机器学习的一般原理
基于实例的学习及其术语
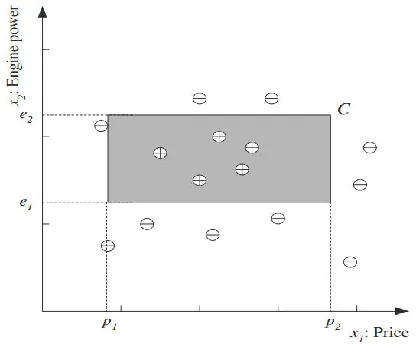
家用汽车
属性为:价格和发动机的马力
描述方法: x = x 1 x 2 x = \begin{bmatrix} x_1\\ x_2\\ \end{bmatrix} x=x1x2
r = { 1 正例 0 负例 r=\left\{ \begin{matrix} 1 \ 正例\\ 0 \ 负例\\ \end{matrix} \right. r={1 正例0 负例
X = { x t , r t } t = 1 N X={\{x^t,r^t\}}^N_{t=1} X={xt,rt}t=1N
假设类
( p 1 < = p r i c c e < = p 2 ) A N D ( e 1 < = e n g i n e p o w e r < = e 2 ) (p_1<=pricce<=p_2)AND(e_1<=engine \ power<=e_2) (p1<=pricce<=p2)AND(e1<=engine power<=e2)
确定类别的边界
-
矩形的集合H
-
特定的矩形 h ∈ H , h\in H, h∈H,最接近于理想的边界-矩形C.
-
机器学习的目标:将h分为1和0,判断是正例负例
-
经验误差:
- E ( h ∣ X ) = ∑ 1 ( h ( x t ) ! = r t ) E(h|X)=\sum1(h(x^t)!=r^t) E(h∣X)=∑1(h(xt)!=rt)
- l ( a ≠ b ) = { 1 a ≠ b 0 a = b l(a\neq b)=\left\{ \begin{matrix} 1\ a\neq b\\ 0\ a=b \end{matrix} \right. l(a=b)={1 a=b0 a=b
对假设类的评价
- 泛化效果好
- 找到了最好的矩形
- 最特殊的假设:泛化能力差,过拟合。
- 最一般的假设:欠拟合的假设,过于宽泛。
训练集相容
- 假设 h ∈ H h\in H h∈H在训练集S上零误差,则称h与训练集相容
(即 h h h能够完美拟合训练数据,但不一定能泛化到新数据)
-
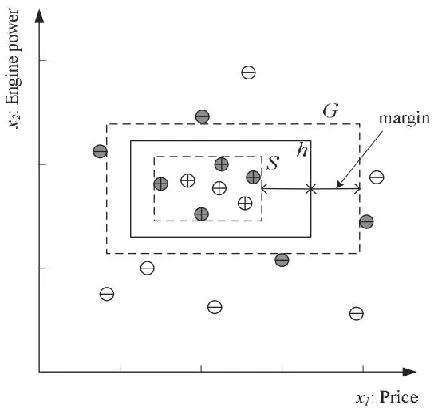
S:最特殊的假设
- 严格你和训练数据,可能过拟合。
-
G:最一般的假设
- 覆盖更广的范围,可能欠拟合。
-
在假设空间H中,S和G定义了泛化能力的边界(即假设的"最紧"和"最松"限制)
-
当训练集 X X X最够大时,可能收敛到唯一的S和G。
-
在许多实际问题中,S和G之间的实例(即假设的泛化程度)是不确定的,可以通过验证集调整。
VC维
定义:VC维是机器学习理论中用于衡量一个假设类容量的表示该假设类能够打散(shatter)的最大样本数量,反映了模型拟合复杂数据的能力。
- 打散(shatter)
- 给定一个假设类 H H H和一个包含n个样本的数据集D,如果H能对D的所有组合进行完美分类,则称H打散了D。
- VC维是假设类H能打散的最大样本数d。若H能打散任意大的数据集,称VC维为无穷大。
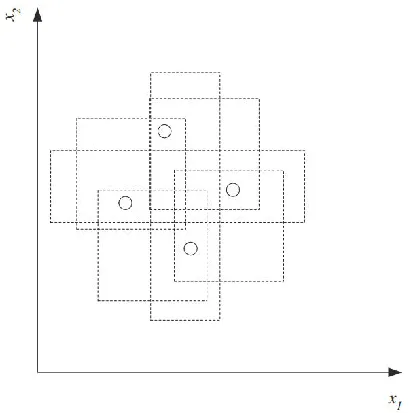
举例:二维空间四个点的情况
在二维平面中,用轴平行矩形最多能打散4个点。
线性分类器的VC维为3
-
较小维度的VC维也有其应用价值,可以应用于简单任务,泛化性好。
-
