本文首先对Xtuner这一微调框架进行简单的介绍。手把手演示如何使用Xtuner对模型进行微调训练,包括数据准备、训练命令执行及训练过程中的监控技巧。最后,在完成微调之后,本文还将介绍如何对微调结果进行简单对话测试。
一、Xtuner微调框架
XTuner 是一个功能强大、易于使用的大模型微调工具,其特点在于低成本、高效率和硬件友好性。通过支持分布式训练,支持LoRA与QLoRA和众多开源模型,XTuner 为开发者提供了灵活的微调解决方案,适用于广泛的实际应用场景。说明文档链接放在下面啦:
欢迎来到 XTuner 的中文文档![]() https://xtuner.readthedocs.io/zh-cn/latest/【注】关于它和llamafactory的对比我认为没必要只用一个框架,如果这个解决不了就用另一个。
https://xtuner.readthedocs.io/zh-cn/latest/【注】关于它和llamafactory的对比我认为没必要只用一个框架,如果这个解决不了就用另一个。
二、QLoRA微调实操
(1)快速安装
方法一:通过pip安装
bash
# 先创建一个专属的conda虚拟环境
conda create -n xtuner python=3.10
# 激活进入
conda activate xtuner
# 安装xtuner库
pip install xtuner【注】 如果activate进入不了,就先执行conda init然后关掉终端,重新打开就行了。
方法二(推荐):从源码可编辑模式安装
bash
# 先创建一个专属的conda虚拟环境
conda create -n xtuner python=3.10
# 激活进入
conda activate xtuner
# 再去github上面下载源码
git clone https://github.com/InternLM/xtuner.git
# 必须进入源码路径
cd xtuner
# 再执行安装命令
pip install -e .
【注】使用源码可编辑模式来安装的好处就在于,后续微调修改配置文件我们可以很方便的找到源码。
测试是否安装成功:xtuner list-cfg
bash
xtuner list-cfg 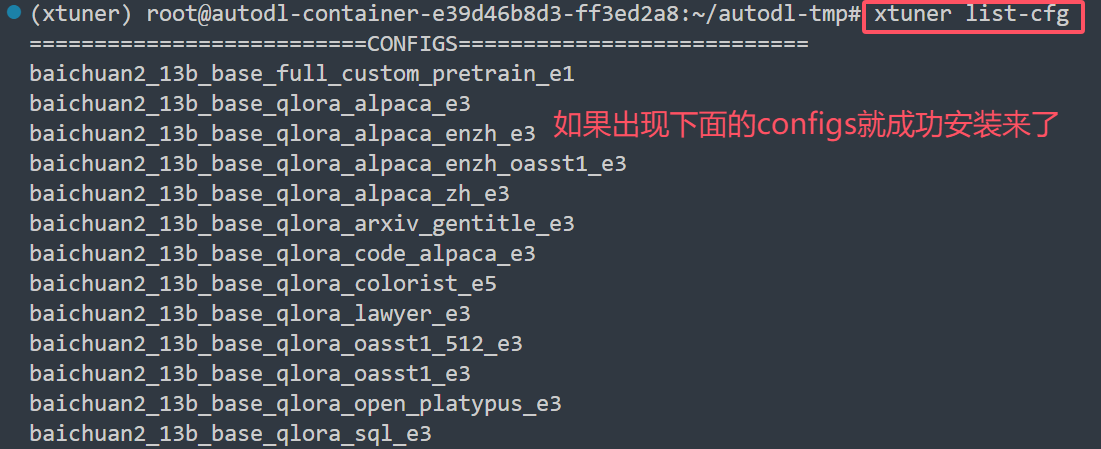
(2)准备大模型
这里我们使用书生浦语2.5的1.8b模型,魔塔社区的链接给大家放在这里了:书生·浦语2.5-1.8B-对话
我们使用魔塔的SDK来下载模型,代码如下:
python
from modelscope import snapshot_download
# 我一般会创建一个本地模型文件夹来存
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2_5-1_8b-chat', cache_dir='./local_models')如果报错找不到库,No module named 'modelscope'就去pip一下,很简单:
bash
pip install modelscope
(3)准备数据集
在成功安装 XTuner 和下载好大模型后,便可以开始进行模型的微调。演示如何使用 XTuner,应用 QLoRA 算法在 Colorist 数据集上微调 internlm2_5-1_8b-chat。魔塔上的数据集链接我放在这里了:该数据集为,颜色建议-16进制,颜色数据集
使用git来下载数据集,命令如下:
bash
git clone https://www.modelscope.cn/datasets/fanqiNO1/colors.git(4)修改微调配置文件
