目录
[1. 特征预处理详解](#1. 特征预处理详解)
[1.1 无量纲化处理](#1.1 无量纲化处理)
[1.2 二值化处理](#1.2 二值化处理)
[1.3 One-Hot编码](#1.3 One-Hot编码)
[1.4 缺失值处理](#1.4 缺失值处理)
[2. 特征选择详解](#2. 特征选择详解)
[2.1 过滤法](#2.1 过滤法)
[2.2 包装法:递归特征消除(RFE)](#2.2 包装法:递归特征消除(RFE))
[2.3 集成法:使用GBDT进行特征选择](#2.3 集成法:使用GBDT进行特征选择)
[3. 特征降维详解](#3. 特征降维详解)
[3.1 PCA (主成分分析)](#3.1 PCA (主成分分析))
[3.2 LDA (线性判别分析)](#3.2 LDA (线性判别分析))
[4. 数据闭环中的特征工程流程](#4. 数据闭环中的特征工程流程)
[4.1 数据收集阶段](#4.1 数据收集阶段)
[4.2 特征预处理阶段](#4.2 特征预处理阶段)
[4.3 特征选择与降维阶段](#4.3 特征选择与降维阶段)
[4.4 模型训练与评估阶段](#4.4 模型训练与评估阶段)
[4.5 特征改进阶段](#4.5 特征改进阶段)
[4.6 部署与在线学习阶段](#4.6 部署与在线学习阶段)
1. 特征预处理详解
1.1 无量纲化处理
在自动驾驶系统中,来自不同传感器的数据量纲差异很大:
-
具体应用场景 :
- 雷达数据可能是以米为单位(0-200m)
- 速度数据可能是以km/h为单位(0-120km/h)
- 加速度数据可能是以m/s²为单位(-10到+10m/s²)
-
归一化方法 :
pythonfrom sklearn.preprocessing import MinMaxScaler # 将所有传感器数据统一到[0,1]区间 scaler = MinMaxScaler() normalized_sensor_data = scaler.fit_transform(raw_sensor_data) -
标准化方法 :
pythonfrom sklearn.preprocessing import StandardScaler # 处理异常值丰富的数据,如突发刹车、急转弯等场景数据 std_scaler = StandardScaler() standardized_driving_behavior = std_scaler.fit_transform(driving_behavior_data)
1.2 二值化处理
自动驾驶中的二值化应用:
-
道路条件判断:如路面摩擦系数大于0.7为干燥路面(1),小于等于0.7为湿滑路面(0)
-
交通密度评估:前方车辆密度大于某阈值为拥堵(1),小于等于该阈值为畅通(0)
-
实现代码 :
pythonfrom sklearn.preprocessing import Binarizer # 设置阈值0.7,将连续的路面状况数据转为二值特征 binarizer = Binarizer(threshold=0.7) road_condition_binary = binarizer.transform(road_friction_data)
1.3 One-Hot编码
- 自动驾驶场景应用 :
-
将道路类型(城市道路、高速公路、乡村道路)转换为one-hot特征
-
将天气状况(晴天、雨天、雪天、雾天)转换为one-hot特征
-
实现方式:
pythonfrom sklearn.preprocessing import OneHotEncoder # 对道路类型进行编码 encoder = OneHotEncoder() road_type_encoded = encoder.fit_transform(road_type_data.reshape(-1, 1))
-
1.4 缺失值处理
自动驾驶系统中的缺失值场景:
-
传感器故障:某个摄像头或雷达暂时失效
-
GPS信号丢失:在隧道或高楼区域
-
处理方法 :