VC维越高,模型越复杂,需要避免过拟合。
多值分类
-
假设需要学习K个假设
h i ( x t ) = { 1 i f x t ∈ C i 0 i f x t ∈ C j , j ≠ i h_i(x^t)= \begin{cases} 1\quad if \ x^t\in C_i\\ 0\quad if \ x^t\in C_j, j\neq i \end{cases} hi(xt)={1if xt∈Ci0if xt∈Cj,j=i
-
计算多类的经验误差
E = ∑ t ∑ i 1 ( h i ( x t ) ≠ r i t ) E=\sum_t\sum_i1(h_i(x^t)\neq r_i^t) E=∑t∑i1(hi(xt)=rit)
其中,h为预测值,r为真实值。内层求和为遍历所有类别,外层求和遍历所有样本。
回归
-
布尔值→连续变化的数值
-
r t = f ( x t ) r^t=f(x^t) rt=f(xt)
-
寻找最小经验误差的学习模型 g ( x ) g(x) g(x)
E ( g ∣ X ) = 1 N ∑ r t − g ( x t ) 2 E(g|X)=\frac{1}{N}\sumr\^t-g(x\^t)^2 E(g∣X)=N1∑rt−g(xt)2
当前学习模型的损失函数
以开头的二手车为例:
y = w 1 x + w 0 y=w_1x+w_0 y=w1x+w0
通过最小二乘法可以计算拐点(极值点):
w 1 = w_1=\frac{}{} w1= ∑ t x t r t − x r ‾ N ∑ t ( x t ) 2 − N x ‾ 2 \frac{\sum_tx^tr^t-\overline{xr}N}{\sum_t(x^t)^2-N\overline{x}^2} ∑t(xt)2−Nx2∑txtrt−xrN
w 0 = r ‾ − w 1 x ‾ w_0=\overline{r}-w_1\overline{x} w0=r−w1x
噪声的影响
噪声的定义:错误样本
- 应对策略:
- 增加假设类复杂性
- 增大样本规模
- 简单模型的泛化能力强
- 奥卡姆剃刀:简单更可信。
学习模型的选择
- 布尔函数的输入
-
每个输入特征为二元值
-
d个样本的输入,有 2 d 2^d 2d种情况,对应 2 2 d 2^{2^d} 22d个函数。
-
举例:假设有两个特征 x 1 , x 2 x_1,x_2 x1,x2
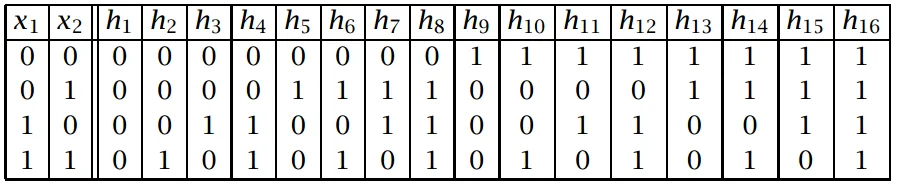
-
随着每个样本的输入,都会排除掉一半假设,为了得到单个假设,需要有 2 d 2^d 2d个样本,但指数级很难得到,因此实际情况,只能拿到的样本只是一个 2d 个样本的小子集。
-
不适定问题
- N个样本输入,存在 2 2 d 2^{2^d} 22d个可能的布尔函数无法确定,得不到唯一解。
- 因此大部分情况都是近似解。
归纳偏倚
现有数据量不足以找到唯一解,因此需要猜测或者假设。
为了使学习成为可能,所做的假设集合称为 归纳偏倚。
模型选择
- 在众多可能的假设类中选择正确的,通过泛化性判断性能。
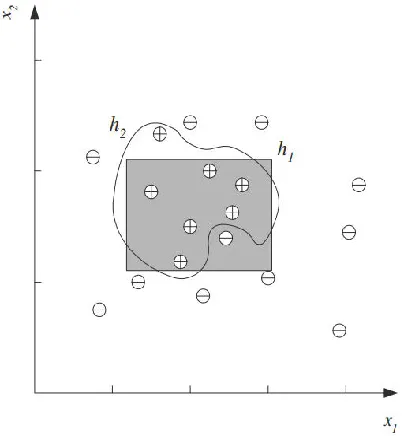
欠拟合
训练集表现差,验证集表现差。
- 提高模型复杂度
过拟合
训练集表现好,验证集表现差。
- 降低模型复杂度。
- 增加样本
模型规模与模型复杂性的关系
- 一般情况下,增大训练规模,预测误差会降低
