Gradio全解20------Streaming:Streaming:流式传输的多媒体应用(1)------流式传输音频:魔力8号球
- 前言
- 本篇摘要
- [20. Streaming:流式传输的多媒体应用](#20. Streaming:流式传输的多媒体应用)
-
- [20.1 流式传输音频:魔力8号球](#20.1 流式传输音频:魔力8号球)
-
- [20.1.1 工作原理](#20.1.1 工作原理)
- [20.1.2 Inference API:在服务器上运行推理](#20.1.2 Inference API:在服务器上运行推理)
-
- [1. text_to_image:文生图任务](#1. text_to_image:文生图任务)
- [2. chat_completion:生成响应](#2. chat_completion:生成响应)
- [20.1.3 Spaces ZeroGPU:动态GPU分配方案](#20.1.3 Spaces ZeroGPU:动态GPU分配方案)
-
- [1. ZeroGPU Spaces使用与托管指南](#1. ZeroGPU Spaces使用与托管指南)
- [2. 其它技术性说明](#2. 其它技术性说明)
- [3. ZeroGPU快速入门](#3. ZeroGPU快速入门)
- [20.1.4 用户界面](#20.1.4 用户界面)
- [20.1.5 转录语音与生成回答](#20.1.5 转录语音与生成回答)
- [20.1.6 语音合成与流式传输](#20.1.6 语音合成与流式传输)
- 参考文献:
前言
本系列文章主要介绍WEB界面工具Gradio。Gradio是Hugging Face发布的简易WebUI开发框架,它基于FastAPI和svelte,可以使用机器学习模型、python函数或API开发多功能界面,并可部署人工智能模型,是当前热门的非常易于展示机器学习大语言模型LLM及扩散模型DM的WebUI框架。
本系列文章分为六部分:Gradio介绍、HuggingFace资源与工具库、Gradio基础功能实战、LangChain详解、Gradio与大模型融合实战及Agent代理实战、Gradio高级功能实战。第一部分Gradio介绍,方便读者对Gradio整体把握,包括三章内容:第一章先介绍Gradio的概念,包括详细技术架构、历史、应用场景、与其他框架Gradio/NiceGui/StreamLit/Dash/PyWebIO的区别,然后详细讲述Gradio的安装与运行,安装包括Linux/Win/Mac三类系统安装,运行包括普通方式和热重载方式;第二章介绍Gradio的4种部署方式,包括本地部署launch()、huggingface托管、FastAPI挂载和Gradio-Lite浏览器集成;第三章介绍Gradio的三种客户端(Client),包括python客户端、javascript客户端和curl客户端。第二部分讲述著名网站Hugging Face的各类资源和工具库,因为Gradio演示中经常用到Hugging Face的models,还有某些场景需要部署在Spaces,以及经常用到的transformers及datasets库,包括两章内容:第四章详解三类资源models/datasets/spaces的使用,第五章实战六类工具库transformers/diffusers/datasets/PEFT/accelerate/optimum实战。第三部分实战Gradio基础功能,进入本系列文章的核心,包括四章内容:第六章讲解Gradio库的模块架构和环境变量,第七章讲解Gradio高级抽象界面类Interface,第八章讲解Gradio底层区块类Blocks,第九章讲解补充特性Additional Features。第四部分讲述LangChain,包括四章内容:第十章讲述LangChain基础知识详述,内容有优势分析、学习资料、架构及LCEL,第十一章讲述LangChain组件Chat models,第十二章讲述组件Tools/Toolkits,第十三章讲述其它五类主要组件:Text splitters/Document loaders/Embedding models/Vector stores/Retrievers。第五部分是Gradio与大模型融合及Agent代理实战,包括四章内容:第十四章讲解融合大模型的多模态聊天机器人组件Chatbot,第十五章讲解使用transformers.agents构建Gradio,第十六章讲述使用LangChain Agents构建Gradio及Gradio Tools,第十七章讲述使用LangGraph构建Gradio。第六部分讲述Gradio其它高级功能,包括三章内容:第十八章讲述从Gradio App创建Discord Bot/Slack Bot/Website Widget,第十九章讲述数据科学与绘图Data Science And Plots,第二十章讲述流式传输Streaming。