XTuner 提供了多个开箱即用的配置文件,可以通过xtuner list-cfg查看,其实我建议可编辑模式安装就可以直接在文件夹里面看到这些配置文件了。
微调配置文件比较繁琐,我将我认为最基础且重要的修改部分列一个表:
|-------------------------------|--------------------|
| 修改项 | 说明 |
| pretrained_model_name_or_path | 待修改的预训练模型存放路径 |
| data_path | 微调数据集 |
| max_length | 最大截断长度 |
| prompt_template | 对话模版(要和推理的时所用一致) |
| batch_size | 批次大小 |
| max_epochs | 最大训练轮次(建议给大点) |
| dataset_map_fn | 设置数据集格式函数 |
| load_in_8bit / load_in_4bit | 选择qlora的量化等级(建议8位) |
【注】如果你想了解更多的配置参数是什么意思,你可以直接参考官方文档:修改训练配置
不要修改源码中的内容,建议是每次微调的时候复制一份原始配置文件,我的做法是用一个文件夹来单独存放我自己微调的配置文件,如下图。
我们要对配置文件修改诸多地方,具体看下面的截图逐一介绍:
① PART 1 Settings
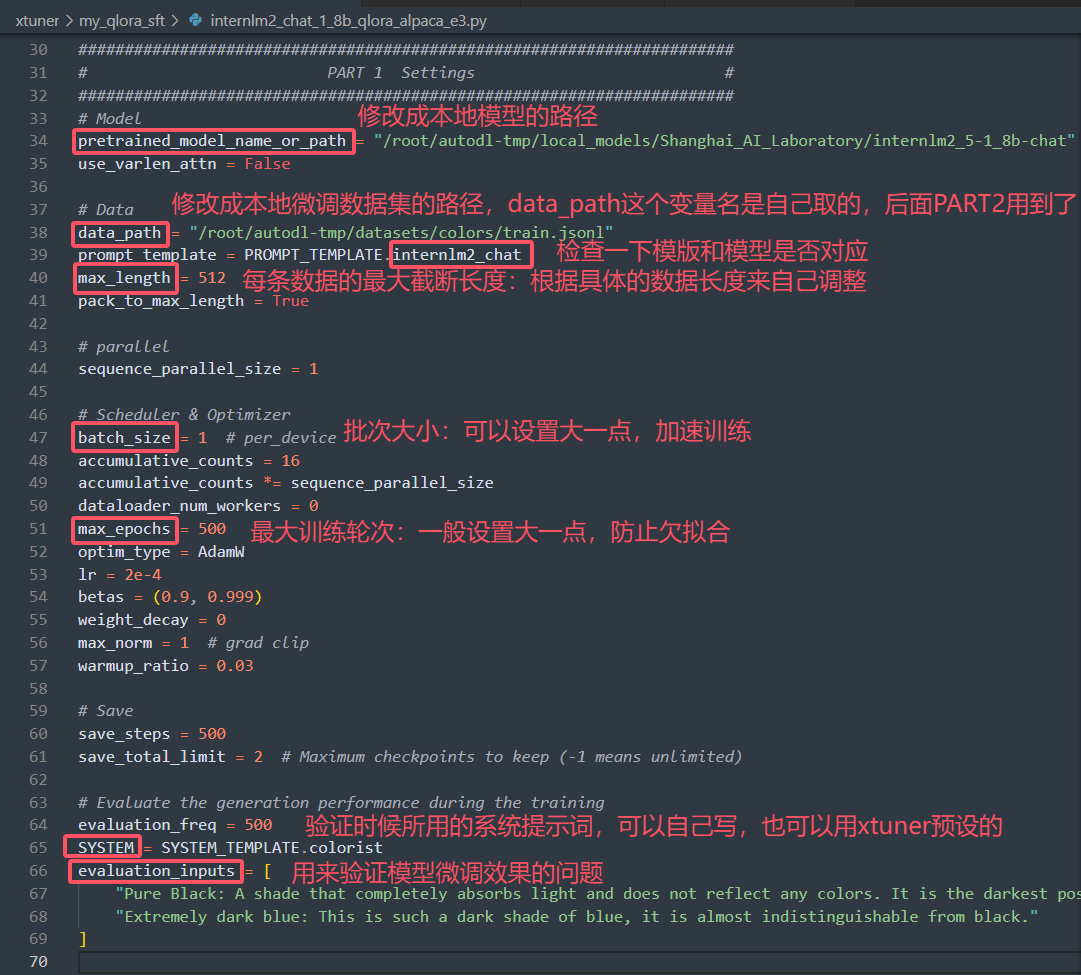
关于预设对话模版和系统提示词见下图:
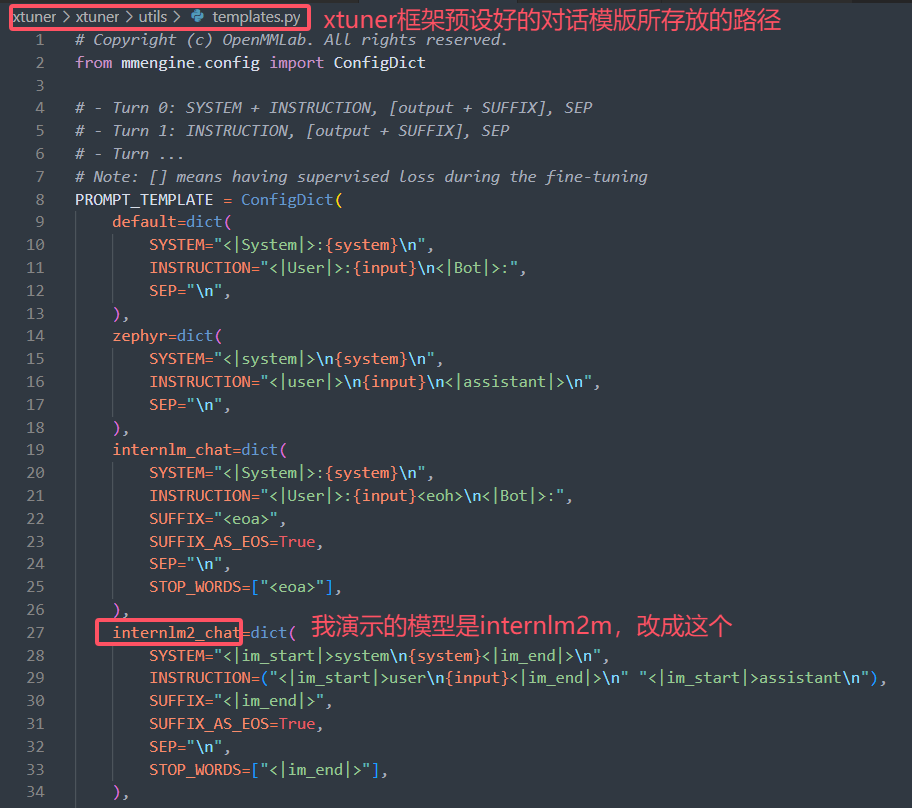
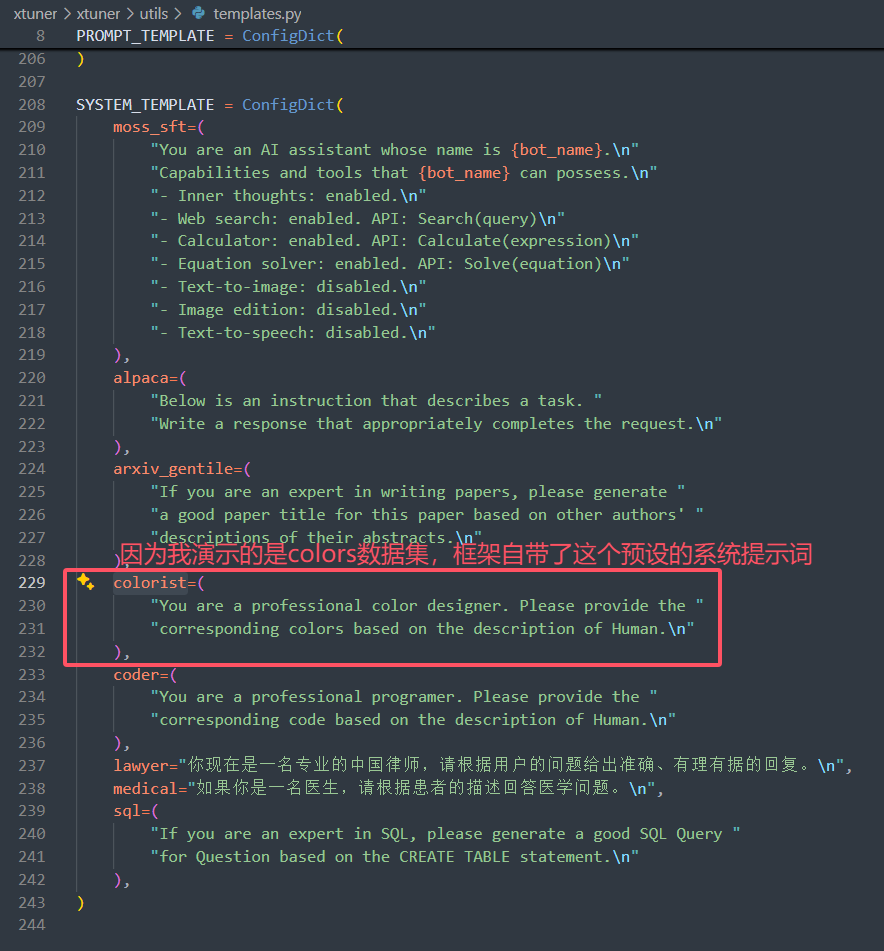 ② PART 2 Model & Tokenizer
