1.朴素贝叶斯算法
1.1基本概念
其分类原理是利用贝叶斯公式根据某特征的先验概率计算出其后验概率,然后选择具有最大后验概率作为该特征所属的类。之所以称之为"朴素",是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是相对独立的。
其核心思想是通过考虑各个特征的概率来预测分类(即对于给出的待分类样本,计算该样本在每个类别下出现的概率,最大的就被认为是该分类样本所属于的类别
朴素贝叶斯被广泛地应用在文本分类 、垃圾邮件过滤 、情感分析等场合
1.2朴素贝叶斯的优缺点
优点:
具有稳定的分类效率
在数据较少时仍然有效,可以处理多类别的问题
对缺失数据不太敏感
进行分类时对时间和空间的开销都比较小
缺点:
对于输入数据的准备方式比较敏感,需要对数据进行适当的预处理
需要假设属性之间相互独立,这在实际情况中往往不太现实
需要知道先验概率,但是由于先验概率大多取决于假设,故很容易因此导致预测效果不佳
1.3 朴素贝叶斯的一般过程
准备数据:收集并预处理数据,将数据分为特征和标签
特征选择:选择对分类有帮助的特征
模型训练:使用训练数据计算每个类别的先验概率和条件概率
预测:对新数据进行分类,选择概率最大的类别作为预测结果
2.算法实现
先验概率