pythonfrom sklearn.impute import SimpleImputer # 使用均值填充缺失的距离数据 imputer = SimpleImputer(strategy='mean') fixed_distance_data = imputer.fit_transform(distance_data) # 对于GPS数据,可能使用前向填充方法 # 使用pandas的forward fill方法 import pandas as pd gps_df = pd.DataFrame(gps_data) gps_df_filled = gps_df.fillna(method='ffill')
2. 特征选择详解
2.1 过滤法
-
方差选择法 :
pythonfrom sklearn.feature_selection import VarianceThreshold # 删除方差小于阈值的特征,例如几乎不变的传感器数据 selector = VarianceThreshold(threshold=0.1) selected_features = selector.fit_transform(sensor_features) -
卡方检验法 :
pythonfrom sklearn.feature_selection import SelectKBest, chi2 # 选择与驾驶行为(如变道、减速)最相关的k个特征 selector = SelectKBest(chi2, k=10) selected_features = selector.fit_transform(X, driving_behavior)
2.2 包装法:递归特征消除(RFE)
python
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
# 使用随机森林作为基模型,迭代筛选重要特征
model = RandomForestClassifier()
rfe = RFE(estimator=model, n_features_to_select=20)
selected_features = rfe.fit_transform(X, y)
# 查看特征重要性排名
feature_ranking = rfe.ranking_递归特征消除(RFE)的本质是一种特征选择方法,它通过反复训练模型、评估特征重要性并移除最不重要的特征来逐步筛选出最有价值的特征子集。这是一种"包装法"的特征选择技术,因为它"包装"了一个机器学习模型来评估特征的重要性。
2.3 集成法:使用GBDT进行特征选择
python
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.feature_selection import SelectFromModel
# 使用梯度提升树模型评估特征重要性
gbdt = GradientBoostingClassifier()
selector = SelectFromModel(gbdt, threshold="mean")
selected_features = selector.fit_transform(X, y)
# 查看最重要的特征
feature_importances = gbdt.feature_importances_这种方法的本质是:
- 训练一个 GBDT 模型 :让 GBDT 学习数据
X和目标y之间的关系,并在学习过程中自动评估出每个输入特征X的重要程度。- 基于重要性进行筛选:使用 GBDT 给出的重要性分数,设定一个标准(这里是平均重要性),自动挑选出那些被 GBDT 认为足够重要的特征。
这种方法通常被归类为嵌入法 (Embedded Method) 特征选择,因为特征选择的过程是嵌入在模型(GBDT)训练过程中的(模型训练直接产生了特征重要性)。
3. 特征降维详解
3.1 PCA (主成分分析)
PCA在自动驾驶中的应用:
-
传感器数据压缩:将多通道雷达数据降维为主要的几个维度
-
环境特征提取:从摄像头原始像素中提取主要特征
-
实现代码 :
pythonfrom sklearn.decomposition import PCA # 将100维的传感器数据降至10维,保留主要信息 pca = PCA(n_components=10) reduced_features = pca.fit_transform(sensor_data) # 查看各主成分的解释方差比例 explained_variance_ratio = pca.explained_variance_ratio_