本系列文章讲解细致,涵盖Gradio及相关框架的大部分组件和功能,代码均可运行并附有大量运行截图,方便读者理解并应用到开发中,Gradio一定会成为每个技术人员实现各种奇思妙想的最称手工具。
本系列文章目录如下:
- 《Gradio全解1------Gradio简介》
- 《Gradio全解1------Gradio的安装与运行》
- 《Gradio全解2------Gradio的3+1种部署方式实践》
- 《Gradio全解2------浏览器集成Gradio-Lite》
- 《Gradio全解3------Gradio Client:python客户端》
- 《Gradio全解3------Gradio Client:javascript客户端》
- 《Gradio全解3------Gradio Client:curl客户端》
- 《Gradio全解4------剖析Hugging Face:详解三类资源models/datasets/spaces》
- 《Gradio全解5------剖析Hugging Face:实战六类工具库transformers/diffusers/datasets/PEFT/accelerate/optimum》
- 《Gradio全解6------Gradio库的模块架构和环境变量》
- 《Gradio全解7------Interface:高级抽象界面类(上)》
- 《Gradio全解7------Interface:高级抽象界面类(下)》
- 《Gradio全解8------Blocks:底层区块类(上)》
- 《Gradio全解8------Blocks:底层区块类(下)》
- 《Gradio全解9------Additional Features:补充特性(上)》
- 《Gradio全解9------Additional Features:补充特性(下)》
- 《Gradio全解10------LangChain基础知识详述》
- 《Gradio全解11------LangChain组件Chat models详解》
- 《Gradio全解12------LangChain组件Tools/Toolkits详解》
- 《Gradio全解13------LangChain其它五类组件详解》
- 《Gradio全解14------Chatbot:融合大模型的多模态聊天机器人》
- 《Gradio全解15------使用transformers.agents构建Gradio》
- 《Gradio全解16------使用LangChain Agents构建Gradio及Gradio Tools》
- 《Gradio全解17------使用LangGraph构建Gradio》
- 《Gradio全解18------从Gradio App创建Discord Bot/Slack Bot/Website Widget》
- 《Gradio全解19------Data Science And Plots:数据科学与绘图》
- 《Gradio全解20------Streaming:流式传输的多媒体应用》
本章目录如下:
- 《Gradio全解20------Streaming:流式传输的多媒体应用(1)------流式传输人工智能生成的音频》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(2)------构建对话式聊天机器人》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(3)------实时语音识别技术》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(4)------基于Groq的带自动语音检测功能的多模态Gradio应用》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(5)------基于WebRTC的摄像头实时目标检测》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(6)------构建视频流目标检测系统》;
本篇摘要
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。
20. Streaming:流式传输的多媒体应用
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。音频应用包括流式传输音频、构建音频对话式聊天机器人、实时语音识别技术和自动语音检测功能;图像应用包括基于WebRTC的摄像头实时目标检测;视频应用包括构建视频流目标检测系统。
20.1 流式传输音频:魔力8号球
在本指南中,我们将构建一个新颖的AI应用:会说话的魔力8号球🎱(Magic 8 Ball),以展示Gradio的音频流式输出功能。Magic 8 Ball是一种玩具,在你摇晃它后,它会回答任何问题,而我们的应用不仅能给出回答,还会用语音播报答案!这篇博客不会涵盖所有实现细节,但代码已在Hugging Face Spaces上开源:gradio/magic-8-ball。
20.1.1 工作原理