P (c j )代表还没有训练模型之前,根据历史数据/经验估算c j 拥有的初始概率。P (c j )常被称为c j 的先验概率(prior probability) ,它反映了c j 的概率分布,该分布独立于样本。通常可以用样例中属于c j 的样例数|c j |比上总样例数|D|来近似,即:
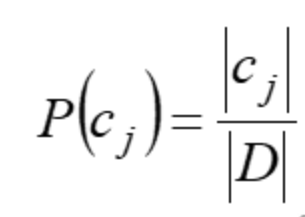
后验概率
给定数据样本x 时c j 成立的概率P (c j | x )被称为后验概率(posterior probability),因为它反映了在看到数据样本 x 后 c j 成立的置信度。
注:大部分机器学习模型尝试得到后验概率
贝叶斯定理
朴素贝叶斯算法的核心是贝叶斯公式,公式如下:
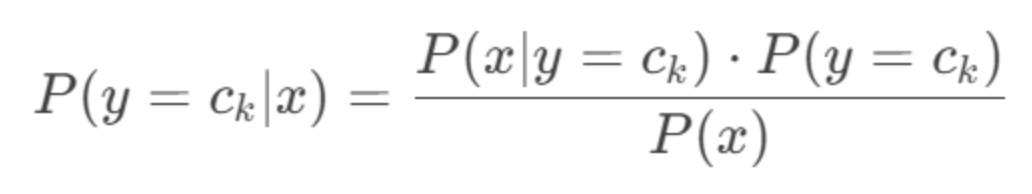
条件独立性假设
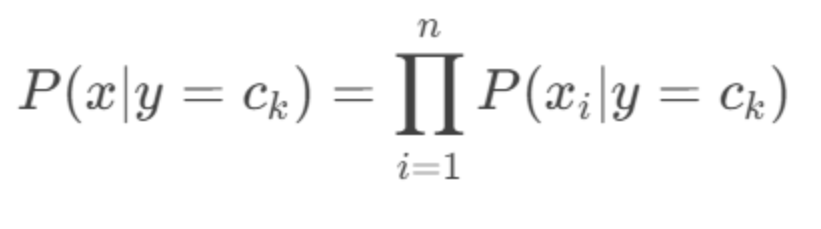
最终选择使后验概率最大的类别:
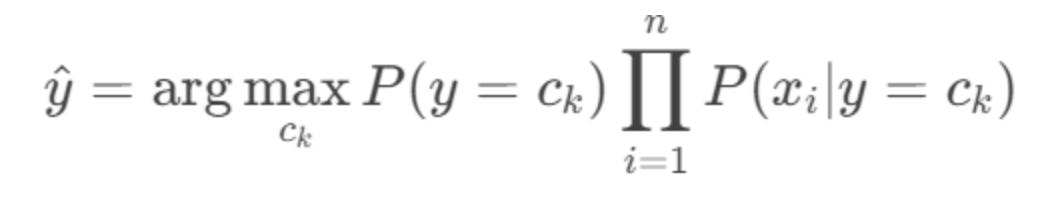
计算步骤
接下来我们通过一个例子来说明计算步骤
判断是否能够PlayTennis
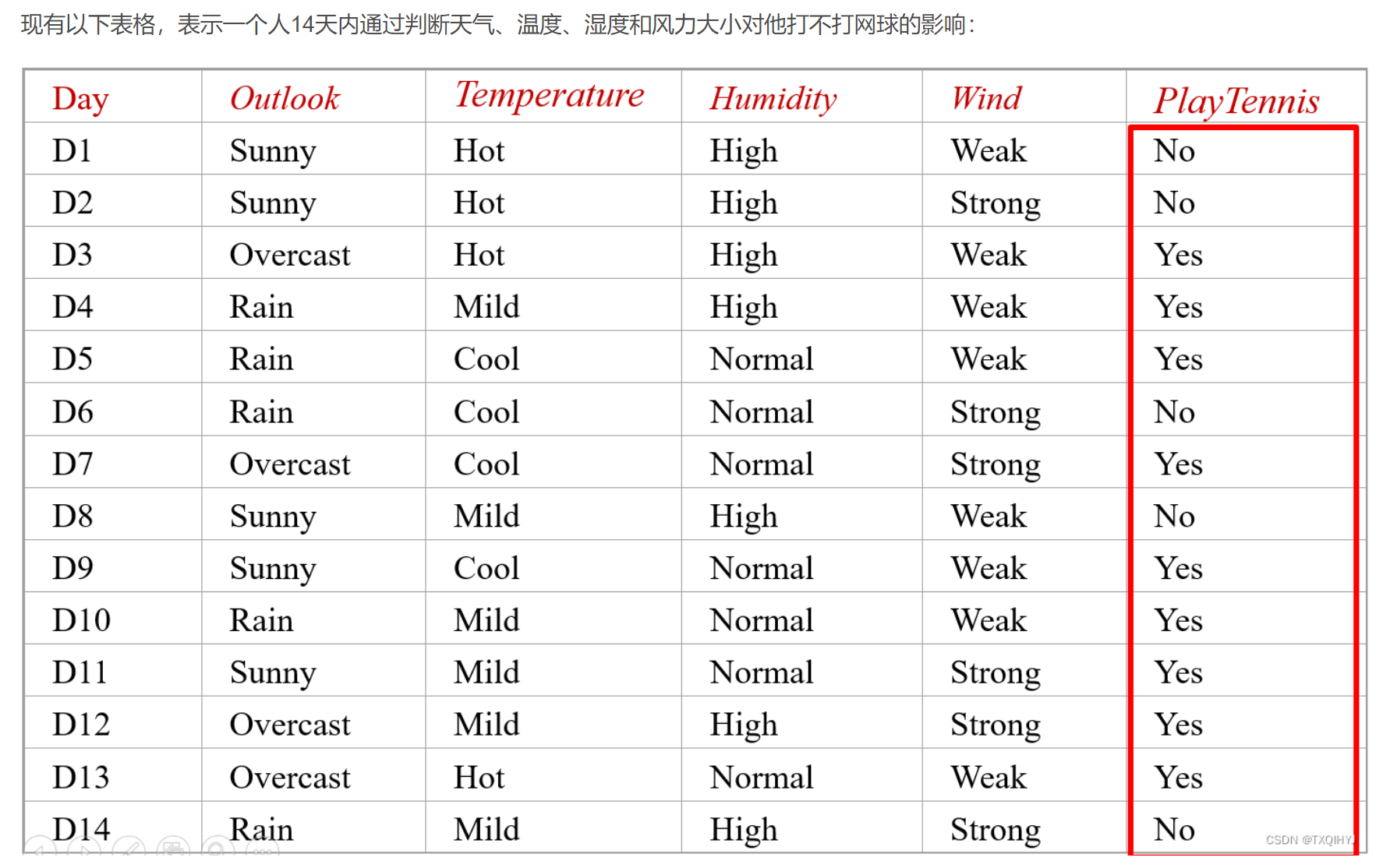
我们需要通过已有数据计算出,如果给出一个天气情况,这个人去不去打网球。
如
现在假设有一个样例 x
x = {Sunny, Hot, High,Weak}
它应该属于类别Yes?No?
