👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
-
- [1. init.py](#1. init.py)
- [2. model.py](#2. model.py)
- [3. predict.py](#3. predict.py)
- [4. utils.py](#4. utils.py)
- [5. val.py](#5. val.py)
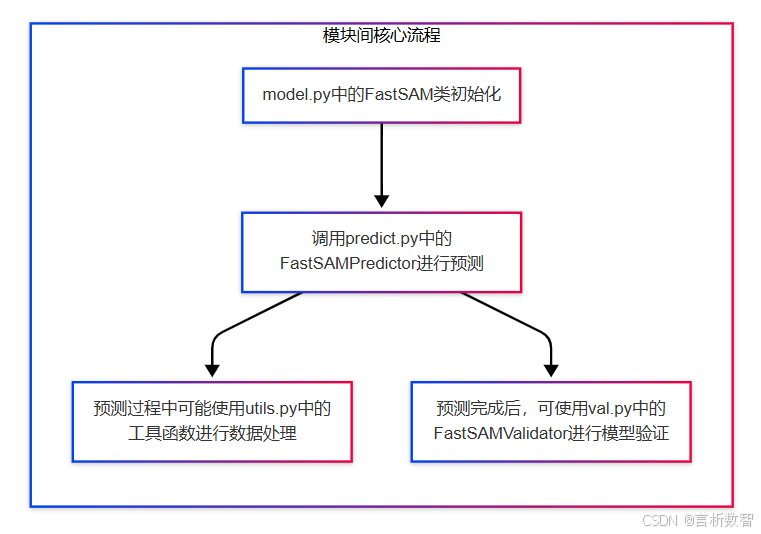
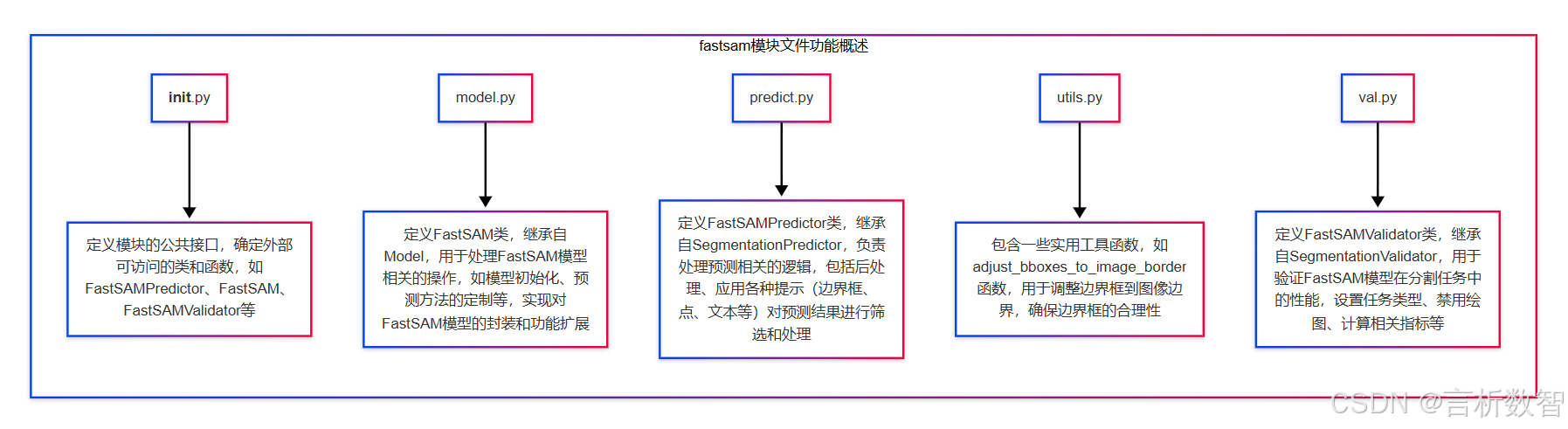
FastSAM 是一种目标检测和图像分割模型,Ultralytics 是一个在计算机视觉领域广泛使用的库,用于各种深度学习模型的训练、推理和评估等任务。- ultralytics-cfg-models-fastsam 这个路径下可能包含了 FastSAM 模型的配置文件,这些配置文件用于
定义模型的结构、超参数(如学习率、批次大小、训练轮数等)以及数据预处理和后处理的方式等。 - 同时,该路径也可能包含已经训练好的 FastSAM 模型权重文件,以便在进行推理或进一步微调时使用。
通过这些配置和模型文件,用户可以方便地使用 Ultralytics 库来加载 FastSAM 模型,进行图像分割任务,例如对输入的图像进行目标检测和分割,识别出图像中的不同物体并为其生成相应的分割掩码。- 此外,也可以基于这些配置和模型文件进行模型的训练和优化,以适应不同的数据集和应用场景。
1. init.py
python
from .model import FastSAM
# 从当前目录的model模块中导入FastSAM类
from .predict import FastSAMPredictor
# 从当前目录的predict模块中导入FastSAMPredictor类
from .val import FastSAMValidator
# 从当前目录的val模块中导入FastSAMValidator类
# 定义模块的公共接口,即可以通过from module import *导入的名称列表
__all__ = "FastSAMPredictor", "FastSAM", "FastSAMValidator" 2. model.py
-
FastSAM 即 Fast Segment Anything Model
- 一种
高效的图像分割模型,依托于 Ultralytics 的开发生态,在多领域展现出独特价值- 模型架构与原理: 它可能基于 Transformer 架构,通过对图像特征的深度挖掘,实现对各类物体的精准分割。
在处理复杂场景图像时,能有效捕捉物体的边缘和细节信息,以较低的计算成本快速生成高质量的分割结果。
- 模型架构与原理: 它可能基于 Transformer 架构,通过对图像特征的深度挖掘,实现对各类物体的精准分割。
- 功能特点
- 快速处理: 相比传统的图像分割模型,
FastSAM 在保证分割精度的同时,大幅提升了处理速度。在实时性要求较高的场景,如自动驾驶的道路场景分割、直播内容的实时物体分割等,能快速处理图像或视频流,满足实时性需求。 - 多模态提示支持: 支持
多种提示方式进行分割,如边界框(bounding boxes)、点(points)、标签(labels)和文本(texts)。用户可根据具体需求,灵活选择提示信息,引导模型对特定目标进行分割。 - 通用性强: 可应用于多种图像分割任务,
包括但不限于实例分割、语义分割和全景分割。无论是自然场景图像、医学影像,还是工业检测图像,都能展现出良好的分割性能。
- 快速处理: 相比传统的图像分割模型,
- 应用场景
- 计算机视觉研究: 为研究人员提供了一个高效的图像分割工具,可用于探索新的分割算法、验证研究思路。在新型神经网络架构的研究中,利用 FastSAM 快速获取分割结果,评估架构的有效性。
- 自动驾驶: 用于
识别道路上的车辆、行人、交通标志等目标,为自动驾驶汽车的决策提供关键信息。通过实时分割道路场景图像,帮助车辆准确感知周围环境,实现安全行驶。 - 医学影像分析: 在医学领域,能辅助医生对医学影像(如 X 光、CT、MRI 等)进行分析。
帮助医生快速分割出病变组织、器官等感兴趣区域,提高诊断效率和准确性。 - 工业检测: 在工业生产中,对产品表面缺陷进行检测时,可
分割出缺陷区域,判断产品是否合格。对电子芯片、机械零部件等进行质量检测,及时发现生产过程中的问题。
pythonfrom pathlib import Path # 导入 Path 类,用于处理文件路径 from ultralytics.engine.model import Model # 从 ultralytics 引擎模块导入 Model 基类 from .predict import FastSAMPredictor # 从当前包中导入 FastSAMPredictor 类,用于进行预测操作 from .val import FastSAMValidator # 从当前包中导入 FastSAMValidator 类,用于进行验证操作 class FastSAM(Model): """ FastSAM model interface for segment anything tasks. # FastSAM 模型接口,用于处理任意图像分割任务 # 该类继承自 Model 基类,为 FastSAM(快速任意分割模型)实现提供特定功能,可实现高效且准确的图像分割 Attributes: model (str): Path to the pre - trained FastSAM model file. # 预训练的 FastSAM 模型文件的路径 task (str): The task type, set to "segment" for FastSAM models. # 任务类型,对于 FastSAM 模型,设置为 "segment"(分割) Examples: >>> from ultralytics import FastSAM >>> model = FastSAM("last.pt") >>> results = model.predict("ultralytics/assets/bus.jpg") # 使用示例,展示如何导入 FastSAM 类、初始化模型并进行预测 """ def __init__(self, model="FastSAM-x.pt"): """ Initialize the FastSAM model with the specified pre - trained weights. # 使用指定的预训练权重初始化 FastSAM 模型 Args: model (str): Path to the pre - trained FastSAM model file. Defaults to "FastSAM-x.pt". # 预训练的 FastSAM 模型文件的路径,默认为 "FastSAM-x.pt" """ if str(model) == "FastSAM.pt": model = "FastSAM-x.pt" # 如果传入的模型名称是 "FastSAM.pt",则将其替换为 "FastSAM-x.pt" assert Path(model).suffix not in {".yaml", ".yml"}, "FastSAM models only support pre - trained models." # 断言传入的模型文件后缀不是 .yaml 或 .yml,因为 FastSAM 模型仅支持预训练模型 super().__init__(model=model, task="segment") # 调用父类 Model 的构造函数,传入模型路径和任务类型 def predict(self, source, stream=False, bboxes=None, points=None, labels=None, texts=None, **kwargs): """ # 对图像或视频源进行分割预测 # 支持使用边界框、点、标签和文本进行提示分割。该方法将这些提示信息打包并传递给父类的 predict 方法 Args: source (str | PIL.Image | numpy.ndarray): Input source for prediction, can be a file path, URL, PIL image, or numpy array. # 预测的输入源,可以是文件路径、URL、PIL 图像或 numpy 数组 stream (bool): Whether to enable real - time streaming mode for video inputs. # 是否为视频输入启用实时流模式 # 用于提示分割的边界框坐标,格式为 [[x1, y1, x2, y2], ...] # 用于提示分割的点坐标,格式为 [[x, y], ...] # 用于提示分割的类别标签 # 用于分割引导的文本提示 # 传递给预测器的其他关键字参数 Returns: # 包含预测结果的 Results 对象列表 """ prompts = dict(bboxes=bboxes, points=points, labels=labels, texts=texts) # 将边界框、点、标签和文本提示信息打包成字典 return super().predict(source, stream, prompts=prompts, **kwargs) # 调用父类的 predict 方法,传入输入源、流模式、提示信息和其他关键字参数,并返回预测结果 @property def task_map(self): """ # 返回一个字典,将分割任务映射到相应的预测器和验证器类 """ return {"segment": {"predictor": FastSAMPredictor, "validator": FastSAMValidator}} # 返回一个字典,键为 "segment",值为包含预测器和验证器类的字典 - 一种
3. predict.py
-
关键词: 图像分割预测、边界框的交并比、缩放掩码
-
CLIP模型
CLIP(Contrastive Language-Image Pretraining)模型是 OpenAI 开发的一种开创性的神经网络,通过互联网上大量多样的(图像,文本)对进行训练,具备强大的跨模态理解能力,能够将自然语言与图像信息紧密联系起来。- 模型架构
- 图像编码器: 可选用
