文章目录
引言
- 逻辑回归是机器学习中最基础且重要的分类算法之一,广泛应用于各种二分类问题。本文将从数学原理出发,详细讲解逻辑回归的工作机制,并通过Python代码实现帮助初学者真正掌握这一算法。
逻辑回归基础
- 逻辑回归虽然名字中有"回归",但它实际上是一种分类算法,主要用于解决二分类问题。其核心思想是通过sigmoid函数将线性回归的输出映射到(0,1)区间,表示样本属于某一类的概率。
Sigmoid函数
- Sigmoid函数(也称为逻辑函数)的数学表达式为:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1 + e^{-z}} g(z)=1+e−z1 - 函数有的特性:它的导数可以用自身表示:
g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) g'(z) = g(z)(1 - g(z)) g′(z)=g(z)(1−g(z)) - 详细推导:Sigmoid函数导数推导详解
损失函数 数学推导
- 逻辑回归使用交叉熵损失函数 (也称为对数损失),对于单个样本,损失函数为:
J ( θ ) = − y log ( h θ ( x ) ) − ( 1 − y ) log ( 1 − h θ ( x ) ) J(\theta) = -y\log(h_\theta(x)) - (1-y)\log(1-h_\theta(x)) J(θ)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
其中 h θ ( x ) = g ( θ T x ) h_\theta(x) = g(\theta^T x) hθ(x)=g(θTx)是我们的预测函数。
梯度下降
- 为了找到最优参数 θ \theta θ,我们需要最小化损失函数。梯度下降法通过不断沿着梯度的反方向更新参数来实现这一目标。参数更新公式为:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta) θj:=θj−α∂θj∂J(θ)
其中 α \alpha α是学习率,控制每次更新的步长。
偏导数推导
- 推导损失函数对 θ j \theta_j θj的偏导数:
∂ ∂ θ j J ( θ ) = − 1 m ∑ i = 1 m ( y i 1 h θ ( x i ) − ( 1 − y i ) 1 1 − h θ ( x i ) ) ∂ ∂ θ j h θ ( x i ) = − 1 m ∑ i = 1 m ( y i 1 g ( θ T x i ) − ( 1 − y i ) 1 1 − g ( θ T x i ) ) g ( θ T x i ) ( 1 − g ( θ T x i ) ) x i j = − 1 m ∑ i = 1 m ( y i ( 1 − g ( θ T x i ) ) − ( 1 − y i ) g ( θ T x i ) ) x i j = 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x i j \begin{align*} \frac{\partial}{\partial \theta_j} J(\theta) &= -\frac{1}{m}\sum_{i=1}^m \left(y_i \frac{1}{h_\theta(x_i)} - (1-y_i)\frac{1}{1-h_\theta(x_i)}\right) \frac{\partial}{\partial \theta_j} h_\theta(x_i) \\ &= -\frac{1}{m}\sum_{i=1}^m \left(y_i \frac{1}{g(\theta^T x_i)} - (1-y_i)\frac{1}{1-g(\theta^T x_i)}\right) g(\theta^T x_i)(1-g(\theta^T x_i)) x_i^j \\ &= -\frac{1}{m}\sum_{i=1}^m \left(y_i(1-g(\theta^T x_i)) - (1-y_i)g(\theta^T x_i)\right) x_i^j \\ &= \frac{1}{m}\sum_{i=1}^m (h_\theta(x_i) - y_i) x_i^j \end{align*} ∂θj∂J(θ)=−m1i=1∑m(yihθ(xi)1−(1−yi)1−hθ(xi)1)∂θj∂hθ(xi)=−m1i=1∑m(yig(θTxi)1−(1−yi)1−g(θTxi)1)g(θTxi)(1−g(θTxi))xij=−m1i=1∑m(yi(1−g(θTxi))−(1−yi)g(θTxi))xij=m1i=1∑m(hθ(xi)−yi)xij - 有趣的是,最终的表达式与线性回归的梯度形式相同,尽管它们的损失函数完全不同。
Python实现
python
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris["data"][:, 3:] # 只使用花瓣宽度特征
