目录
[1. CPU:逻辑控制的"总司令官"及其并行局限性](#1. CPU:逻辑控制的“总司令官”及其并行局限性)
[2. GPU:通过"人海战术"实现大规模并行计算](#2. GPU:通过“人海战术”实现大规模并行计算)
[3. TPU:针对深度学习的专用芯片(ASIC)](#3. TPU:针对深度学习的专用芯片(ASIC))
现在这年代,技术日新月异,物联网、人工智能、深度学习等概念遍地开花,各类芯片名词 GPU, TPU, NPU, DPU 层出不穷。要理解这些专业芯片,首先需要理解传统的核心------中央处理器(CPU)及其架构。
1. CPU:逻辑控制的"总司令官"及其并行局限性
CPU (Central Processing Unit, 中央处理器) 是机器的"大脑",负责布局谋略、发号施令、控制行动的"总司令官"。
1.1 架构与执行模式
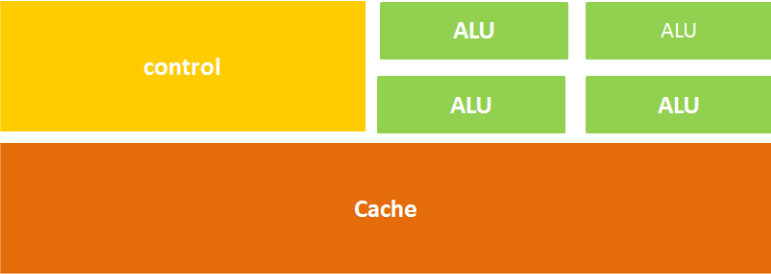
CPU 的结构主要包括运算器(ALU)、控制单元(CU)、寄存器、高速缓存器(Cache)。
计算单元(ALU):执行算术运算、移位等操作。
控制单元(CU):对指令译码,发出操作控制信号。
存储单元(Cache/Register):保存运算数据和指令。
CPU 遵循冯诺依曼架构,其核心理念是:存储程序,顺序执行。这意味着它像一个一板一眼的管家,总是一步一步地顺序完成任务。
1.2 并行计算的局限
由于 CPU 的架构中,负责计算的运算器(ALU)只占据了很小一部分空间,而大量的空间用于放置缓存和控制单元。这种结构决定了性质:CPU 更擅长于逻辑控制和不同数据类型的复杂运算,但在大规模并行计算能力上极受限制。随着对更快处理速度的需求增加,CPU 的顺序执行模式逐渐变得力不从心。
2. GPU:通过"人海战术"实现大规模并行计算
为了突破 CPU 在并行计算上的瓶限,GPU(Graphics Processing Unit,图形处理器)应运而生。
2.1 并行计算的概念
并行计算是指同时使用多种计算资源解决计算问题的过程。它通过将问题分解成若干部分,由多个处理器并行计算,是提高计算速度的有效手段。
时间并行(流水线技术):同一时间启动多个操作,如工厂流水线。
空间并行(多处理器并发):多个处理机并发执行计算,将一个大任务分割成多个相同的子任务。GPU 采用的正是这种空间并行的策略。
2.2 GPU 的架构优势与通用化
GPU 之所以擅长处理图像数据(每个像素点的处理过程相似),正是因为它在架构上进行了优化:它拥有数量众多的简单计算单元 (ALU) 和超长的流水线,非常适合处理大量的类型统一的数据,这是一种典型的"人海战术"。
与 CPU 相比,GPU 的缓存很少,且主要用于为线程服务。GPU 无法单独工作,必须由 CPU 控制调用。虽然 GPU 是为图像处理而生,但其结构优化使其能够被应用于科学计算、金融分析、海量数据处理等需要大规模并行计算的领域,因此 GPU 也可以被视为一种较通用的芯片。

3. TPU:针对深度学习的专用芯片(ASIC)
虽然 CPU 和 GPU 都是通用芯片,但"万能工具的效率永远比不上专用工具"。为实现更高的处理速度和更低的能耗,ASIC(专用集成电路)概念应运而生。
TPU(Tensor Processing Unit, 张量处理器)就是谷歌专门为加速深层神经网络运算能力而研发的一款 ASIC。谷歌庞大的业务体量(图像搜索、谷歌翻译等)对深度学习芯片产生了规模化需求,使得开发专用芯片具备了商业可行性。
性能飞跃:据称,TPU 与同期的 CPU 和 GPU 相比,可以提供 15-30 倍的性能提升,以及 30-80 倍的效率(性能/瓦特)提升。
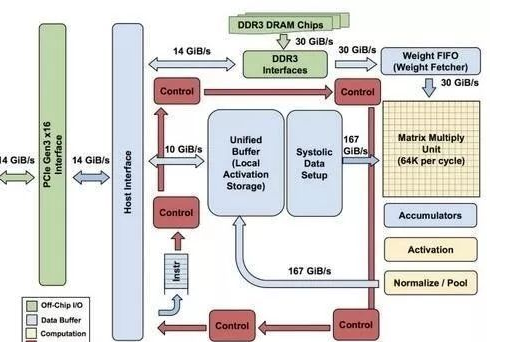
架构优化:TPU 性能强大的关键在于:
巨大片上内存:在芯片上使用了高达 24MB 的局部内存,有效减少了片外内存访问(GPU 能效比低的罪魁祸首)。
低精度运算:采用了 8 比特的低精度运算,带来了更低的功耗、更快的速度和更小的芯片面积需求。
从初代的仅支持推理,到第二代支持训练和推理,TPU 已在 Google 的 RankBrain(搜索结果处理)、街景 Street View,以及著名的 AlphaGo 等人工智能系统中发挥了核心作用。