Vision Transformer(ViT)或 ResNet 等架构。以 ViT 为例,它将图像划分为多个小块,然后像处理文本序列一样处理这些图像块,通过多头注意力机制捕捉图像的全局特征。 - 文本编码器: 基于文本 Transformer,把文本转换为连续的向量表示,在这个过程中理解文本语义和结构信息。
- 共享嵌入空间: 两个编码器将图像和文本投影到同一个向量空间,在这个空间中,语义相似的图像和文本对其向量距离更近,为后续的匹配任务奠定基础。
- 图像编码器: 可选用
- 零样本学习能力:
CLIP 最显著的优势是零样本学习。在 ImageNet 分类任务中,它无需使用 ImageNet 训练集中 128 万张标记示例进行训练,就能达到与原始 ResNet50 模型相匹配的性能。使用时,只要提供文本描述(如 "一只猫""一辆汽车"),CLIP 模型就能对图像进行分类,判断图像内容是否与文本匹配。
-
ViT-B/32ViT-B/32 是 CLIP 模型中使用的一种视觉 Transformer(Vision Transformer,ViT)架构的具体变体。- 模型结构:
"ViT":代表视觉 Transformer,是一种将 Transformer 架构应用于计算机视觉任务的模型。它将图像分割成一系列的图像块(patches),并将这些图像块作为输入序列,类似于自然语言处理中 Transformer 对文本序列的处理方式。通过这种方式,ViT 可以有效地学习图像中的全局信息和长期依赖关系。"B":通常表示基础(Base)版本,指的是模型的规模和复杂度处于中等水平。例如,在参数数量、层数、隐藏层维度等方面,基础版本具有一定的设定,是一种相对较为平衡的模型配置,既能够在性能和计算资源之间取得较好的权衡,又能在多种视觉任务上取得不错的效果。"32":表示图像块的大小为 32×32 像素。这意味着在将图像输入到 ViT 模型之前,会先将图像分割成边长为 32 像素的正方形小块。较小的图像块大小可以捕捉到更精细的图像细节,但也会增加模型的计算量和参数量;而较大的图像块大小则可以减少计算量,但可能会丢失一些细节信息。
pythonimport torch # 导入PyTorch库,用于深度学习相关的张量计算和模型操作 from PIL import Image # 导入PIL库的Image模块,用于处理图像 from ultralytics.models.yolo.segment import SegmentationPredictor # 从ultralytics的yolo模型的segment模块中导入SegmentationPredictor类,可能是用于图像分割预测的基类 from ultralytics.utils import DEFAULT_CFG, checks # 从ultralytics的utils模块中导入DEFAULT_CFG(可能是默认配置)和checks(可能用于检查某些条件或配置) from ultralytics.utils.metrics import box_iou # 从ultralytics的utils模块的metrics子模块中导入box_iou函数,可能用于计算边界框的交并比 from ultralytics.utils.ops import scale_masks # 从ultralytics的utils模块的ops子模块中导入scale_masks函数,可能用于缩放掩码 from .utils import adjust_bboxes_to_image_border # 从当前目录的utils模块中导入adjust_bboxes_to_image_border函数,可能用于调整边界框以适应图像边界 class FastSAMPredictor(SegmentationPredictor): # FastSAMPredictor类,继承自SegmentationPredictor,用于图像分割预测,并支持多种提示方式。 def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None): """ 初始化函数。 Args: cfg (dict, optional): 配置字典,默认为DEFAULT_CFG。 overrides (dict, optional): 用于覆盖默认配置的字典。 _callbacks (list, optional): 回调函数列表。 """ super().__init__(cfg, overrides, _callbacks) # 初始化一个空字典,用于存储各种提示信息(边界框、点、标签、文本等) self.prompts = {} def postprocess(self, preds, img, orig_imgs): """ 对模型预测结果进行后处理。 Args: preds (torch.Tensor): 模型的预测结果。 img (torch.Tensor): 输入的图像张量。 orig_imgs (list): 原始图像列表。 Returns: list: 经过后处理和提示应用后的结果列表。 """ # 从prompts字典中弹出【边界框】提示信息,如果不存在则返回None bboxes = self.prompts.pop("bboxes", None) # 从prompts字典中弹出【点】提示信息,如果不存在则返回None points = self.prompts.pop("points", None) # 从prompts字典中弹出【标签】提示信息,如果不存在则返回None labels = self.prompts.pop("labels", None) # 从prompts字典中弹出【文本】提示信息,如果不存在则返回None texts = self.prompts.pop("texts", None) # 调用父类的postprocess方法进行基本的后处理 results = super().postprocess(preds, img, orig_imgs) for result in results: # 创建一个表示整个图像边界的张量,格式为 [x1, y1, x2, y2] full_box = torch.tensor( [0, 0, result.orig_shape[1], result.orig_shape[0]], device=preds[0].device, dtype=torch.float32 ) # 调整预测的边界框,使其适应原始图像的边界 boxes = adjust_bboxes_to_image_border(result.boxes.xyxy, result.orig_shape) # 计算【全图像边界框与调整后的边界框】之间的交并比,找到【交并比大于0.9的索引】 idx = torch.nonzero(box_iou(full_box[None], boxes) > 0.9).flatten() if idx.numel() != 0: # 如果存在【交并比大于0.9的边界框,则将其设置为全图像边界】 result.boxes.xyxy[idx] = full_box # 调用prompt方法,应用各种提示信息到结果中 return self.prompt(results, bboxes=bboxes, points=points, labels=labels, texts=texts) def prompt(self, results, bboxes=None, points=None, labels=None, texts=None): """ 根据提供的提示信息(边界框、点、标签、文本)对分割结果进行筛选和处理。 Args: results (list or object): 分割结果,可以是【单个结果或结果列表】。 bboxes (list, optional): 边界框提示信息,格式为 [[x1, y1, x2, y2], ...]。 points (list, optional): 点提示信息,格式为 [[x, y], ...]。 labels (list, optional): 标签提示信息,与点提示信息对应。 texts (list, optional): 文本提示信息。 Returns: list: 经过提示筛选后的结果列表。 """ if bboxes is None and points is None and texts is None: # 如果没有提供任何提示信息,则直接返回原始结果 return results prompt_results = [] if not isinstance(results, list): # 如果结果不是列表,则将其转换为列表 results = [results] for result in results: if len(result) == 0: # 如果结果为空,则直接添加到提示结果列表中 prompt_results.append(result) continue masks = result.masks.data if masks.shape[1:] != result.orig_shape: # 如果【掩码的形状与原始图像形状不一致】,则缩放掩码 masks = scale_masks(masks[None], result.orig_shape)[0] # 初始化一个布尔张量,用于标记符合条件的分割结果 idx = torch.zeros(len(result), dtype=torch.bool, device=self.device) if bboxes is not None: # 将边界框提示信息转换为张量 bboxes = torch.as_tensor(bboxes, dtype=torch.int32, device=self.device) if bboxes.ndim == 1: # 如果边界框是一维的,则将其转换为二维 bboxes = bboxes[None] # 计算每个边界框的面积 bbox_areas = (bboxes[:, 3] - bboxes[:, 1]) * (bboxes[:, 2] - bboxes[:, 0]) # 计算每个掩码与边界框重叠部分的面积 mask_areas = torch.stack([masks[:, b[1] : b[3], b[0] : b[2]].sum(dim=(1, 2)) for b in bboxes]) # 计算每个掩码的总面积 full_mask_areas = torch.sum(masks, dim=(1, 2)) # 计算边界框与掩码的并集面积 union = bbox_areas[:, None] + full_mask_areas - mask_areas # 找到重叠面积与并集面积比值最大的索引,并将其对应的idx位置设为True idx[torch.argmax(mask_areas / union, dim=1)] = True if points is not None: # 将点提示信息转换为张量 points = torch.as_tensor(points, dtype=torch.int32, device=self.device) if points.ndim == 1: # 如果点是一维的,则将其转换为二维 points = points[None] if labels is None: # 如果没有提供标签,则创建全为1的标签张量 labels = torch.ones(points.shape[0]) # 将标签转换为张量 labels = torch.as_tensor(labels, dtype=torch.int32, device=self.device) assert len(labels) == len(points), ( f"Expected `labels` to have the same size as `point`, but got {len(labels)} and {len(points)}" ) # 根据标签的总和初始化point_idx,如果【标签总和为0(即全为负点)】,则设为全True,否则设为全False point_idx = ( torch.ones(len(result), dtype=torch.bool, device=self.device) if labels.sum() == 0 else torch.zeros(len(result), dtype=torch.bool, device=self.device) ) for point, label in zip(points, labels): # 根据点的位置和标签,更新point_idx point_idx[torch.nonzero(masks[:, point[1], point[0]], as_tuple=True)[0]] = bool(label) # 将point_idx与idx进行逻辑或操作 idx |= point_idx if texts is not None: if isinstance(texts, str): # 如果文本提示是字符串,则将其转换为列表 ??? texts = [texts] crop_ims, filter_idx = [], [] for i, b in enumerate(result.boxes.xyxy.tolist()): x1, y1, x2, y2 = (int(x) for x in b) if masks[i].sum() <= 100: # 如果掩码的总和小于等于100,则将其索引添加到filter_idx中并跳过 filter_idx.append(i) continue # 从原始图像中裁剪出边界框对应的区域,并转换为PIL图像 crop_ims.append(Image.fromarray(result.orig_img[y1:y2, x1:x2, ::-1])) # 使用CLIP模型计算裁剪图像与文本提示之间的相似度 similarity = self._clip_inference(crop_ims, texts) # 找到相似度最大的索引 text_idx = torch.argmax(similarity, dim=-1) if len(filter_idx): # 如果存在过滤索引,则调整text_idx text_idx += (torch.tensor(filter_idx, device=self.device)[None] <= int(text_idx)).sum(0) # 将text_idx对应的idx位置设为True idx[text_idx] = True # 将符合条件的结果添加到提示结果列表中 prompt_results.append(result[idx]) return prompt_results def _clip_inference(self, images, texts): """ 使用CLIP模型进行推理,计算图像与文本之间的相似度。 Args: images (list): PIL图像列表。 texts (list): 文本提示列表。 Returns: torch.Tensor: 图像与文本之间的相似度矩阵,形状为 (M, N),M为文本数量,N为图像数量。 """ try: import clip except ImportError: # 如果CLIP库未安装,则检查并安装 checks.check_requirements("git+https://github.com/ultralytics/CLIP.git") import clip if (not hasattr(self, "clip_model")) or (not hasattr(self, "clip_preprocess")): # 如果当前对象没有CLIP模型和预处理函数,则加载CLIP模型和预处理函数 self.clip_model, self.clip_preprocess = clip.load("ViT-B/32", device=self.device) # 对图像进行预处理,并将其转换为张量 images = torch.stack([self.clip_preprocess(image).to(self.device) for