Python数据处理:文件的自动化重命名与整合
本文将介绍如何使用Python自动化处理财务报表文件,实现从个体公司到行业维度的数据整合。
需求
在实际工作中,我们通常会收集到多家公司的财务报表,文件命名格式为"公司名称_报表类型.csv",例如"某软件有限公司_资产负债表.csv"。当需要进行行业分析时,我们希望将同类型的报表整合,重命名为"行业_报表类型.csv"的格式。手动操作不仅耗时,还容易出错,因此自动化处理成为必然选择。
解决方案
以下是一个Python脚本,可以自动扫描指定文件夹中的CSV财务报表文件,并按照报表类型进行重命名:
python
import os
import pandas as pd
import re
# 指定文件夹路径
folder_path = r"D:\123"
# 检查文件夹是否存在
if not os.path.exists(folder_path):
print(f"文件夹 {folder_path} 不存在")
exit(1)
# 获取文件夹中的所有文件
files = os.listdir(folder_path)
# 定义文件类型和对应的新命名模式
file_types = {
"资产负债表": "行业_资产负债表.csv",
"利润表": "行业_利润表.csv",
"现金流量表": "行业_现金流量表.csv"
}
# 处理文件
processed_count = 0
for file in files:
if file.endswith(".csv"):
# 查找匹配的文件类型
for file_type in file_types:
if file_type in file:
# 找到匹配的文件类型
old_path = os.path.join(folder_path, file)
new_path = os.path.join(folder_path, file_types[file_type])
# 如果目标文件已存在,先删除
if os.path.exists(new_path):
os.remove(new_path)
# 重命名文件
os.rename(old_path, new_path)
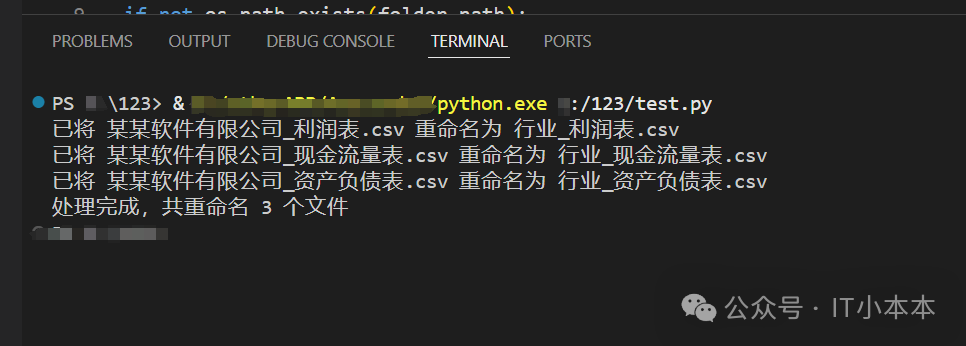
print(f"已将 {file} 重命名为 {file_types[file_type]}")
processed_count += 1
break
print(f"处理完成,共重命名 {processed_count} 个文件")代码解析
1. 环境准备
首先导入必要的库:os用于文件操作,pandas用于数据处理,re用于正则表达式匹配(虽然在当前代码中未使用,但在更复杂的匹配场景中很有用)。
2. 文件夹路径设置
指定要处理的文件夹路径,并验证其是否存在。这是一个基本的错误处理机制,确保在文件夹不存在时及时终止程序。
3. 文件类型定义
创建一个字典,将原始报表类型映射到目标文件名。这样设计使代码更具扩展性,如果日后需要处理更多类型的报表,只需在字典中添加对应映射即可。
4. 文件处理循环
遍历文件夹中的所有文件,对每个CSV文件进行处理:
- 检查文件名是否包含我们关注的报表类型
- 构建原路径和新路径
- 如果目标文件已存在,先删除它(避免命名冲突)
- 重命名文件
- 输出处理结果并计数
5. 结果统计
最后输出处理的文件总数,方便用户了解操作结果。