Pop(); // 自闭合标签不保留在栈中
Advance();
}
}
private void ParseAttributes()
{
while (_currentToken.Type == XMLTokenType.AttributeName)
{
string key = _currentToken.Value;
Advance();
if (_currentToken.Type != XMLTokenType.Equals)
throw new XMLParseException($"Missing '=' after attribute '{key}'", _currentToken.Position);
Advance();
if (_currentToken.Type != XMLTokenType.AttributeValue)
throw new XMLParseException($"Missing value for attribute '{key}'", _currentToken.Position);
_stack.Peek().Attributes[key] = _currentToken.Value;
Advance();
}
}
private void ParseCloseTag()
{
if (_stack.Count <= 1) // 防止弹出根元素
throw new XMLParseException("Unexpected closing tag", _currentToken.Position);
string expected = _stack.Pop().Name;
if (expected != _currentToken.Value)
throw new XMLParseException($"Mismatched tag: </{_currentToken.Value}> expected </{expected}>", _currentToken.Position);
Advance();
}
private void ParseSelfClosingTag()
{
var element = new XMLElement
{
Name = _currentToken.Value,
IsSelfClosing = true
};
_stack.Peek().Children.Add(element);
Advance();
}
private void ParseText()
{
if (!string.IsNullOrWhiteSpace(_currentToken.Value))
_stack.Peek().TextContent += _currentToken.Value + " ";
Advance();
}
private void ValidateStructure()
{
if (_stack.Count != 1)
throw new XMLParseException($"Unclosed tag: {_stack.Peek().Name}", _stack.Peek().StartPosition);
}
private void Advance() => _currentToken = _scanner.NextToken();
}4.测试类:
cs
public class XMLTest : MonoBehaviour
{
string xml = @"<root>
<person id = '123'>
<name>John</name>
<age>30</age>
</person>
</root>"
;
void Start()
{
var parser = new XMLParser();
var root = parser.Parse(xml);
Debug.Log(root.Children[0].Attributes["id"]); // 输出 "123"
}
}结果:
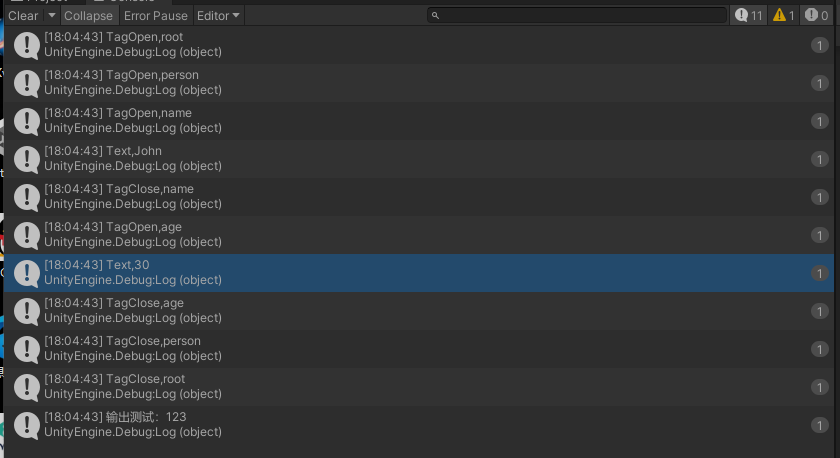
参考链接:
2020 年 JuliaCon |从头开始创建 XML 解析器 |埃里克·恩海姆 - YouTube
Parse XML Files with Python - Basics in 10 Minutes - YouTube