- 随着模型复杂性的增加,预测误差先降低后增加
训练方法
- 将训练集的一部分抽取作为验证集。
- 交叉验证:最好的假设→于验证集上的精确。
- 模型的测试:设置测试集(也成为发布集)
- 测试集和它们不同:不参与训练。
常用术语
数据 :计算机处理和存储的信息。
样本 :从数据集抽取出来的一部分。
噪声:错误样本。
建模 :解决问题而建立的学习模型。
估计:确定机器学习模型参数的值。
学习和训练:在机器学习领域,这两个概念等价。
分类和回归分析:
- 分类的预测结果是离散的,状态数量有限。
- 回归分析的预测结果是连续的,状态数量无限。
有监督的学习 :训练样本带有类别信息。
无监督的学习 :数据样本没有类别信息,也没有先验的类别知识。
归纳学习:从大量的经验数据中归纳抽取出一般的判定规则和模式,是从特殊情况推导出一般规则的学习方法。
基于实例的学习 :从训练样本中找寻主导预测的内在规律。
拟合 :形象的说,拟合就是把平面上一系列的点,用一条光滑的曲线连接起来,后来这个概念被推广到分类模型的设计上。
欠拟合 underfitting:复杂性比潜在函数复杂性低的假设。
过拟合 overfitting :对于复杂性比潜在函数复杂性高的假设。
样本特征 :被观测的样本实例(instances)具有多个属性(d >=1),这些属性被称为特征。
多维空间:在此是指样本的属性。
泛化 :对未知数据做出准确预测,说它能够从训练集泛化(generalize)到测试集。
交叉检验和测试:
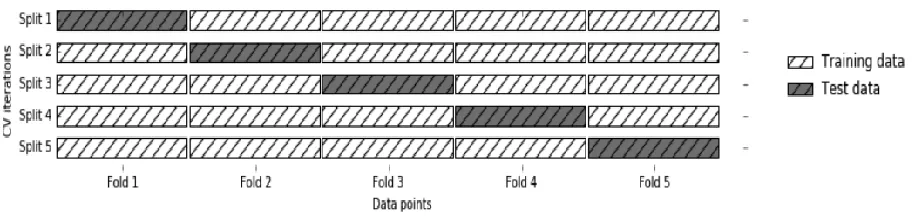
模型评价的指标:
- 精确率(Precision)、召回率(Recall)和 F1(F-Measure)值常被放在一起作比较
- TP(True Positive):本来是正样本,被模型预测为正样本。
- TN(True Negative):本来是负样本,被模型预测为负样本。
- FP(False Positive):本来是负样本,被模型预测为正样本。
- FN(False Negative):本来是正样本,被模型预测为负样本。
**偏差:**bias是指预测值对真值的偏离,欠拟合也称为高偏差(high bias)。
**方差:**统计中的方差是每个样本值与全体样本值的平均数之差的平方值的平均数。
**预测风险:对事件发生所造成的损失作出定量估计 。
损失函数:**取值映射为非负实数以表示该随机事件的"风险"或"损失"的函数数据。
机器学习关键环节
- 学习的样本集**:**
- 样本遵循独立同分布
- **目标:**找到一个拟合函数。
- 三个环节:
- 选定学习模型。
- 确定损失函数。
- 最优化过程。
- 机器学习的条件
- 假设类的容量足够大
- 足够多的训练数据
- 好的优化方法
- 不同机器学习方法的区别
- 模型不同
- 损失函数不同
- 最优化过程不同
模型选择
- 考虑机器学习算法的目的
- 如果要预测目标变量的值,优先有监督学习法
- 否则可以选择无监督学习法
- 确定目标变量类型
- 离散型:分类算法
- 连续性:回归算法
- 如果不想预测目标变量的值,采用非监督学习算法
- 需要将数据划分为离散的组, 则使用聚类算法
- 需要估计数据与每个分组的相似程度, 则需要使用密度估计算法
机器学习应用开发经典步骤
- 数据采集和标记
- 数据清洗
- 特征选择
- 模型选择
- 模型训练和测试
- 模型性能评估和优化
- 模型使用