1.统计个计算先验概率
统计在各个条件下出去Yes和No的天数

统计各个特征出现的次数
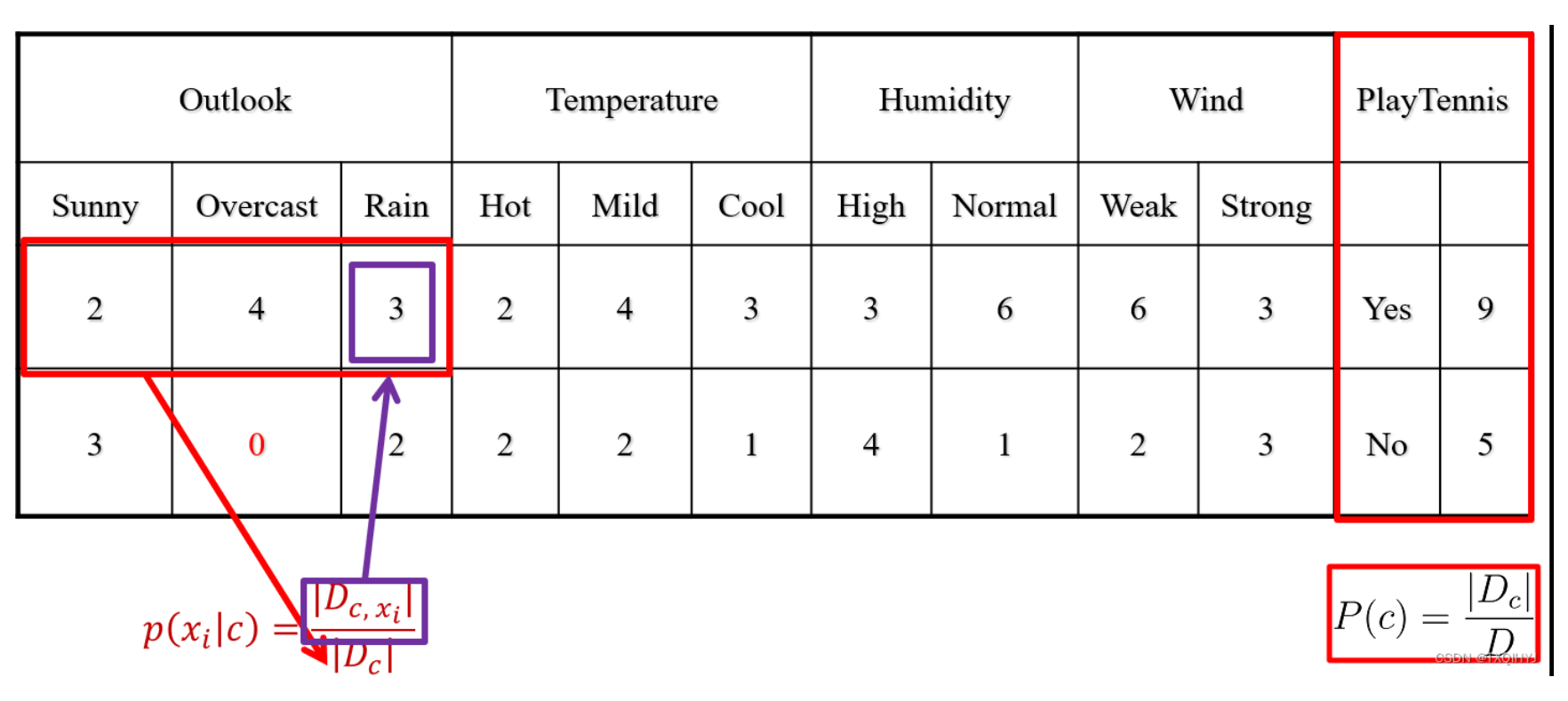
2.计算条件概率
计算在Yes和No的条件下各个特征出现的概率
离散特征:

连续特征(假设服从高斯分布):

对于多个特征:
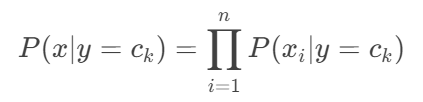
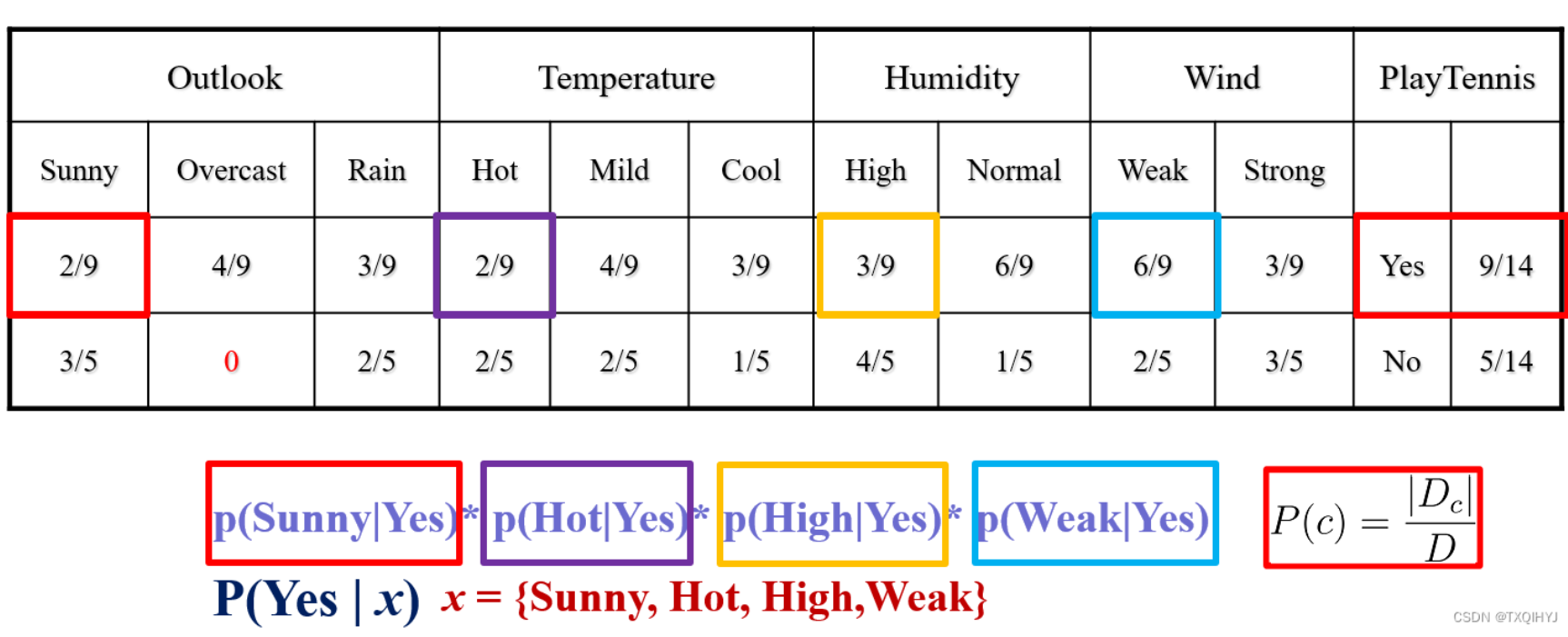
3.计算在已知该特征下Yes和No发生的条件概率
现在 假设有一个样例 x
x = {Sunny, Hot, High,Weak}
Y es的概率 P(Yes | x )
∝ p(Yes)*p(Sunny|Yes)* p(Hot|Yes)* p(High|Yes)* p(Weak|Yes)
=9/14*2/9*2/9*3/9*6/9
=0.007039
No的概率 P(No | x )
∝ p(No)*p(Sunny| No)* p(Hot| No)* p(High| No)* p(Weak| No)
=5/14*3/5*2/5*4/5*2/5
=0.027418
max (P(Yes| x ), P(No| x ) ) = P(No| x ) 所以可以把 x 分类为No
拉普拉斯修正
避免零概率事件,适用于离散特征
若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如"敲声=清脆"测试例,训练集中没有该样例,因此连乘式计算的概率值为0,无论其他属性上明显像好瓜,分类结果都是"好瓜=否",这显然不合理。
为了避免其他属性携带的信息,被训练集中未出现的属性值"抹去",在估计概率值时通常要进行"拉普拉斯修正":
令 N 表示训练集 D 中可能的类别数,𝑁𝑖N_i表示第i个属性可能的取值数,则贝叶斯公式可修正为:


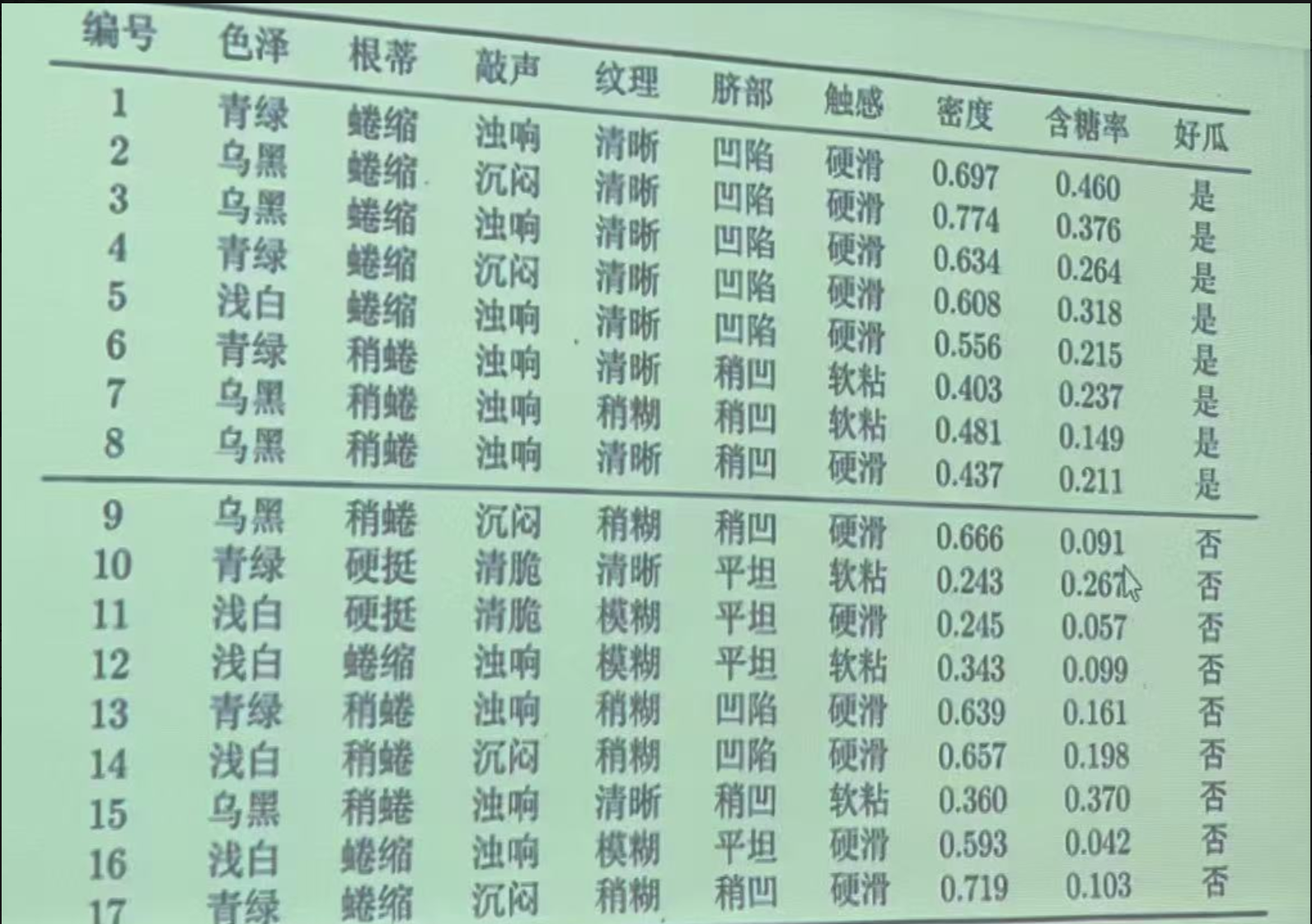
3.实例:判断西瓜好坏
训练集:
