深度循环神经网络
更深
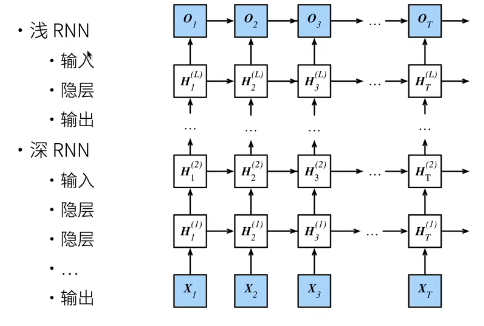
H t 1 = f 1 ( H t − 1 1 , X t ) ⋮ H t j = f j ( H t − 1 j , H t j − 1 ) ⋮ O t = g ( H t L ) \begin{aligned} \mathbf{H}t^1 &= f_1(\mathbf{H}{t-1}^1, \mathbf{X}_t) \\ &\vdots \\ \mathbf{H}t^j &= f_j(\mathbf{H}{t-1}^j, \mathbf{H}_t^{j-1}) \\ &\vdots \\ \mathbf{O}_t &= g(\mathbf{H}_t^L) \end{aligned} Ht1HtjOt=f1(Ht−11,Xt)⋮=fj(Ht−1j,Htj−1)⋮=g(HtL)
总结
深度循环神经网络使用多个隐藏层来获得更多的非线性性
代码实现
导入必要的环境和数据集
python
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)隐藏单元的数量仍然是 256 256 256。现在通过num_layers的值来设定隐藏层数
python
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)训练
python
num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr*1.0, num_epochs, device)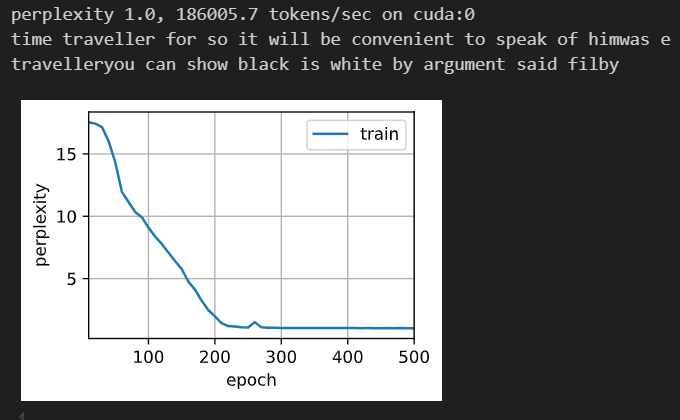
小结
- 在深度循环神经网络中,隐状态的信息被传递到当前层的下一时间步和下一层的当前时间步。
- 有许多不同风格的深度循环神经网络,如长短期记忆网络、门控循环单元、或经典循环神经网络。 这些模型在深度学习框架的高级API中都有涵盖。
- 总体而言,深度循环神经网络需要大量的调参(如学习率和修剪)来确保合适的收敛,模型的初始化也需要谨慎。
QA 思考
Q1:深层 RNN 是不是每层都需要一个初始 hidden state?
A1:是的,可以认为,每一层基本上都是带了一个初始状态和一个自己的 weight 。
练习
- 基于我们在 :numref:
sec_rnn_scratch中讨论的单层实现, 尝试从零开始实现两层循环神经网络。 - 在本节训练模型中,比较使用门控循环单元替换长短期记忆网络后模型的精确度和训练速度。
- 如果增加训练数据,能够将困惑度降到多低?
- 在为文本建模时,是否可以将不同作者的源数据合并?有何优劣呢?
解答(简洁)
1. 实现两层循环神经网络
基于我们在 :numref:sec_rnn_scratch 中讨论的单层实现,从零开始实现两层循环神经网络需要以下步骤:
- 定义一个类来表示RNN单元。
- 在该类中,初始化两个隐藏层的参数。
- 在前向传播过程中,首先将输入数据传递给第一层,得到输出后作为第二层的输入。
- 将第二层的输出用于计算损失和预测。
2. 使用门控循环单元替换长短期记忆网络后的效果比较
在本节训练模型中,使用门控循环单元(GRU)替换长短期记忆网络(LSTM)可能会导致以下结果:
- 准确性:通常情况下,LSTM由于其复杂的结构可以捕捉更长期依赖关系,因此可能比GRU稍微准确一些。但差异往往不大,具体取决于任务。
- 训练速度:GRU因为其相对简单的架构(少于LSTM),在训练速度上可能会更快。
3. 增加训练数据对困惑度的影响
增加训练数据理论上能够帮助降低模型的困惑度,因为它允许模型学习到更多的语言规则和模式。然而,困惑度的降低也受到其他因素的限制,比如模型容量、优化算法等。实际能降到多低取决于这些变量以及数据本身的性质。
4. 合并不同作者的数据进行文本建模
合并不同作者的数据进行文本建模有以下优劣:
- 优点
- 提高了模型的泛化能力,因为它暴露给了更多样化的写作风格和词汇。
- 可以帮助模型更好地理解语言的一般规律,而不是特定于某位作者的习惯。
- 缺点
- 如果目标是模仿某个特定作者的风格,那么引入其他作者的数据可能会"稀释"这种风格。
- 数据集内部的不一致性可能导致模型学习到混合的模式,从而影响特定任务上的表现。