目的
通过编写程序爬取互联网上的优质资源
爬虫必须要使用python吗
非也~
编程语言知识工具,抓取到数据才是目的,而大多数爬虫采用python语言编写的原因是python的语法比较简单,python写爬虫比较简单!好用!而且python有很多第三方支持的库。很多繁琐复杂的工作直接交给这些第三方库就可以,自己不需要做这些额外的准备工作只需要导入库就好
爬虫合法吗
爬虫在法律上不禁止,但是有违反的风险(类比菜刀,法律上允许菜刀的存在,但是有人会使用菜刀做一些非法的事)
爬虫分为善意的和恶意的,如下图所示

反爬机制
门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取,如加密机制
反反爬机制
爬虫程序通过制定相关的策略或者技术手段,破解门户网站的反爬机制,获取门户网站的相关数据
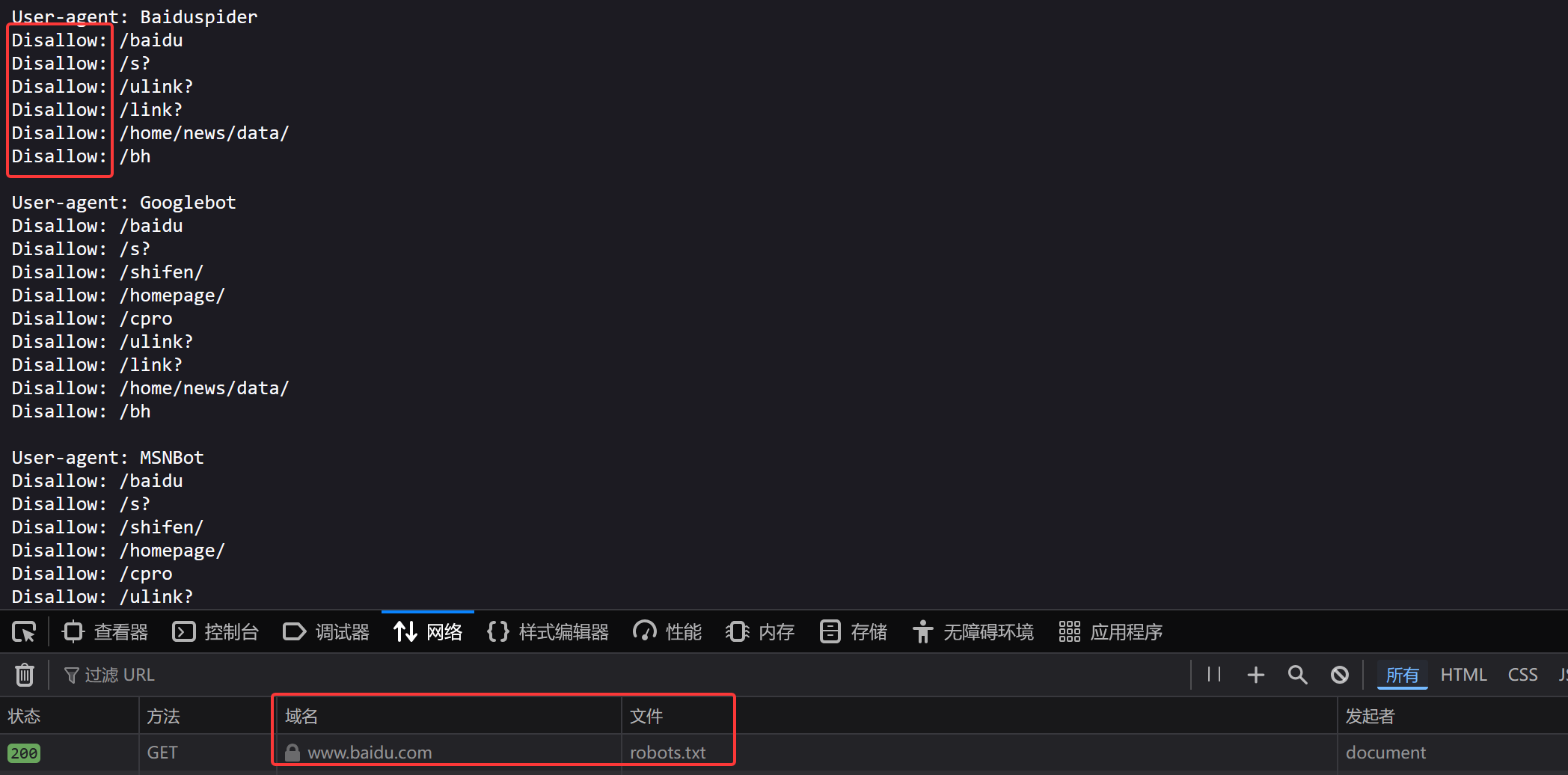
robots.txt协议
君子协议(防君子不防小人),规定了网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取,所有网站的君子协议所在地都是,网站名后加子目录/robots.txt,如下面的百度的君子协议
网址:https://www.baidu.com/robots.txt
第一个爬虫程序
使用工具:pycharm

爬取百度页面的资源
代码:
python
from urllib.request import urlopen
url = "https://www.baidu.com"
response = urlopen(url)#打开网址会返回响应的数据
#response.read()读取响应回的数据中的内容(内容是字节的形式,所以要解码成文字)
with open("myBaidu.html", mode="w",encoding="utf-8") as f:#写入模式
f.write(response.read().decode("utf-8"))保存文件中的内容:
点击谷歌浏览器,对爬取到的html页面进行打开

结果如下图,和真正的百度页面完全相同

为什么拿到的是html代码,浏览器页面显示却不是?
其实浏览器拿到的也是html代码,只是浏览器会把html代码(源代码)运行成正常的页面动画及数据,因此爬虫读取到的实际上是网页的源代码