本例会说话的魔力8号球的工作原理:和经典的Magic 8 Ball一样,用户需要口头提问,然后等待回应。在后台,我们将使用Whisper进行语音转录,再通过大语言模型(LLM)生成Magic 8 Ball风格的答案,最后用Parler TTS将回答朗读出来。
在讲述逻辑实现之前,需要先学习一下要用到的知识点:Inference API和ZeroGPU,已掌握这两个知识点的读者可直接跳过。
20.1.2 Inference API:在服务器上运行推理
推理是使用训练好的模型对新数据进行预测的过程,由于该过程可能计算密集,在专用或外部服务上运行是一个值得考虑的选择,关于Hugging Face 的推理请参阅: Run Inference on servers。huggingface_hub库提供了统一接口,可对托管在Hugging Face Hub上的模型使用多种服务来运行推理,比如:
- HF Inference API:一种无服务器解决方案,可以免费在Hugging Face的基础设施上运行模型推理。该服务是快速入门、测试不同模型和原型化AI产品的便捷途径;
- 第三方供应商:由外部供应商provider(如Together、Sambanova等)提供的各类无服务器解决方案。这些供应商按用量付费模式(pay-as-you-go)提供生产就绪的API,这是以免维护、可扩展的解决方案将AI集成至产品中的最快方式。在支持的供应商和任务章节列出了具体供应商信息: Supported providers and tasks;
- 推理终端节点:一个可将模型轻松部署至生产环境的产品,推理由Hugging Face在用户选择的云供应商提供的专用全托管基础设施上运行。
这些服务均可通过InferenceClient对象调用,该对象替代了旧版InferenceApi客户端,新增了对特定任务和第三方供应商的支持,从旧版客户端迁移至新客户端的方法请参阅Legacy InferenceAPI client。
InferenceClient是一个通过HTTP调用与官方API交互的Python客户端。如果用户希望直接使用常用工具(如curl、Postman等)发起HTTP请求,请参阅Inference API或Inference Endpoints文档页面。对于网页开发,官方已发布JS Client。如果用户从事游戏开发,可以关注官方的 C# project。
1. text_to_image:文生图任务
让我们从一个文生图任务开始入门:
python
from huggingface_hub import InferenceClient
# Example with an external provider (e.g. replicate)
replicate_client = InferenceClient(
provider="replicate",
api_key="my_replicate_api_key",
)
replicate_image = replicate_client.text_to_image(
"A flying car crossing a futuristic cityscape.",
model="black-forest-labs/FLUX.1-schnell",
)
replicate_image.save("flying_car.png")在上述示例中,我们使用第三方服务提供商Replicate初始化了一个 InferenceClient。当使用第三方提供商时,必须指定要使用的模型,该模型ID 必须是Hugging Face Hub上的模型标识符,而非第三方提供商自身的模型ID。在本例中,我们通过文本提示生成了一张图像,返回值为PIL.Image对象,可保存为文件,更多细节请参阅文档:text_to_image()。
2. chat_completion:生成响应
接下来让我们看一个使用chat_completion() API的示例,该任务利用大语言模型根据消息列表生成响应:
python
from huggingface_hub import InferenceClient
messages = [
{
"role": "user",
"content": "What is the capital of France?",
}
]
client = InferenceClient(
provider="together",
model="meta-llama/Meta-Llama-3-8B-Instruct",
api_key="my_together_api_key",
)
client.chat_completion(messages, max_tokens=100)输出为:
bash
ChatCompletionOutput(
choices=[
ChatCompletionOutputComplete(
finish_reason="eos_token",
index=0,
message=ChatCompletionOutputMessage(
