1. 算法原理对比
| 对比维度 | DBSCAN | K-Means |
|---|---|---|
| 聚类基础 | 基于密度(数据点分布的紧密程度) | 基于距离(数据点与中心点的欧氏距离) |
| 核心思想 | 将高密度区域连接成簇,低密度区域视为噪声 | 最小化簇内平方误差(SSE) |
| 数学基础 | 图论(密度可达性) | 迭代优化(Lloyd算法) |
| 是否需要预设K | ❌ 自动确定簇数 | ✅ 必须预先指定K值 |
2. 参数对比
| 参数 | DBSCAN | K-Means |
|---|---|---|
| 关键参数 | eps(邻域半径)、min_samples(最小点数) |
n_clusters(簇数K) |
| 参数敏感性 | 高度敏感(eps和min_samples影响结果) |
敏感(K值直接影响聚类效果) |
| 参数选择方法 | 通过k-距离图或经验值选择eps |
肘部法(Elbow Method)、轮廓系数等 |
3. 聚类结果特性对比
| 特性 | DBSCAN | K-Means |
|---|---|---|
| 簇形状 | 适应任意形状(如环形、半月形) | 仅适应凸形簇(如球形、椭圆形) |
| 噪声处理 | ✅ 明确识别噪声点 | ❌ 所有点强制归属到某个簇 |
| 簇大小均衡性 | 可处理不同密度的簇 | 假设簇大小相近 |
| 边界点处理 | 边界点可能属于多个簇(密度相连) | 强制分配到最近的中心点 |
4. 计算复杂度与性能
| 性能维度 | DBSCAN | K-Means |
|---|---|---|
| 时间复杂度 | 平均O(n log n)(使用空间索引如KD树时) | O(n·K·I)(I为迭代次数,通常K≪n) |
| 大数据集适应性 | 中等(高维数据性能下降) | 较好(可通过Mini-Batch优化) |
| 并行化 | 较难并行 | 容易并行(如K-Means++) |
5. 适用场景对比
| 场景 | DBSCAN | K-Means |
|---|---|---|
| 数据分布 | 非凸形状、密度不均、含噪声 | 凸形簇、密度均匀 |
| 典型应用 | 异常检测、地理空间聚类(如地图热点分析) | 客户分群、图像压缩、特征工程 |
| 高维数据 | 表现较差(维度灾难) | 可通过PCA降维后使用 |
6. 可视化对比(示例)
DBSCAN结果
- 能识别复杂形状和噪声点(红色为噪声):
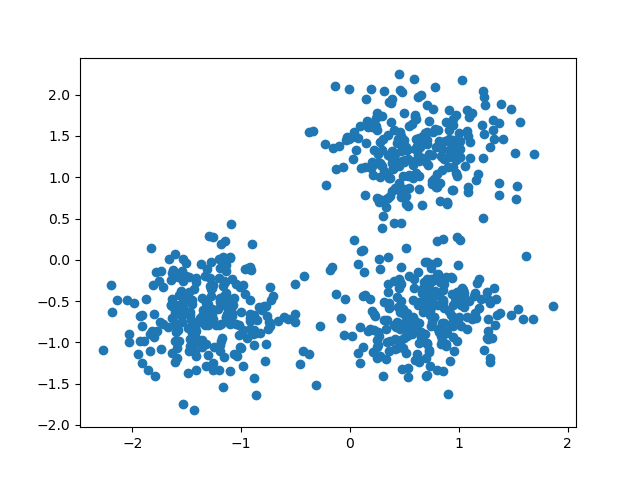
K-Means结果
- 强制划分为球形簇,无法处理噪声:
7. 总结选择建议
-
选择DBSCAN当:
- 数据形状复杂(如环形、螺旋形)。
- 需要自动检测噪声/离群点。
- 不确定簇数量(如探索性分析)。
-
选择K-Means当:
- 数据呈凸分布(如球形簇)。
- 需要高效计算(大数据集)。
- 簇数量已知或可预估。
8. 代码对比示例
python
# DBSCAN vs K-Means 代码对比
from sklearn.cluster import DBSCAN, KMeans
from sklearn.datasets import make_moons
# 生成半月形数据
X, _ = make_moons(n_samples=300, noise=0.05, random_state=0)
# DBSCAN
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan_labels = dbscan.fit_predict(X) # 可能含噪声点(标签=-1)
# K-Means
kmeans = KMeans(n_clusters=2)
kmeans_labels = kmeans.fit_predict(X) # 所有点强制分配关键结论
- DBSCAN 更灵活但参数难调,适合复杂形状和噪声数据。
- K-Means 更高效但假设数据为凸分布,适合规整簇的快速聚类。