FiLo++框架图模块详解
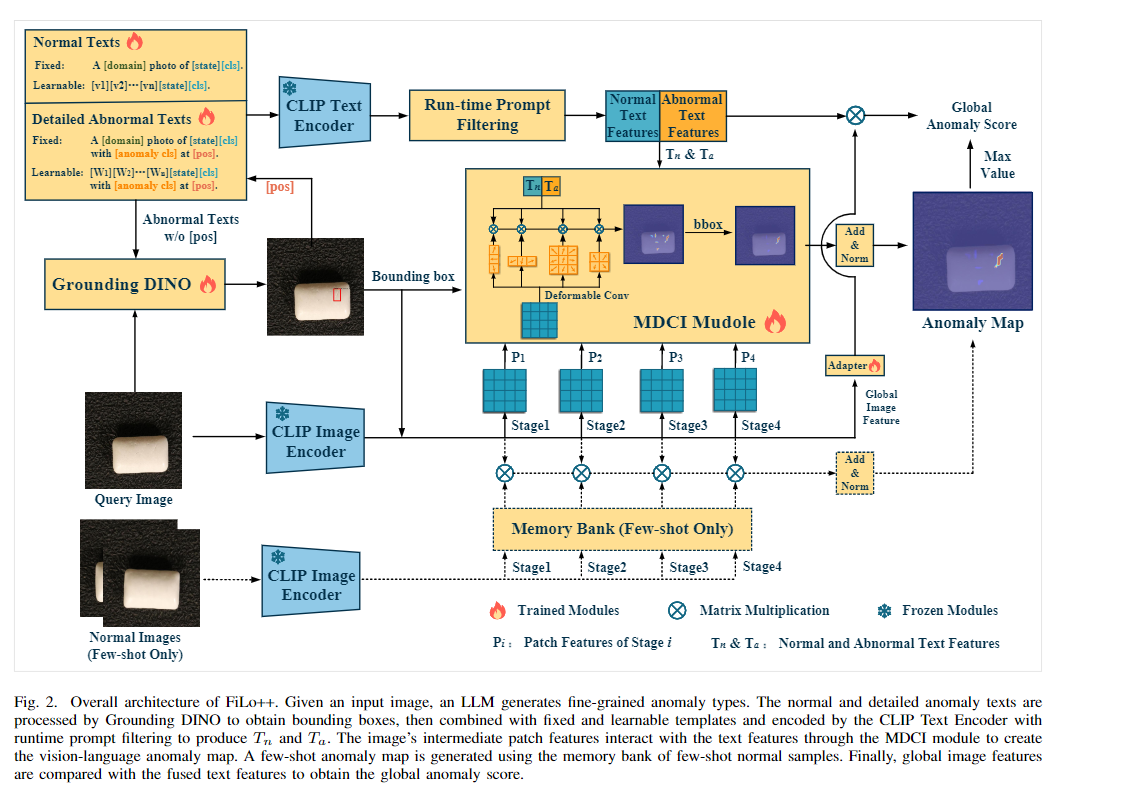
1. 文本生成模块
-
Normal Texts
- 功能 :生成正常样本的文本描述。
- 输入 :固定模板(如
A [domain] photo of [state][cls])和可学习模板(如[v1][v2]...[vm][state][cls])。 - 输出:融合后的正常文本提示(例如 "A industrial photo of normal metal nut")。
- 传递路径 :输入到 CLIP Text Encoder,生成正常文本特征((T_n))。
-
Detailed Abnormal Texts
- 功能 :生成细粒度异常描述,包含异常类型和位置信息。
- 输入 :固定模板(如
A [domain] photo of [state][cls] with [anomaly cls] at [pos])和可学习模板(如[W1][W2]...[W4][state][cls])。 - 输出:异常文本提示(例如 "A industrial photo of anomalous metal nut with crack at top-right")。
- 传递路径 :输入到 CLIP Text Encoder,生成异常文本特征((T_a))。
2. 图像处理模块
-
Query Image
- 功能:待检测的输入图像。
- 输入:原始图像数据。
- 输出 :图像经过 CLIP Image Encoder 提取多阶段补丁特征((P_1, P_2, P_3, P_4))。
-
Normal Images (Few-shot Only)
- 功能:少样本场景下的正常参考图像。
- 输入:少量正常样本图像。
- 输出 :通过 CLIP Image Encoder 提取补丁特征,存入 Memory Bank。
3. 文本编码与过滤模块
-
CLIP Text Encoder
- 功能:将文本提示编码为特征向量。
- 输入:正常和异常文本提示。
- 输出:文本特征 (T_n)(正常)和 (T_a)(异常)。
-
Run-time Prompt Filtering
- 功能:过滤语义重叠的文本特征,提升正常/异常特征区分度。
- 输入:原始文本特征 (T_n) 和 (T_a)。
- 输出:过滤后的高区分度特征 (T'_n) 和 (T'_a)。
4. 初步定位模块
- Grounding DINO
- 功能:基于文本描述初步定位潜在异常区域。
- 输入:Query Image 和异常文本描述。
- 输出:异常区域边界框(Bounding Box),用于后续特征匹配范围约束。
5. 多尺度交互模块
-
Deformable Conv (MDCI)
- 功能:通过可变形卷积聚合多尺度图像特征,适应不同形状/大小的异常区域。
- 输入:多阶段补丁特征 (P_1-P_4)。
- 输出:跨模态对齐后的异常热力图 (M^{vl})。
-
Stage1-Stage4
- 功能:分层提取图像补丁特征(不同层级的语义信息)。
- 输入:原始图像。
- 输出:各阶段的补丁特征 (P_1, P_2, P_3, P_4)(分辨率递减,语义增强)。
6. 特征对齐与融合模块
-
Adapter
- 功能:调整全局图像特征,增强与文本特征的相似度计算。
- 输入:CLIP Image Encoder 的全局特征 (G)。
- 输出:适配后的全局特征 (G')。
-
Memory Bank (Few-shot Only)
- 功能:存储少样本正常图像的补丁特征。
- 输入:正常参考图像的补丁特征。
- 输出:用于与查询图像的补丁特征进行匹配,生成少样本异常热力图 (M^{few})。
7. 异常分数计算模块
-
Matrix Multiplication
- 功能:计算图像特征与文本特征的相似度。
- 输入:适配后的全局特征 (G') 和过滤后的文本特征 (T'_n, T'_a)。
- 输出:全局异常分数 (S_{global})(图像级检测结果)。
-
Global Anomaly Score
- 功能:融合全局分数与局部热力图,生成最终异常分数。
- 输入 :(S_{global}) 和 (M{vl})(跨模态热力图)、(M{few})(少样本热力图)。
- 输出:图像级和像素级异常检测结果。
核心流程总结
- 文本生成:通过固定模板和LLM生成细粒度文本提示。
- 特征提取:CLIP编码器分别处理文本和图像,生成多模态特征。
- 初步定位:Grounding DINO过滤背景,缩小检测范围。
- 多尺度交互:MDCI模块融合多阶段图像特征与文本特征,生成异常热力图。
- 少样本融合:Memory Bank存储正常样本特征,通过补丁匹配增强定位精度。
- 分数计算:全局与局部特征融合,输出最终检测结果。
创新点:
- 细粒度文本描述(LLM生成异常类型与位置)提升可解释性。
- 多尺度可变形卷积(MDCI)适应复杂异常形态。
- 少样本定位增强(Memory Bank + 位置约束)减少误检。