role="assistant", content="The capital of France is Paris.", name=None, tool_calls=None
),
logprobs=None,
)
],
created=1719907176,
id="",
model="meta-llama/Meta-Llama-3-8B-Instruct",
object="text_completion",
system_fingerprint="2.0.4-sha-f426a33",
usage=ChatCompletionOutputUsage(completion_tokens=8, prompt_tokens=17, total_tokens=25),
)在上述示例中,我们创建客户端时使用了第三方服务提供商(Together AI)并指定了所需模型("meta-llama/Meta-Llama-3-8B-Instruct")。随后我们提供了待补全的消息列表(此处为单个问题),并向API传递了额外参数(max_token=100)。
输出结果为遵循OpenAI规范的ChatCompletionOutput对象,生成内容可通过output.choices0.message.content获取。更多细节请参阅chat_completion()文档。该API设计简洁,但并非所有参数和选项都会向终端用户开放或说明,如需了解各任务支持的全部参数,请查阅Inference Providers - API Reference。
20.1.3 Spaces ZeroGPU:动态GPU分配方案
ZeroGPU是Hugging Face Spaces平台上专为AI模型和演示优化的GPU共用基础设施,采用动态分配机制实现NVIDIA A100显卡的按需调用与释放,其主要特性包括:
- 免费GPU资源:为Spaces用户提供零成本GPU算力支持;
- 多GPU并发:支持Spaces上的单个应用同时调用多块显卡进行运算。
与传统单GPU分配模式相比,ZeroGPU的高效系统通过资源利用率最大化和能效比最优化,有效降低了开发者、研究机构及企业部署AI模型的技术门槛。更多信息请参阅:Spaces ZeroGPU: Dynamic GPU Allocation for Spaces。
1. ZeroGPU Spaces使用与托管指南
使用ZeroGPU,就要用到ZeroGPU Spaces。对于使用现有ZeroGPU Spaces:
- 所有用户均可免费使用(可查看精选Space列表:ZeroGPU Spaces);
- PRO用户在使用任何ZeroGPU Spaces时,享有5倍的每日使用配额和GPU队列的最高优先级。
用户也可托管自有ZeroGPU Spaces,但个人和企业需订阅不同版本:
- 个人账户:需订阅PRO版,在新建Gradio SDK Space时可选择ZeroGPU硬件配置,最多创建10个ZeroGPU Space;
- 企业用户:需订阅Enterprise Hub,即可为全体成员启用ZeroGPU Spaces功能,最多创建50个ZeroGPU Space。
2. 其它技术性说明
技术规格:
- GPU类型:NVIDIA A100;
- 可用显存:每个工作负载为40GB
兼容性说明:ZeroGPU Spaces设计为兼容大多数基于PyTorch的GPU Spaces,虽然对Hugging Face高级库(如transformers和diffusers)的兼容性更优,但用户需注意以下事项:
- 目前ZeroGPU Spaces仅兼容Gradio SDK;
- 与标准GPU Spaces相比,ZeroGPU Spaces的兼容性可能受限;
- 某些场景下可能出现意外问题。
支持版本:
- Gradio:4+;
- PyTorch:2.0.1、2.1.2、2.2.2、2.4.0(注:由于PyTorch漏洞,不支持2.3.x版本);
- Python:3.10.13
3. ZeroGPU快速入门
用户的Space中使用ZeroGPU需遵循以下步骤:
- 确保在Space设置中已选择ZeroGPU硬件;
- 导入spaces模块;
- 使用@spaces.GPU装饰器标记依赖GPU的函数。
此装饰机制使得Space能在函数调用时申请GPU资源,并在执行完成后自动释放。示例如下:
python
import spaces
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(...)
pipe.to('cuda')
@spaces.GPU
def generate(prompt):
return pipe(prompt).images
gr.Interface(
fn=generate,
inputs=gr.Text(),
outputs=gr.Gallery(),
).launch()注:@spaces.GPU装饰器在非ZeroGPU环境中将不产生任何作用,以确保不同配置下的兼容性。另外,@spaces.GPU装饰器还可设置时长管理。若函数预计超过默认的60秒GPU运行时长,可指定自定义时长:
python
@spaces.GPU(duration=120)
def generate(prompt):
return pipe(prompt).images该设置将函数最大运行时限定为120秒,但为快速执行的函数指定更短时长,可提升Space访客的队列优先级。
通过ZeroGPU,开发者能创建更高效、可扩展的Space,在最大化GPU利用率的同时实现成本优化。
20.1.4 用户界面
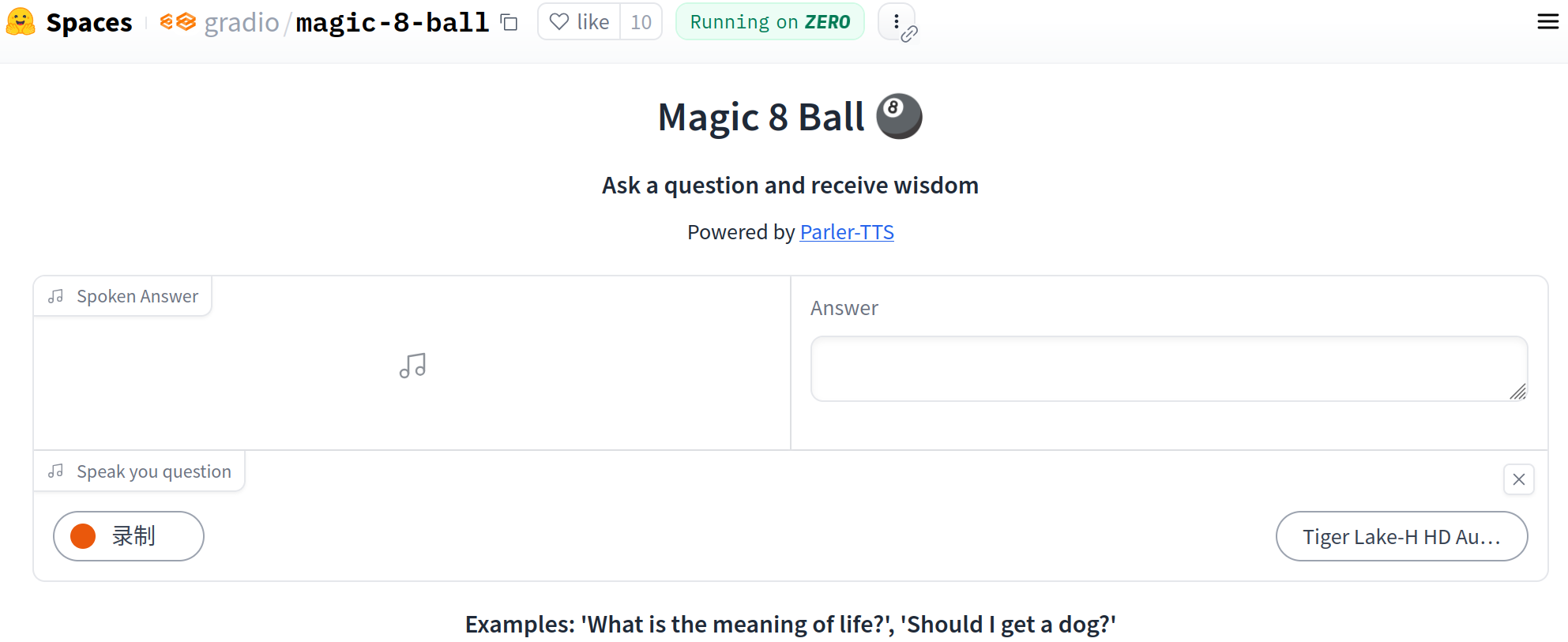
首先,我们定义UI界面,并为所有Python逻辑预留占位符。
python
import gradio as gr
with gr.Blocks() as block:
gr.HTML(
f"""
<h1 style='text-align: center;'> Magic 8 Ball 🎱 </h1>
<h3 style='text-align: center;'> Ask a question and receive wisdom </h3>
<p style='text-align: center;'> Powered by <a href="https://github.com/huggingface/parler-tts"> Parler-TTS</a>
"""
)
with gr.Group():
with gr.Row():
audio_out = gr.Audio(label="Spoken Answer", streaming=True, autoplay=True)
answer = gr.Textbox(label="Answer")
state = gr.State()
with gr.Row():
audio_in = gr.Audio(label="Speak your question", sources="microphone", type="filepath")
audio_in.stop_recording(generate_response, audio_in, [state, answer, audio_out])\
.then(fn=read_response, inputs=state, outputs=[answer, audio_out])
block.launch()我们将音频输出组件、文本框组件和音频输入组件分别放置在不同行中。为了实现服务器端的音频流式传输,我们会在输出音频组件中设置streaming=True。同时,我们还会启用autoplay=True,以便音频在准备就绪时自动播放。此外,我们将利用音频输入组件的stop_recording事件,在用户停止麦克风录音时触发应用逻辑。
我们将逻辑分为两部分:
- generate_response:负责接收录音音频,进行语音转录,并通过大语言模型生成回答。生成的回答会存储在gr.State变量中,并传递给下一步的read_response函数。
- read_response:负责将文本回答转换为语音音频。
这样拆分的原因是,由于生成回答的部分可以通过Hugging Face的Inference API完成,无需占用GPU配额,因此我们避免将这部分逻辑放在GPU函数中,以节省资源。而只有read_response需要GPU资源,它将运行在Hugging Face的ZeroGPU上,该服务有基于时长的配额限制,因此去掉generate_response可以降低费用。
20.1.5 转录语音与生成回答
如上所述,我们将使用Hugging Face的Inference API来转录音频,并通过LLM 生成回答。逻辑实现时,首先实例化客户端,调用automatic_speech_recognition方法来转录音频,该方法会自动使用 Hugging Face推理服务器上的Whisper模型。接着将问题输入LLM模型Mistral-7B-Instruct生成回答,我们通过系统格式消息(system message)让LLM模拟Magic 8 Ball的风格进行回复。
generate_response函数还会向输出文本框和音频组件发送空更新(即返回 None)。这样做的目的是:显示 Gradio 的进度指示器(progress tracker),让用户感知处理状态;延迟显示答案,直到音频生成完成,确保文字和语音同步呈现。代码如下:
python
from huggingface_hub import InferenceClient
client = InferenceClient(token=os.getenv("HF_TOKEN"))
def generate_response(audio):
gr.Info("Transcribing Audio", duration=5)
question = client.automatic_speech_recognition(audio).text
messages = [{"role": "system", "content": ("You are a magic 8 ball."
