1.背景
目前 LLMs 在训练过程中使用了大量的受版权保护数据,这些数据会导致大模型记忆并生成与训练数据相似的内容,从而引发版权问题。随着版权所有者对模型训练和部署中的版权问题提起诉讼(例如 Tremblay v. OpenAI, Inc. 和 Kadrey v. Meta Platforms, Inc.),如何防止模型生成受版权保护的内容 成为一个亟待解决的问题。因此,研究者们需要开发一种机制,称为 "版权下架"(copyright takedown) ,以防止模型输出与特定版权内容过于相似的文本。
2. 研究目的
评估 LLMs 中版权下架方法的可行性和副作用 ,并提出一个综合的评估框架 CoTaEval。该框架旨在评估版权下架方法在以下三个方面的表现:
- 低相似性:防止模型生成与版权内容过于相似的文本。
- 高实用性:保留模型对非版权内容(如事实性信息)的生成能力。
- 低开销:确保下架过程不会显著增加模型的计算负担。
3. 研究现状
目前,研究者们已经提出了多种方法来减少语言模型对训练数据的记忆和生成,例如:
- 系统提示(System Prompt):通过给模型提供初始指令来引导其行为。【不够通用,在面对非版权问题时会有影响】
- 解码时干预(Decoding-time Interventions):如 MemFree 和 R-CAD,通过在生成过程中过滤或调整内容。【容易生成不自然的文本】
- 训练时干预(Training-based Interventions):如机器遗忘(Machine Unlearning),通过修改模型参数来"遗忘"特定数据。【对模型本身的泛化能力有很大影响】
4. 作者的方法
作者提出了 CoTaEval ,这是一个综合的评估框架,用于系统地评估版权下架方法的效果。该框架包括以下内容:
- 评估语料库:涵盖新闻文章和书籍两种常见的版权相关文本。
评估语料库:
新闻文章: 使用 NewsQA 数据集,包含 CNN 文章及其相关问题和答案。
书籍: 使用 BookSum 数据集,包含书籍章节及其总结。
- 评估指标:包括八种相似性指标(如 LCS、ROUGE、Levenshtein Distance 等)和三种实用性指标(如 QA 性能、总结性能和模型通用性能)。
评估指标:
低相似性: 通过八种相似性指标(如 LCS、ROUGE、Levenshtein Distance 等)评估生成内容与版权内容的相似性。
高实用性: 通过 QA 性能(新闻文章)和总结性能(书籍)评估模型是否保留了非版权的事实性信息。同时,使用 MMLU 和 MT-Bench 评估模型的通用性能。
低开销: 测量下架方法对模型推理速度的影响。
- 效率评估:测量下架方法对模型推理速度的影响。
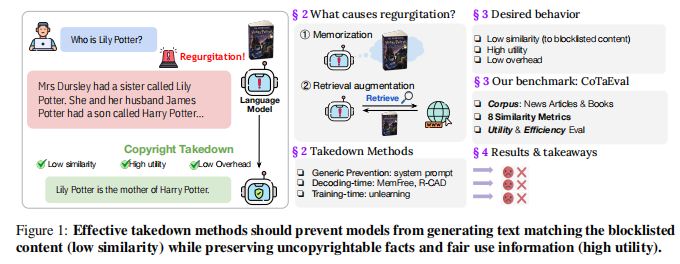
左侧小图为版权下架前后的效果,中间为模型输出有关版权内容的原因和模型下架的相关方案,右侧的图为期望的行为(作者自己提出来的)。
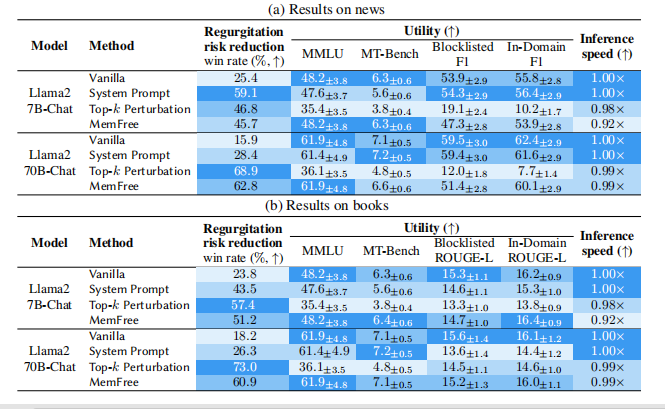
5. 结果
作者以RAG的形式将版权文本压缩在上下文中,在评估版权删除时,如果模型生成的内容与上下文中的版权内容相似,就说明未能有效工作