前言
本案例希望建立一个UNET网络模型,来实现对农业遥感图像语义分割的任务。本篇博客主要包括对上一篇博客中的相关遗留问题进行解决,并对网络结构进行优化调整以适应个人的硬件设施------NVIDIA GeForce RTX 3050。
本案例的前两篇博客直达链接基于UNet算法的农业遥感图像语义分割(下)和基于UNet算法的农业遥感图像语义分割(上)
1.模型简化
1.1 二分类语义分割效果解答
上一篇博客最终的预测结果为二分类的语义分割,即经过彩色映射后,结果只有黑和蓝两种颜色。原因是因为模型虽然参数更新了1400多次,但其实从遍历数据集的角度考虑也就65个epoch.
同时网络模型参数量约7.7M,模型并未充分学习到训练集上的信息。之所以会出现二分类的预测结果,是与模型初始化权重有关。
1.2网络模型调整
因此针对上述情况,我将模型改成了单层的编码器-解码器架构,同时将Block模块中做进一步特征融合的卷积层移除,具体结构如下所示:
python
class Block(nn.Module):
def __init__(self, in_channels, out_channels):
super(Block, self).__init__()
self.relu = nn.ReLU(inplace=False)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
# self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
# x = self.conv2(x)
# x = self.relu(x)
return x
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU(inplace=False)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 编码器部分
self.conv1 = Block(3, 32)
# 解码器部分
self.up2 = nn.ConvTranspose2d(32, 32, kernel_size=2, stride=2)
self.conv2 = Block(32, 32)
self.conv3 = nn.Conv2d(32, 4, kernel_size=1)
def forward(self, x):
# 编码器
conv1 = self.conv1(x) # 32, 512, 512
pool1 = self.pool(conv1) # 32, 256, 256
# 解码器
up2 = self.up2(pool1) # 32, 512, 512
conv2 = self.conv2(up2) # 32, 512, 512
conv3 = self.conv3(conv2) # 4, 512, 512
return conv3此时查看模型的信息如下所示:
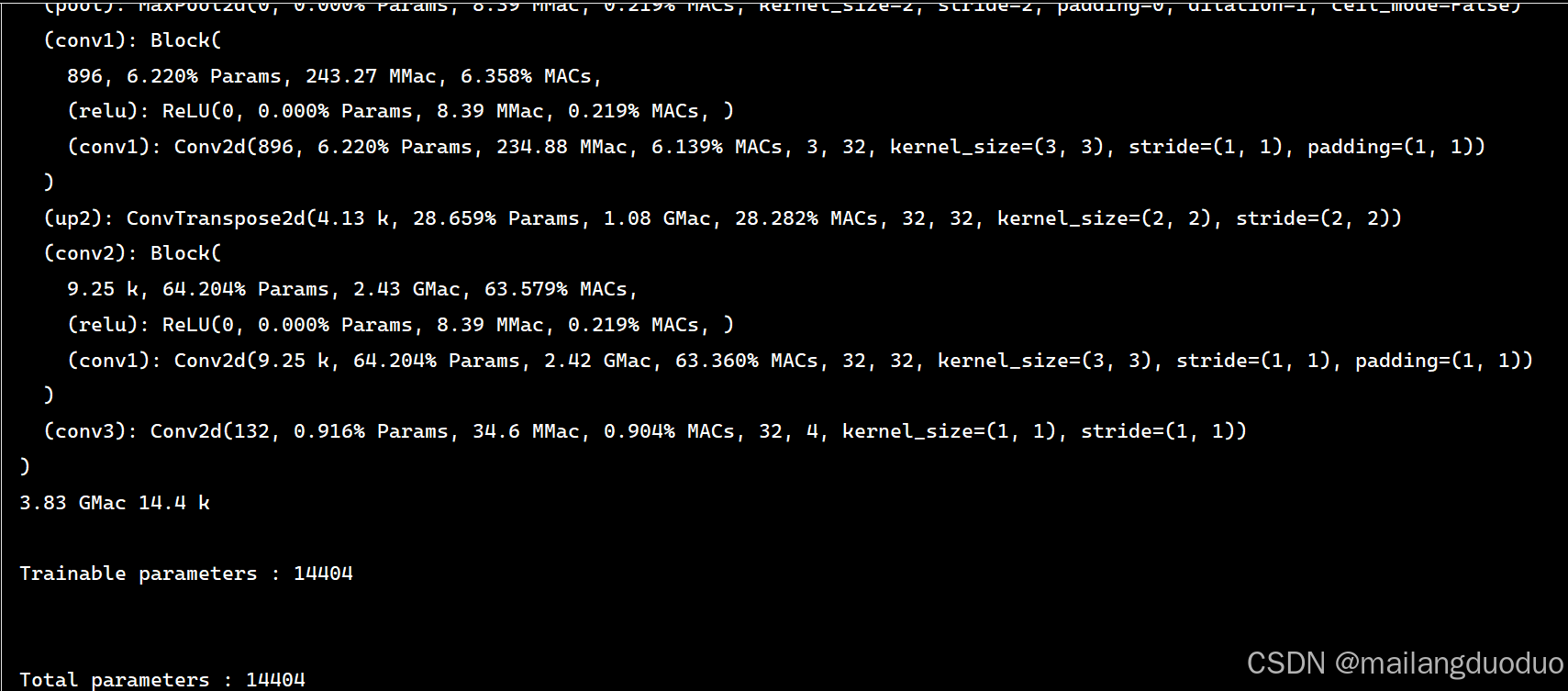
模型的参数量已经减少至14.4k,可以预见结果并不会很好。因为输入的图像尺寸就已经512×512×3,相比而言,该模型显然不能充分拟合该任务。
2.训练策略调整
2.1训练损失波动解答
因为统计的损失是按照每个iter进行统计的,每次的迭代过程在该批次下的参数更新朝着当前批次损失变小的方向进行,但对其他批次可能损失会升高,因此损失波动剧烈,但整体呈下降趋势。
这里的解决方案如下:
- 将参数更新过程中记录的iter次数进行减少,如
将iter%10==0调整成iter%200==0 - 将参数更新过程中的记录的结果转换成累积量,即将10个iter中损失进行累加或者将一个epoch中的所有损失进行累加(本案例后续改进采用该方式)。
- 将参数更新过程中的记录的结果转换成平均量,即将10个iter中损失进行平均或者将一个epoch中的所有损失进行平均。
2.2训练过程调整
因为本案例的数据集本身就很小,所以这里采用的是将一个epoch中的所有损失进行累加统计进行输出可视化。同时为了避免模型参数保存冗余问题,将模型保存策略进行调整,只保存在验证集上损失最小的模型,同时使用覆盖原则将之前的保存模型进行覆盖,以节省空间开销,具体代码调整如下:
python
# 创建一个 SummaryWriter 对象,用于将数据写入 TensorBoard
writer = SummaryWriter("dataset/logs")
epoch = 0
best_val_loss = float('inf')
# best_val_loss = 7.899
# model.load_state_dict(torch.load('./models/secweights_40.pth'))
while epoch < 500:
epoch += 1
print("---------第{}轮训练开始---------".format(epoch))
train_loss = 0
for i, (img, label) in tqdm(enumerate(dataloader_train)):
img = img.to(device).float()
label = label.long().to(device)
model.train()
output = model(img)
# output = torch.argmax(output, dim=1).double()
# iter_num += 1
loss = getLoss(output, label)
train_loss += loss.item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
# print("---------第{}轮训练结束---------".format(epoch))
print("第{}轮训练的损失为:{}".format(epoch, train_loss))
writer.add_scalar('Training Loss3', train_loss, epoch)
if epoch % 10 == 0:
# torch.save(model.state_dict(), './models/thirdweights_{}.pth'.format(epoch))
val_loss = 0
with torch.no_grad():
model.eval()
for i, (img, label) in tqdm(enumerate(dataloader_val)):
img = img.to(device).float()
label = label.long().to(device)
output = model(img)
loss = getLoss(output, label)
val_loss += loss.item()
print("第{}轮验证的损失为:{}".format(epoch, val_loss))
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), './models/best_model2.pth')
print("Saved new best model")
writer.add_scalar('Validation Loss3', val_loss, epoch)
writer.close()3.结果分析
3.1训练过程损失
在训练过程中的损失记录如下:
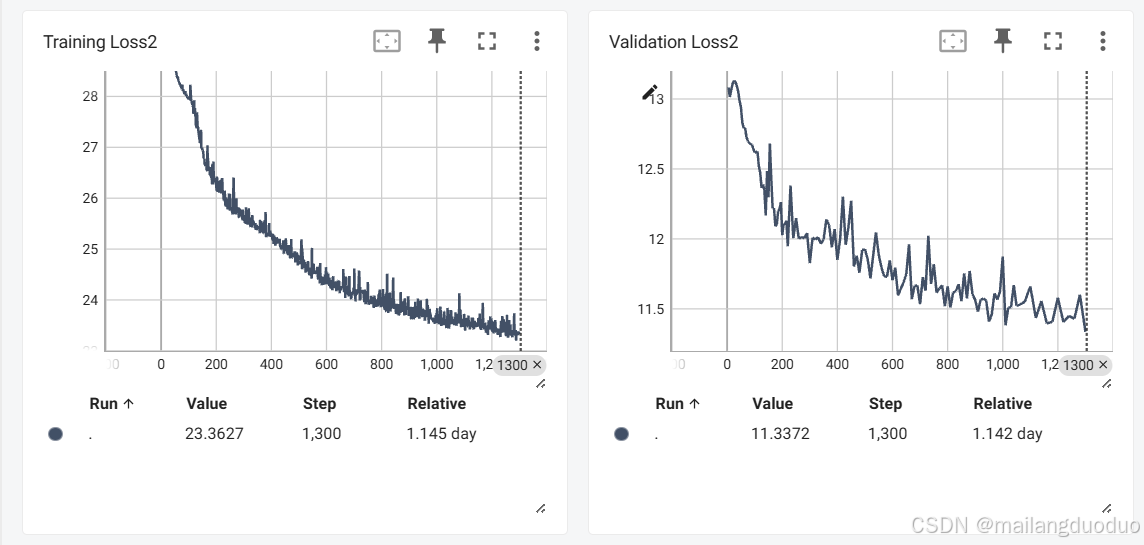
通过结果可以看出上述修改方式确实取得了不错的效果,模型训练集的抖动已大幅度减小。
从曲线角度考虑,训练集损失已经趋向于平稳,同时验证集上损失也趋向于平稳,由此判断模型已经基本收敛,但训练集的损失仍停留在较高水平,大概率是因为模型过于简单,难以拟合该任务的需求。
3.2模型预测结果
这里将模型最终保存的结果加载进来,对未知图片进行预测,代码如下:
python
import matplotlib.pyplot as plt
import torch
import cv2
import numpy as np
from torch.utils.tensorboard import SummaryWriter
from Net2 import Net
# I=cv2.imread('dataset/0.9/image/16213.png')#dataset/test.png
I=cv2.imread('dataset/test.png')
I=np.transpose(I, (2, 0, 1))
I=I/255.0
I=I.reshape(1,3,512,512)
I=torch.tensor(I)
model=Net().double()
model.load_state_dict(torch.load('models/best_model2.pth'))
output=model(I)
# print(output.shape)
# print(output[0,:,:5,:5])
predicted_classes = torch.argmax(output, dim=1).squeeze(0).numpy()
color_map = {
0: [0, 0, 0], # 黑色
1: [255, 0, 0], # 红色
2: [0, 255, 0], # 绿色
3: [0, 0, 255] # 蓝色
}
height, width = predicted_classes.shape
colored_image = np.zeros((height, width, 3), dtype=np.uint8)
for i in range(height):
for j in range(width):
class_id = predicted_classes[i, j]
colored_image[i, j] = color_map[class_id]
plt.imshow(colored_image)
plt.axis('off')
plt.show()
print(colored_image.shape)
colored_image=np.transpose(colored_image, (2, 0, 1))
writer=SummaryWriter('dataset/logs')
writer.add_image('test3',colored_image)
writer.close()预测结果如下:
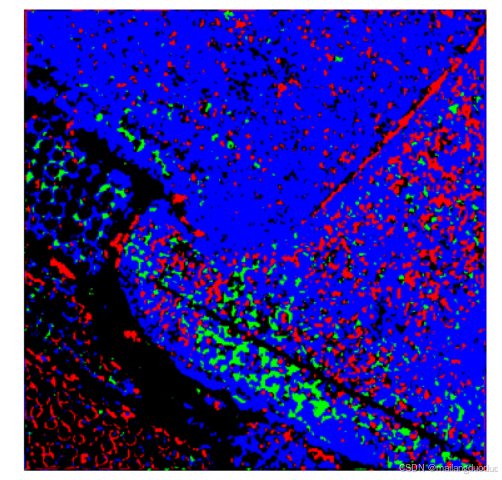
从结果角度考虑,确实实现了四分类的语义分割效果,但预测的效果并不是很好,因此需要进一步修改网络结构。
4.网络模型优化
具体修改主要包括引入批量规范化BatchNormalization的处理和增加了Dropout的机制以及对网络结构调整为三层的编码器-解码器架构。
4.1 BatchNormalization
批量规范化的核心思想是对每一层的输入进行归一化处理,使得每一层的输入分布在训练过程中保持相对稳定。具体来说,它将输入数据的每个特征维度都归一化到均值为 0、方差为 1 的标准正态分布。这样可以减少内部协变量偏移的影响,加快训练速度。
这里还有其他的逐层归一化方式,这里不做详细介绍。因为BatchNormalization聚焦于小批量层面,更适用于该任务,或者说更适用视觉图像处理方面

图片来源:本校《深度学习》课程的PPT
4.2 Dropout的机制
Dropout的机制能有效防止过拟合,在训练神经网络时,它通过以一定的概率随机将神经元的输出设置为0,即暂时"丢弃"这些神经元及其连接,每次迭代训练时在训练一个不同的子网络,通过多个子网络的综合效果来提高模型的泛化能力。类似于基学习器和集成学习的思想。
4.3网络模型代码
上述的两种方式是针对Block模块的,这里为了更好的拟合语义分割的任务,需要进一步加深网络结构,考虑到硬件资源有限,于是使用的是三层编码器-解码器架构,修改后的网络模型完整代码如下:
python
class Block(nn.Module):
def __init__(self, in_channels, out_channels, dropout_rate=0.1):
super(Block, self).__init__()
self.relu = nn.ReLU(inplace=False)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.dropout1 = nn.Dropout2d(p=dropout_rate)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.dropout2 = nn.Dropout2d(p=dropout_rate)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.dropout1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.dropout2(x)
return x
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.relu = nn.ReLU(inplace=False)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 编码器部分
self.conv1 = Block(3, 32)
self.conv2 = Block(32, 64)
self.conv3 = Block(64, 128)
# 解码器部分
self.up4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.conv4 = Block(128, 64)
self.up5 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)
self.conv5 = Block(64, 32)
self.conv6 = nn.Conv2d(32, 4, kernel_size=1)
def forward(self, x):
# 编码器
conv1 = self.conv1(x) # 32, 512, 512
pool1 = self.pool(conv1) # 32, 256, 256
conv2 = self.conv2(pool1) # 64, 256, 256
pool2 = self.pool(conv2) # 64, 128, 128
conv3 = self.conv3(pool2) # 128, 128, 128
# 解码器
up4 = self.up4(conv3) # 64, 256, 256
conv4 = torch.cat([up4, conv2], dim=1) # 128, 256, 256
conv4 = self.conv4(conv4) # 64, 256, 256
up5 = self.up5(conv4) # 32, 512, 512
conv5 = torch.cat([up5, conv1], dim=1) # 64, 512, 512
conv5 = self.conv5(conv5) # 32, 512, 512
conv6 = self.conv6(conv5) # 4, 512, 512
return conv65.改进模型结果分析
训练策略和之前保持不变,这里就不重复解释,只对结果进行说明。
5.1训练过程损失
训练过程损失记录如下:
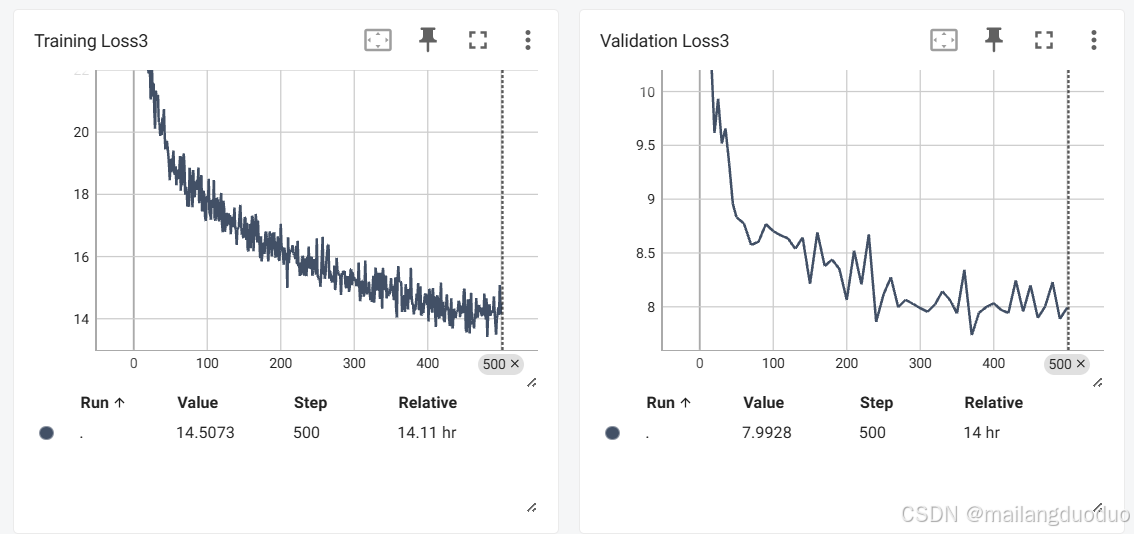
通过结果看到,训练集和验证集损失也基本趋于平稳,因此判断模型基本收敛。
5.2模型预测结果
将之前训练好的模型参数加载进来,对未知图片进行预测,结果如下:
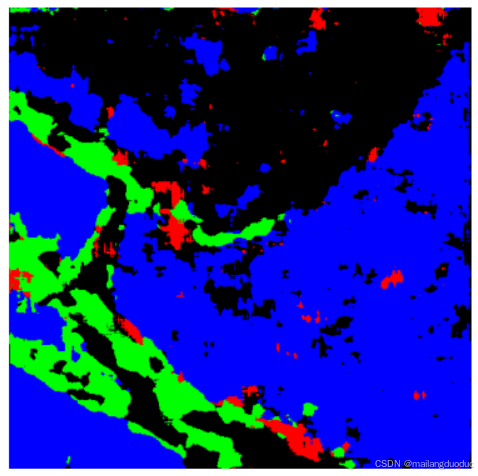
通过结果可以看出,预测结果相对于之前有了很大的改善,基本实现了语义分割的效果,只是在微小内容上,识别的并不准确。可能是因为模型还是不够复杂,不足以拟合该任务。
6.结语
至此,基于UNET算法的农业遥感图像语义分割任务到此结束,期望能够对你有所帮助。同时该项目也是我接触的第一个语义分割项目,解释的如有不足还请批评指出!!!