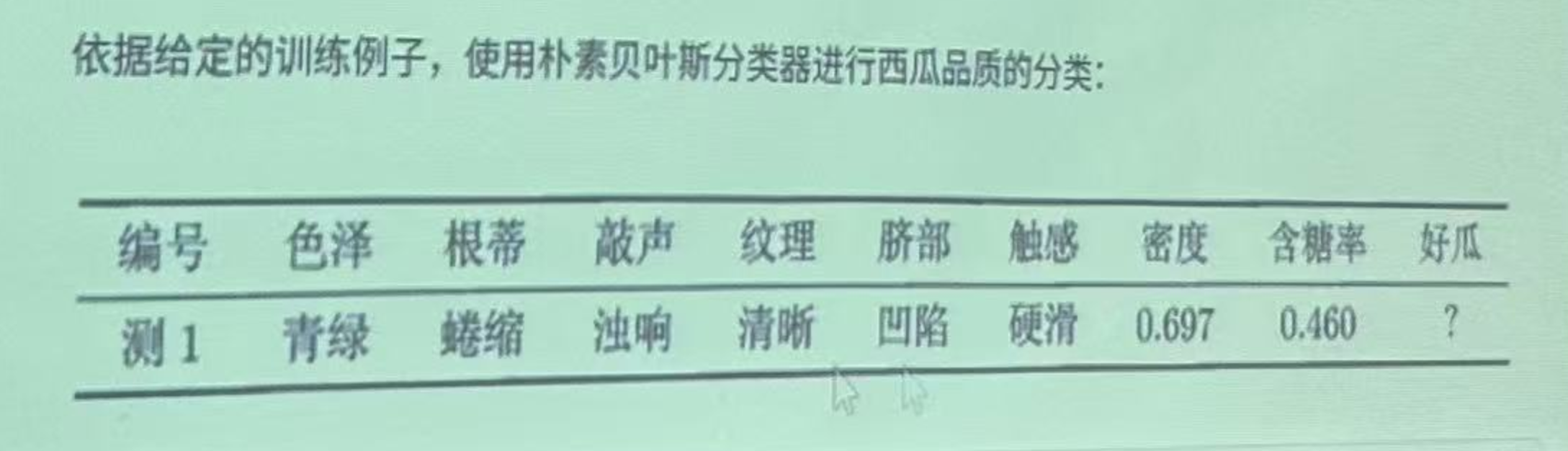
待测样本
代码实现:
data_preprocessing.py该文件封装了数据预处理的逻辑,包括数据读取、特征编码和数据划分等操作,最后返回处理好的训练数据、测试数据和标签编码器。
python
import pandas as pd
from sklearn.preprocessing import LabelEncoder
def preprocess_data():
# 假设从第一张图训练集读取数据到DataFrame
train_data = pd.DataFrame({
'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿', '浅白', '浅白', '青绿', '浅白', '乌黑', '浅白', '青绿'],
'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺', '硬挺', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '蜷缩', '蜷缩'],
'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '浊响', '沉闷', '清脆', '清脆', '浊响', '浊响', '沉闷', '浊响', '浊响', '沉闷'],
'纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '清晰', '稍糊', '清晰', '模糊', '模糊', '稍糊', '稍糊', '清晰', '模糊', '稍糊'],
'脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦', '平坦', '平坦', '凹陷', '凹陷', '稍凹', '平坦', '稍凹'],
'触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '硬滑'],