y = (iris["target"] == 2).astype(np.int64) # 1 if Iris-Virginica, else 0
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练逻辑回归模型
log_reg = LogisticRegression(solver='sag', max_iter=1000)
log_reg.fit(X_train, y_train)
# 预测新数据
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
y_pred = log_reg.predict(X_new)
# 可视化优化版本
plt.figure(figsize=(10, 6))
plt.plot(X_new, y_proba[:, 1], "g-", label="Probability of Iris-Virginica")
plt.plot(X_new, y_proba[:, 0], "b--", label="Probability of Not Iris-Virginica")
# 寻找概率为0.5时的X值作为决策边界
decision_boundary = X_new[np.abs(y_proba[:, 1] - 0.5).argmin()]
plt.axvline(x=decision_boundary[0], color='r', linestyle='--', label='Decision Boundary (P=0.5)')
plt.xlabel("Petal Width (cm)")
plt.ylabel("Probability")
plt.legend(loc="center left")
plt.title("Logistic Regression - Probability of Class Membership")
plt.grid(True)
plt.show()
# 评估模型
print("Test accuracy:", log_reg.score(X_test, y_test))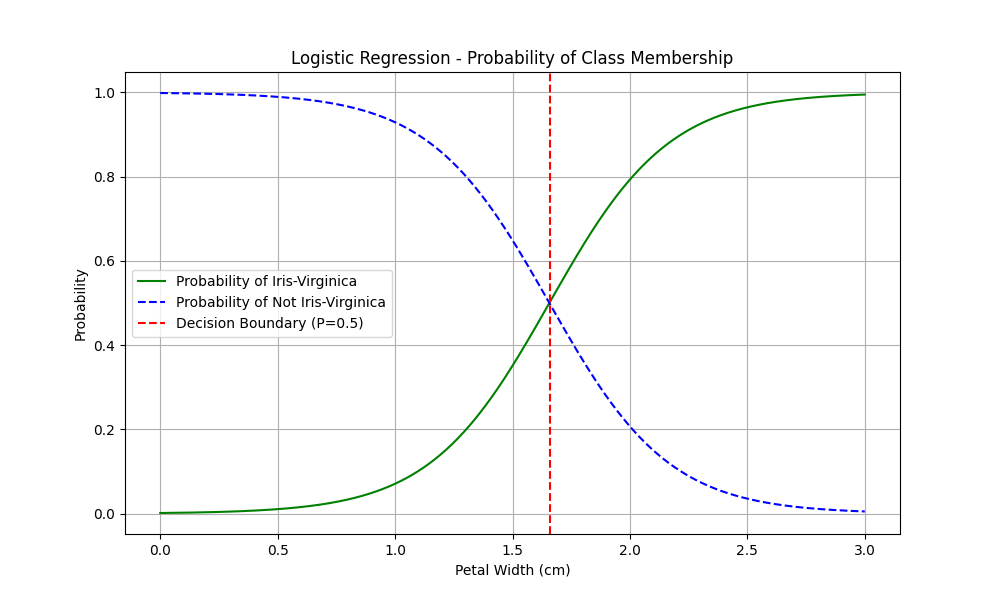
正则化
- 为了防止过拟合,我们可以在损失函数中加入正则化项。常用的有L1正则化和L2正则化。
正则化损失函数
J ( θ ) = 1 m ∑ i = 1 m − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) + λ 2 m ∑ j = 1 n θ j 2 J(\theta) = \frac{1}{m}\sum_{i=1}^m \left-y\^{(i)}\\log(h_\\theta(x\^{(i)})) - (1-y\^{(i)})\\log(1-h_\\theta(x\^{(i)}))\\right + \frac{\lambda}{2m}\sum_{j=1}^n \theta_j^2 J(θ)=m1i=1∑m−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))+2mλj=1∑nθj2
- 对应的梯度为:
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j \frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m}\sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} + \frac{\lambda}{m}\theta_j ∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj
- 在scikit-learn中,通过参数
C控制正则化强度,其中 C = 1 λ C = \frac{1}{\lambda} C=λ1。
python
# 使用正则化的逻辑回归
log_reg_l2 = LogisticRegression(penalty='l2', C=0.1, solver='lbfgs', max_iter=1000)
log_reg_l2.fit(X_train, y_train)
log_reg_l1 = LogisticRegression(penalty='l1', C=0.1, solver='liblinear', max_iter=1000)
log_reg_l1.fit(X_train, y_train)总结
- 逻辑回归是一种概率分类模型,输出0到1之间的概率值。
- 使用sigmoid函数将线性输出映射到概率空间。
- 通过交叉熵损失函数衡量预测与真实值的差异。
- 使用梯度下降法优化模型参数。
- 可以加入正则化项防止过拟合。
- 在实践中,可以使用scikit-learn等库方便地实现逻辑回归。