3.2 LDA (线性判别分析)
应用场景:
-
驾驶场景分类:将环境数据降维后用于区分不同驾驶场景(城市、高速、乡村)
-
驾驶行为识别:将车辆状态数据降维后用于识别不同驾驶行为(正常行驶、变道、超车)
-
实现代码 :
pythonfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 使用LDA同时进行降维和分类,将特征降至n_classes-1维 lda = LinearDiscriminantAnalysis(n_components=2) reduced_features = lda.fit_transform(X, driving_scenario) # 使用降维后的特征进行预测 predicted_scenario = lda.predict(new_X)
4. 数据闭环中的特征工程流程
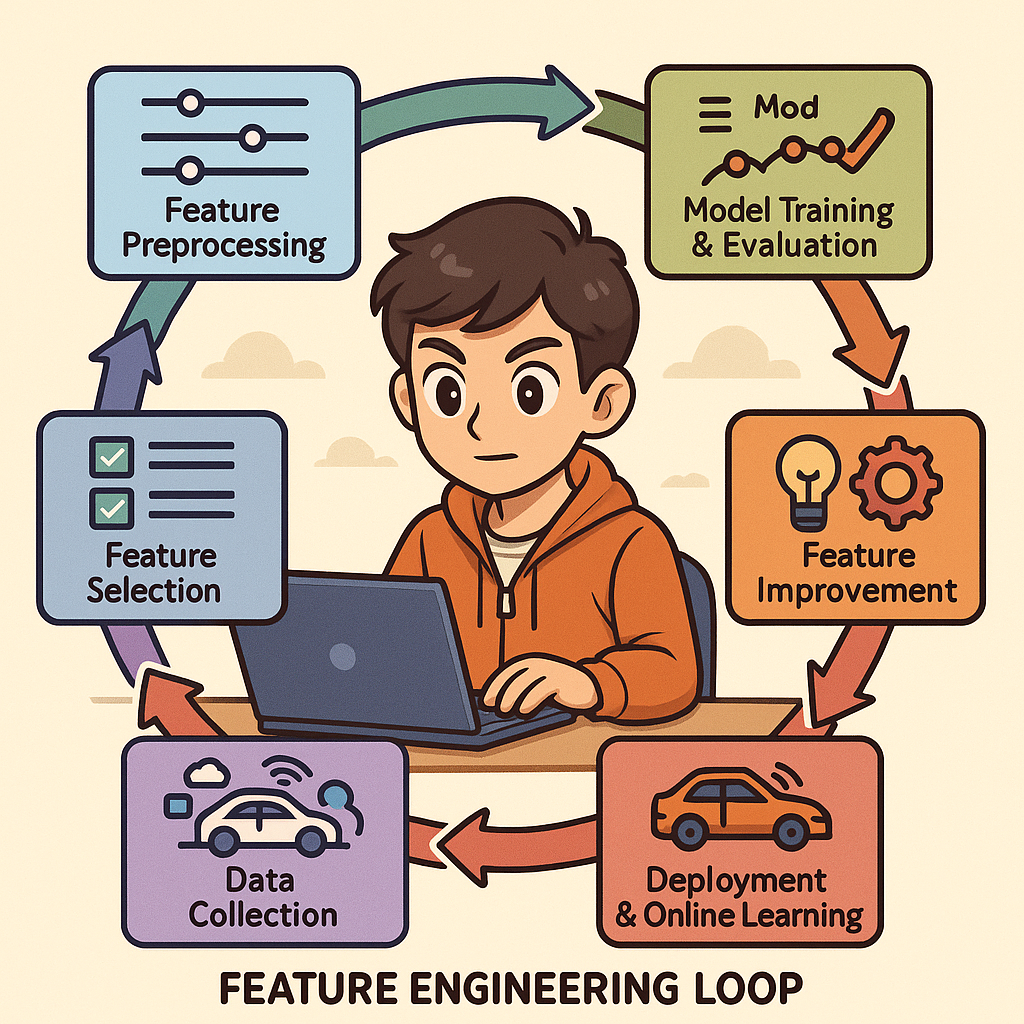
在自动驾驶数据闭环中,特征工程形成以下闭环流程:
4.1 数据收集阶段
- 收集各类传感器原始数据
- 记录车辆状态和驾驶员操作数据
- 记录环境和路况信息
4.2 特征预处理阶段
- 对原始数据进行清洗、标准化
- 处理缺失值和异常值
- 进行特征变换和编码
4.3 特征选择与降维阶段
- 筛选最相关的特征
- 降低数据维度,提高计算效率
- 生成高质量特征集
4.4 模型训练与评估阶段
- 使用处理后的特征训练模型
- 评估模型效果
- 分析特征贡献度
4.5 特征改进阶段
- 基于模型反馈调整特征处理方法
- 添加新的特征或移除无效特征
- 优化特征处理流程
4.6 部署与在线学习阶段
- 将特征工程流程部署到生产环境
- 收集新数据,持续优化特征
- 闭环反馈到数据收集阶段
5、性能与扩展瓶颈
问题分析: 百亿级数据量对系统性能提出了极高要求,各环节可能出现瓶颈:
-
数据摄取吞吐: 以每日百亿计的图像/音频输入计算,平均每秒约十万级别事件。Kafka虽支持高吞吐,但需要足够多的Broker和分区来并行处理,同时下游消费者(如Spark或Ray)必须跟上速度,否则消息堆积会导致延迟甚至数据过期丢弃。网络带宽也是瓶颈之一:若移动端直接上传原始图片/音频,带宽占用和传输延迟都会很大。
-
特征提取计算: 对每条数据执行深度学习模型推理提取特征是计算密集型任务。百亿级数据意味着推理调用非常频繁,哪怕单次推理100ms,累计也非常庞大。没有充分的并行和加速(GPU)支持,将无法在可接受时间内处理完当日数据。即使有大规模GPU集群,成本和调度也需要优化。
-
向量检索与存储: 存储每日提取的全部特征向量并支持相似检索,对存储和查询性能都是巨大挑战。以每个特征512维、单精度浮点计,百亿级向量一天就产生约百TB的数据。如果全部常驻内存几乎不可能,需要借助磁盘或压缩技术。检索方面,即使采用近似最近邻(ANN)算法,向量数量级过高时查询延迟和召回率也难平衡。FAISS等库在单机可索引上亿向量,但针对10^10级别数据通常需要集群分片。如何对向量分区(按来源、时间等)以及选择合适索引类型(如IVF, HNSW, PQ)将显著影响性能。并且,新数据不断涌入需要动态更新索引,频繁重建索引可能中断查询或耗时过长。
-
模型训练与闭环: 闭环应用意味着需定期用新数据训练或微调模型。每天的数据量极大,不可能全部用于每日训练,否则训练本身耗时难以接受且可能过拟合过多冗余数据。训练阶段的样本选择、频率需要权衡。分布式训练虽然可加速但受限于硬件和网络。训练完成后,还要将更新模型部署到移动端或服务端,这涉及模型转换和分发,也可能成为周期中的延迟瓶颈。
-
查询实时性: 机器人在实际场景中使用检索结果时,对延迟非常敏感。一次完整查询流程包括:移动端特征提取->上传查询向量->后端近邻搜索->返回结果。这要求从特征提取到返回结果尽可能低延迟。如检索用于导航或决策,延迟过高会影响车端反应速度。
6、总结
数据闭环流程确保了特征工程能够不断适应变化的驾驶环境和条件,提高自动驾驶系统的性能和安全性。
通过在自动驾驶数据闭环中实施这些详细的特征工程方法,可以显著提高模型的准确性、鲁棒性和实时性能,为安全可靠的自动驾驶系统奠定基础。