image in images]) # 对文本进行分词,并将其转换为张量 tokenized_text = clip.tokenize(texts).to(self.device) # 使用CLIP模型对图像进行编码,得到图像特征 image_features = self.clip_model.encode_image(images) # 使用CLIP模型对文本进行编码,得到文本特征 text_features = self.clip_model.encode_text(tokenized_text) # 对图像特征进行归一化 image_features /= image_features.norm(dim=-1, keepdim=True) # 对文本特征进行归一化 text_features /= text_features.norm(dim=-1, keepdim=True) # 计算图像特征与文本特征之间的相似度,并返回相似度矩阵 return (image_features * text_features[:, None]).sum(-1) def set_prompts(self, prompts): """ 设置提示信息字典。 Args: prompts (dict): 包含各种提示信息的字典,如 "bboxes", "points", "labels", "texts" 等。 """ self.prompts = prompts ```
4. utils.py
python
def adjust_bboxes_to_image_border(boxes, image_shape, threshold=20):
"""
将边界框调整到图像边界附近,确保边界框不会超出合理范围。
Args:
boxes (torch.Tensor或numpy.ndarray):
边界框的张量或数组,形状通常为 (N, 4),N表示边界框的数量,
每个边界框包含四个坐标值 (x1, y1, x2, y2),分别代表左上角和右下角的坐标。
image_shape (tuple): 图像的形状,格式为 (高度, 宽度)。
threshold (int, 可选): 接近边界的阈值。
如果边界框的坐标值与图像边界的距离小于该阈值,
则将边界框的坐标调整到边界上。默认为20。
Returns:
torch.Tensor或numpy.ndarray: 调整后的边界框张量或数组,形状与输入的boxes相同。
"""
# 获取图像的高度和宽度
h, w = image_shape
# 调整靠近图像左边界的边界框的x1坐标
boxes[boxes[:, 0] < threshold, 0] = 0 # x1
# 调整靠近图像上边界的边界框的y1坐标
boxes[boxes[:, 1] < threshold, 1] = 0 # y1
# 调整靠近图像右边界的边界框的x2坐标
boxes[boxes[:, 2] > w - threshold, 2] = w # x2
# 调整靠近图像下边界的边界框的y2坐标
boxes[boxes[:, 3] > h - threshold, 3] = h # y2
return boxes5. val.py
python
from ultralytics.models.yolo.segment import SegmentationValidator
# 从ultralytics的yolo模型的segment模块导入SegmentationValidator类
from ultralytics.utils.metrics import SegmentMetrics
# 从ultralytics的utils模块的metrics子模块导入SegmentMetrics类
class FastSAMValidator(SegmentationValidator):
# 定义FastSAMValidator类,继承自SegmentationValidator
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
"""
初始化FastSAMValidator类的实例。
Args:
dataloader (DataLoader, 可选): 数据加载器,用于加载验证数据。默认为None。
save_dir (str, 可选): 保存验证结果的目录。默认为None。
pbar (tqdm.tqdm, 可选): 进度条对象,用于显示验证过程的进度。默认为None。
args (Namespace, 可选): 包含验证参数的命名空间。默认为None。
_callbacks (list, 可选): 回调函数列表,用于在验证过程中执行特定的操作。默认为None。
"""
super().__init__(dataloader, save_dir, pbar, args, _callbacks) # 调用父类的初始化方法
self.args.task = "segment" # 设置任务类型为"segment"(分割)
self.args.plots = False # 禁用混淆矩阵和其他绘图,以避免错误
self.metrics = SegmentMetrics(save_dir=self.save_dir)
# 创建SegmentMetrics对象,用于计算分割任务的指标,并指定保存目录