② PART 2 Model & Tokenizer
 ③ PART 3 Dataset & Dataloader
③ PART 3 Dataset & Dataloader
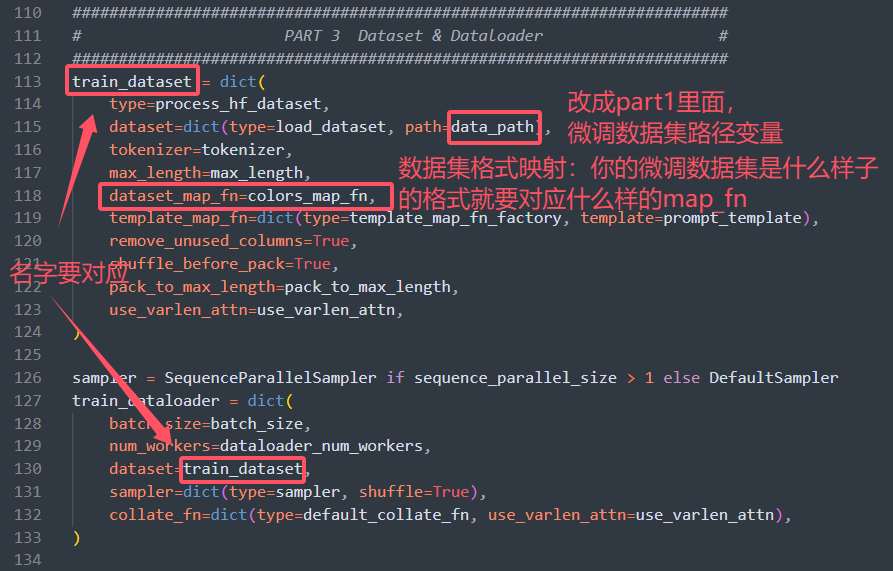
xtuner自带的map_fn在 xtuner/xtuner/dataset/map_fns/dataset_map_fns 路径下,如果你拿到的原始微调数据集格式和框架要求不符合,建议是用脚本修改成alpaca,然后使用alpaca_map_fn
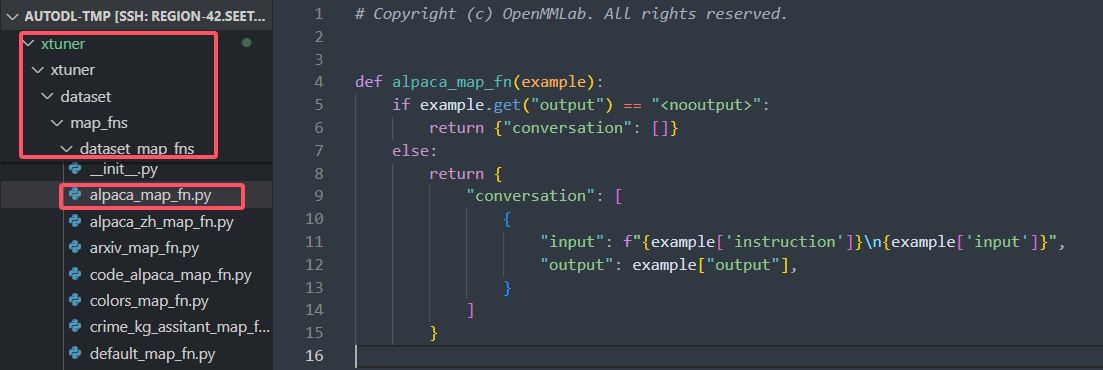 (5)启动微调训练
(5)启动微调训练
① 单机单卡(默认)
bash
# train 命令后面加上配置文件的绝对路径
xtuner train /root/autodl-tmp/xtuner/my_qlora_sft/internlm2_chat_1_8b_qlora_alpaca_e3.py② 单机多卡
bash
# 使用NPROC_PER_NODE环境变量设定多卡推理的GPU数量
NPROC_PER_NODE=${GPU_NUM} xtuner train /root/autodl-tmp/xtuner/my_qlora_sft/internlm2_chat_1_8b_qlora_alpaca_e3.py三、用Xtuner自带的推理功能测试模型对话
在这里我演示的是不进行权重合并,而是直接 LLM + LoRA Adapter 进行对话:
bash
xtuner chat \
<预训练模型的绝对路径> \
--adapter <lora适配器的绝对路径> \
--prompt-template <对话模版> \