Decoder Layer
解码器层结构
-
Transformer解码器层由三种核心组件构成:
-
Masked多头自注意力:关注解码器序列当前位置之前的上下文(因果掩码)
-
Encoder-Decoder多头注意力:关注编码器输出的相关上下文
-
前馈神经网络:进行非线性特征变换
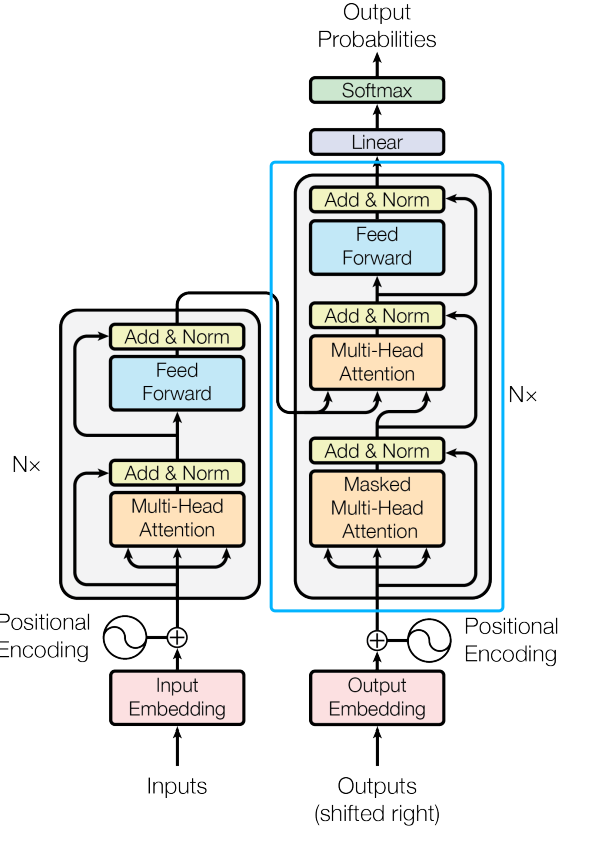
今天这里实现的是上图中蓝色框中的单层DecoderLayer,不包含 embedding和位置编码,以及最后的Linear和Softmax。
主要处理流程:
- Decoder 的Masked自注意力
- Encoder-Decoder自注意力
- 前馈神经网络:进行非线性特征变换
- 残差连接 + 层归一化
- Dropout:最终输出前进行随机失活
-
数学表达
-
解码器层计算过程分为三个阶段:
- Masked自注意力阶段:
MaskedAtt ( Q , K , V ) = LayerNorm ( MultiHead ( Q , K , V ) + R e s i d u a l ) \text{MaskedAtt}(Q,K,V) = \text{LayerNorm}(\text{MultiHead}(Q,K,V) + Residual) MaskedAtt(Q,K,V)=LayerNorm(MultiHead(Q,K,V)+Residual)
2. Encoder-Decoder注意力阶段:CrossAtt ( Q d e c , K e n c , V e n c ) = LayerNorm ( MultiHead ( Q d e c , K e n c , V e n c ) + R e s i d u a l ) \text{CrossAtt}(Q_{dec}, K_{enc}, V_{enc}) = \text{LayerNorm}(\text{MultiHead}(Q_{dec},K_{enc},V_{enc}) + Residual) CrossAtt(Qdec,Kenc,Venc)=LayerNorm(MultiHead(Qdec,Kenc,Venc)+Residual)
3. 前馈网络阶段:FFN ( x ) = LayerNorm ( ReLU ( x W 1 + b 1 ) W 2 + b 2 + x ) \text{FFN}(x) = \text{LayerNorm}(\text{ReLU}(xW_1 + b_1)W_2 + b_2 + x) FFN(x)=LayerNorm(ReLU(xW1+b1)W2+b2+x)
其中:
- d_model 为模型维度
- Residual 为残差连接
- 下标dec来源于Decoder自己的输出,下标enc为Encoder的输出
代码实现
-
实现单层
其他层的实现
层名 链接 PositionEncoding https://blog.csdn.net/hbkybkzw/article/details/147431820 calculate_attention https://blog.csdn.net/hbkybkzw/article/details/147462845 MultiHeadAttention https://blog.csdn.net/hbkybkzw/article/details/147490387 FeedForward https://blog.csdn.net/hbkybkzw/article/details/147515883 LayerNorm https://blog.csdn.net/hbkybkzw/article/details/147516529 EncoderLayer https://blog.csdn.net/hbkybkzw/article/details/147591824 下面统一在before.py中导入
-
实现单层的DecoderLayer
pythonimport torch from torch import nn from before import PositionEncoding,calculate_attention,MultiHeadAttention,FeedForward,LayerNorm class DecoderLayer(nn.Module): def __init__(self, n_heads, d_model, ffn_hidden, dropout_prob=0.1): super(DecoderLayer, self).__init__() self.masked_att = MultiHeadAttention(n_heads=n_heads, d_model=d_model, dropout_prob=dropout_prob) self.att = MultiHeadAttention(n_heads=n_heads, d_model=d_model, dropout_prob=dropout_prob) self.norms = nn.ModuleList([LayerNorm(d_model=d_model) for _ in range(3)]) # 三个归一化层 self.ffn = FeedForward(d_model=d_model, ffn_hidden=ffn_hidden, dropout_prob=dropout_prob) self.dropout = nn.Dropout(dropout_prob) def forward(self, x, encoder_kv, dst_mask=None, src_dst_mask=None): # 第一阶段:Decoder 的Masked自注意力 _x = x mask_att_out = self.masked_att(q=x, k=x, v=x, mask=dst_mask) mask_att_out = self.norms[0](mask_att_out + _x) # 残差连接后归一化 # 第二阶段:Encoder-Decoder注意力 _x = mask_att_out att_out = self.att(q=mask_att_out, k=encoder_kv, v=encoder_kv, mask=src_dst_mask) att_out = self.norms[1](att_out + _x) # 第三阶段:前馈网络 _x = att_out ffn_out = self.ffn(att_out) ffn_out = self.norms[2](ffn_out + _x) return self.dropout(ffn_out) -
注意力掩码机制
掩码类型 作用域 功能描述 dst_mask目标序列自注意力 防止当前位置关注未来信息(因果掩码) src_dst_mask编码器-解码器注意力 控制解码器查询对编码器键值对的访问权限 -
参数说明
参数名 类型 说明 n_headsint 注意力头数量 d_modelint 模型隐藏层维度 ffn_hiddenint 前馈网络中间层维度(通常4倍) dropout_probfloat Dropout概率(默认0.1)
使用示例
-
测试代码
pythonif __name__ == "__main__": # 实例化解码器层:8头,512维,前馈层2048,20% dropout decoder_layer = DecoderLayer(n_heads=8, d_model=512, ffn_hidden=2048, dropout_prob=0.2) # 模拟输入:batch_size=4,目标序列长度50,编码器输出长度80 x = torch.randn(4, 50, 512) encoder_out = torch.randn(4, 80, 512) tgt_mask = None src_mask = None output = decoder_layer(x, encoder_out, dst_mask=tgt_mask, src_dst_mask=src_mask) print("输入形状:", x.shape) print("encode_kv 形状:", encoder_out.shape) print("输出形状:", output.shape)