"Someone will present to you a situation or question and your job "
"is to answer with a cryptic adage or proverb such as "
"'curiosity killed the cat' or 'The early bird gets the worm'."
"Keep your answers short and do not include the phrase 'Magic 8 Ball' in your response. If the question does not make sense or is off-topic, say 'Foolish questions get foolish answers.'"
"For example, 'Magic 8 Ball, should I get a dog?', 'A dog is ready for you but are you ready for the dog?'")},
{"role": "user", "content": f"Magic 8 Ball please answer this question - {question}"}]
response = client.chat_completion(messages, max_tokens=64, seed=random.randint(1, 5000),
model="mistralai/Mistral-7B-Instruct-v0.3")
response = response.choices[0].message.content.replace("Magic 8 Ball", "").replace(":", "")
return response, None, None20.1.6 语音合成与流式传输
现在我们有了文本响应,我们将使用Parler TTS将其朗读出来。read_response 函数是一个Python生成器,生成器将在音频准备好时逐块产生下一段音频。函数中,我们将使用Mini v0.1进行特征提取,但使用Jenny微调版本进行语音生成,以确保语音在多次生成中保持一致。
Parler-TTS Mini v0.1是一个轻量级文本转语音(TTS)模型,它经过10.5千小时的音频数据训练,可以生成高质量、自然的声音,并通过简单的文本提示控制声音特征(例如性别、背景噪音、语速、音调和混响等),它是Parler-TTS项目的首个发布模型,该项目旨在为社区提供TTS训练资源和数据集预处理代码。Jenny微调版本是Parler-TTS Mini v0.1的微调版本,基于Jenny(爱尔兰口音)30小时单人高品质数据集进行训练,适合用于训练TTS模型。使用方法与 Parler-TTS v0.1大致相同,只需在语音描述中指定关键字"Jenny"即可。
使用Transformers进行流式音频传输需要一个自定义的Streamer类,可以在这里查看实现细节:magic-8-ball/streamer.py。此外,我们会将输出转换为字节流,以便从后端更快地流式传输。
python
from streamer import ParlerTTSStreamer
from transformers import AutoTokenizer, AutoFeatureExtractor, set_seed
import numpy as np
import spaces
import torch
from threading import Thread
device = "cuda:0" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
torch_dtype = torch.float16 if device != "cpu" else torch.float32
repo_id = "parler-tts/parler_tts_mini_v0.1"
jenny_repo_id = "ylacombe/parler-tts-mini-jenny-30H"
model = ParlerTTSForConditionalGeneration.from_pretrained(
jenny_repo_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
).to(device)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)
sampling_rate = model.audio_encoder.config.sampling_rate
frame_rate = model.audio_encoder.config.frame_rate
@spaces.GPU
def read_response(answer):
play_steps_in_s = 2.0
play_steps = int(frame_rate * play_steps_in_s)
description = "Jenny speaks at an average pace with a calm delivery in a very confined sounding environment with clear audio quality."
description_tokens = tokenizer(description, return_tensors="pt").to(device)
streamer = ParlerTTSStreamer(model, device=device, play_steps=play_steps)
prompt = tokenizer(answer, return_tensors="pt").to(device)
generation_kwargs = dict(
input_ids=description_tokens.input_ids,
prompt_input_ids=prompt.input_ids,
streamer=streamer,
do_sample=True,
temperature=1.0,
min_new_tokens=10,
)
set_seed(42)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for new_audio in streamer:
print(f"Sample of length: {round(new_audio.shape[0] / sampling_rate, 2)} seconds")
yield answer, numpy_to_mp3(new_audio, sampling_rate=sampling_rate)运行界面如下: