不要阻挡我走向成功,勇者配享所有,感想敢干
hotkey热key
大量请求可能会使redis节点流量不均匀,进而导致宕机,继而打到数据库崩溃;因此需要对热key优化
引发问题:
- 分片服务瘫痪
- 可能打到数据库,造成数据库瘫痪
- 单分片CPU高
如何发现热key?
-
使用自带的--hotkeys查找,需配置LFU淘汰策略。缺点全局扫描,实时性差
-
业务代码记录key访问次数上报聚合:缺点侵入性强
-
TCP抓包:解析RESP流量,统计key访问频率
-
京东hotkey
Redis-rdb-tools:分析RDB文件中的 大key和热key
-
云服务可视化工具
如何解决hotkey?
-
二级缓存本地缓存:如Caffeine等,清理时可用redis的pub/sub(不可靠);可用MQ的广播模式
-
- 本地缓存->redis->DB
-
数据分片:key分散到多个服务器:比如可以求shard=对key的hash值,newkey=key+"_"+shard分配到多个节点中
-
读写分离,读从从节点上请求
-
限流降级
bigkey大key
产生的场景
- 数据结构使用不当
- 未及时清理垃圾数据,没过期时间
- 对业务预估不准确
不同的场景对于大key的判定规则是不一样的啊
都有哪些危害呢?
危害
内存不均匀:单value较大时,可能会导致节点之间的内存使用不均匀,间接地影响key的部分和负载不均匀;
阻塞请求:redis为单线程,单value较大读写需要较长的处理时间,会阻塞后续的请求处理;
阻塞网络:单value较大时会占用服务器网卡较多带宽,可能会影响该服务器上的其他Redis实例或者应用
影响主从同步
影响扩容
影响AOF重写
总之就是它很不好就是了
如何发现呢?
- Redis4.0提供了--bigkeys,--hotkeys命令;生产慎用
- 可借助redis可视化工具another redis desktop manager查看
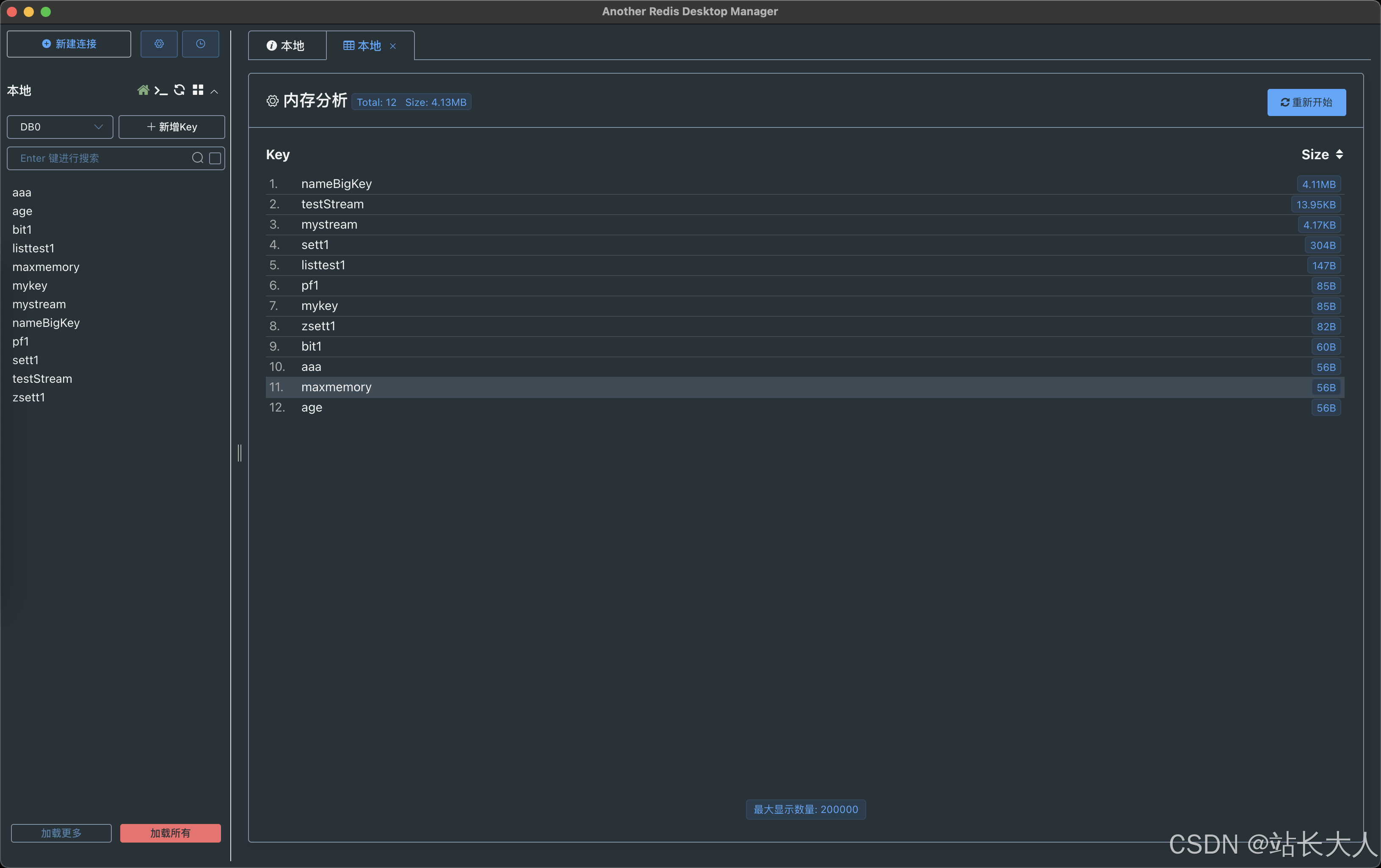
- RDB文件分析
- bigkey巡检
- 也可用:https://github.com/sripathikrishnan/redis-rdb-tools
- 可以定时任务在吞吐量低峰时reditemplate查询size并保存(生产可用)
如何解决?
- 评估业务是否必要,不必要就优化掉,已有的大key删除,这种最简单
- 对大key进行拆分,大list就拆分成小list
- 对大key进行清理,用UNLINK非阻塞
- 定期清理失效数据
- 压缩value
bigkey存在可能会导致扩容失败,严重会触发master-slave的故障切换
水平扩容都可能遇到哪些问题?
下面有一些参数会有影响,这个是某大厂经过实战总结出来的宝贵经验
- 【cluster-node-timeout】:控制集群的节点切换参数,
master 堵塞超过 cluster-node-timeout/2 这个时间,就会主观判定该节点下线 pfail 状态,如果迁移Bigkey 阻塞时间超过 cluster-node-timeout/2,就可能会导致 master-slave 发生切换。
-
【migrate timeout】:控制迁移 io 的超时时间超过这个时间迁移没有完成,迁移就会中断。
-
【迁移重试周期】:迁移的重试周期是由水平扩容的节点数决定的,比如一个集群扩容 10 个节点,迁移失败后的重试周期就是 10 次。
-
【一个迁移重试周期内的重试次数】:在一个起迁移重试周期内,会有 3 次重试迁移,每一次的 migrate timeout 的时间分别是 10 秒、20 秒、30 秒,每次重试之间无间隔
比如一个集群扩容 10 个节点,迁移时候遇到一个 Bigkey,第一次迁移的 migrate timeout 是 10 秒,10 秒后没有完成迁移,就会设置 migrate timeout 为 20 秒重试,如果再次失败,会设置 migratetimeout 为 30 秒重试,如果还是失败,程序会迁移其他新 9 个的节点,但是每次在迁移其他新的节点之前还会分别设置migrate timeout 为 10 秒、20 秒、30 秒重试迁移那个迁移失败的 Bigkey。这个重试过程,每个重试周期阻塞(10+20+30)秒,会重试 10 个周期,共阻塞 600 秒。其实后面的 9个重试周期都是无用的,每次重试之间没有间隔,会连续阻塞了 Redis 实例
优化如下
-
【cluster-node-timeout】:延长超时时间默认是 60 秒,在迁移之前设置为 15 分钟,防止由于迁移 Bigkey 阻塞导致 master-slave 故障切换。
-
【migrate timeout】:减少阻塞时间为了最大限度减少实例阻塞时间,每次重试的超时时间都是 10 秒,3 次重试之间间隔 30 秒,这样最多只会连续阻塞 Redis 实例 10 秒。
-
【重试次数】:去掉了其他节点迁移的重试迁移失败后,只重试 3 次(重试是为了避免网络抖动等原因造成的迁移失败),每次重试间隔 30 秒,重试 3 次后都失败了,会暂停迁移,日志记录下 Bigkey,去掉了其他节点迁移的重试。
-
【优化日志记录】:日志记录迁移失败日志记录迁移节点、solt、key 信息,可以立即定位到问题节点及 key