'密度': [0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437, 0.666, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360, 0.593, 0.719],
'含糖率': [0.460, 0.376, 0.264,0.318, 0.215, 0.237, 0.149, 0.211, 0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370, 0.042, 0.103],
'好瓜': ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']
})
# 假设第二张图预测样本读取到DataFrame
test_data = pd.DataFrame({
'色泽': ['青绿'],
'根蒂': ['蜷缩'],
'敲声': ['浊响'],
'纹理': ['清晰'],
'脐部': ['凹陷'],
'触感': ['硬滑'],
'密度': [0.697],
'含糖率': [0.460]
})
# 对类别型特征进行编码
label_encoders = {}
for col in ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']:
le = LabelEncoder()
train_data[col] = le.fit_transform(train_data[col])
label_encoders[col] = le
if col in test_data.columns:
test_data[col] = label_encoders[col].transform(test_data[col])
# 提取特征和标签
X = train_data.drop('好瓜', axis=1)
y = train_data['好瓜']
test_sample = test_data
return X, y, test_sample, label_encoders作为主程序文件,调用data_preprocessing.py中的preprocess_data函数获取预处理后的数据,再调用model_training_and_prediction.py中的train_and_predict函数完成模型训练和预测任务。
python
from data_preprocessing import preprocess_data
from model_training_and_prediction import train_and_predict
if __name__ == "__main__":
X, y, test_sample, label_encoders = preprocess_data()
train_and_predict(X, y, test_sample, label_encoders) model_training_and_prediction.py此文件负责模型的训练和预测工作,接收预处理后的数据和标签编码器,创建高斯朴素贝叶斯分类器,进行训练和预测,并将预测结果解码输出。
python
from sklearn.naive_bayes import GaussianNB
def train_and_predict(X, y, test_sample, label_encoders):
# 创建高斯朴素贝叶斯分类器
clf = GaussianNB()
# 训练模型
clf.fit(X, y)
# 预测
prediction = clf.predict(test_sample)
# 解码预测结果
predicted_class = label_encoders['好瓜'].inverse_transform(prediction)
print("预测结果:", predicted_class[0])运行结果:
