Vim技巧
- [一、按 按模 模式 式匹 匹配 配及 及按 按原 原义 义匹 匹配](#一、按 按模 模式 式匹 匹配 配及 及按 按原 原义 义匹 匹配)
-
- 1.1、调整查找模式的大小写敏感性
- [1.2、按正则表达式查找时,使用 \v 模式开关](#1.2、按正则表达式查找时,使用 \v 模式开关)
- [1.3、按原义查找文本时,使用 \V 原义开关](#1.3、按原义查找文本时,使用 \V 原义开关)
- 1.4、使用圆括号捕获子匹配
- 1.5、界定单词的边界
- 1.6、界定匹配的边界
- 二、查找
- 三、替换
-
- [3.1、substitute 命令](#3.1、substitute 命令)
- 3.2、在文件范围内查找并替换每一处匹配
- 3.3、手动控制每一次替换操作
- 3.4、用寄存器的内容替换
- [3.5、重复上一次 substitute 命令](#3.5、重复上一次 substitute 命令)
- [3.6、使用子匹配重排 CSV 文件的字段](#3.6、使用子匹配重排 CSV 文件的字段)
- 3.7、在替换过程中执行算术运算
- 四、global命令
一、按 按模 模式 式匹 匹配 配及 及按 按原 原义 义匹 匹配
1.1、调整查找模式的大小写敏感性
全局设置大小写敏感性:
bash
set ignorecase每次查找时设置大小写敏感性:
通过使用元字符 \c 与 \C, 可以覆盖 Vim 缺省的大小写敏感性设置。 小写字母 \c会让查找模式忽略大小写,而大写字母 \C 则会强制区分大小写。若在某个查找模式中使用了两者中的某一个,'ignorecase'的值将被这次查找忽略。
启用更具智能的大小写敏感性设置:
Vim 提供了一项额外设置,用于最大限度地推测我们是想用大写还是小写,这就是'smartcase'选项。
bash
set smartcase该选项被启用后,无论何时,只要我们在查找模式中输入了大写字母,'ignorecase'设置就不再生效了。换句话说,如果我们的模式全是由小写字母组成的,就会按照忽略大小写的方式进行查找,但只要我们输入一个大写字母,查找方式就会变成区分大小写的了。
总结:
| 模式 | 'ignorecase' | 'smartcase' | 匹配 |
|---|---|---|---|
| foo | off | - | foo |
| foo | on | - | foo Foo FOO |
| foo | on | on | foo Foo FOO |
| Foo | on | on | Foo |
| Foo | on | off | foo Foo FOO |
| \cfoo | - | - | foo Foo FOO |
| foo\C | - | - | foo |
1.2、按正则表达式查找时,使用 \v 模式开关
假设我们要构造一个正则表达式, 用于匹配以下 CSS 片段中的每一组颜色代码:
css
body { color: #3c3c3c; }
a { color: #0000EE; }
strong { color: #000; }我们需要匹配 1 个 # 字符以及紧随其后的 3 个或 6 个十六进制字符 (包括所有数字以及大写或小写的字母 A 到 F) 。
可以利用 \v 模式开关来统一所有特殊符号的规则。该元字符将会激活 verymagic搜索模式,即假定除、大小写字母以及数字 0 到 9 之外的所有字符都具有特殊含义。
bash
# 正则
/#\([0-9a-fA-F]\{6}\|[0-9a-fA-F]\{3}\)
# 由于出现在起始位置的 \v 开关,位于它后面的所有字符都具有特殊含义,那些反斜杠字符就可以去掉了
/\v#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})1.3、按原义查找文本时,使用 \V 原义开关
The N key searches backward...
...the \v pattern switch (a.k.a. very magic search)...假设我们想通过查找"a.k.a." (此缩写表示 also known as)的方式将光标移到该处。针对这种情况,第一反应就是执行以下这条查找命令:
bash
/a.k.a.但当我们按下回车键时,会发现此模式所匹配的内容比我们预想得要多。这是因为,符号"."具有特殊含义。它匹配任意字符,而单词"backward"的部分内容又恰好可以匹配该模式。
可以使用原义开关 \V,激活 very nomagic搜索模式:
bash
/\Va.k.a.1.4、使用圆括号捕获子匹配
I love Paris in the
the springtime.上文中the the重复了,需要匹配出来:
/\v<(\w+)\_s+\1>1.5、界定单词的边界
the problem with these new recruits is that
they don't keep their boots clean.有些单词,尤其是短词,常常出现在其他单词内部。比如, "the"就会在"these"、"they"、"their"等单词中出现。因此,如果我们在下面这段文本中执行 /the<CR> 进行查找的话,会发现实际匹配的内容比我们预想得要多。

如果我们想明确匹配"the"这个完整的单词而不是其他词的组成部分,可以使用单词定界符。在 very magic 搜索模式下,用 <与> 符号表示单词定界符。因此,如果我们将查找命令改为 /\v<the><CR> 的话,文中就只会出现一处匹配了。

1.6、界定匹配的边界
有时候,我们可能想指定一个范围较广的模式,但只对匹配结果的一部分感兴趣。Vim 中的元字符 \zs与 \ze可以帮助我们处理这种情况。
元字符 \zs标志着一个匹配的起始,而元字符 \ze则用来界定匹配的结束。将二者相结合,我们可以定义一个特殊的模式,它们可以让我们定义一个模式匹配一个较大的文本范围,然后再收窄匹配范围。
| 按键操作 | 缓冲区内容 |
|---|---|
{start} |
 |
/\v"[^"]+"<CR> |
 |
/\v"\zs[^"]+\ze"<CR> |
 |
注意:尽管引号被排除在匹配之外,但它们仍然是模式中的关键部分。
二、查找
2.1、相关命令
| 命令 | 用途 |
|---|---|
/ |
执行查找 |
n |
跳至下一处匹配,保持查找方向与偏移不变 |
N |
跳至上一处匹配,保持查找方向与偏移不变 |
/<CR> |
正向跳转至相同模式的下一处匹配 |
?<CR> |
反向跳转至相同模式的上一处匹配 |
2.2、统计当前模式的匹配个数
虽然没有任何方法可以让查找命令统计当前文档中的匹配个数,但是用下面这条命令就可以做到这一点:
bash
:%s///gn实际上,我们调用的是 :substitute命令,但标志位 n会抑制正常的替换动作。该命令不会对每处匹配进行替换,而是简单地统计匹配的次数,并将结果显示到命令行上。此处我们将查找域留空,旨在让 Vim 使用当前的查找模式。替换域(由于标志位 n的缘故)不管怎样都将会被忽略,因此也可以将其留空。
2.3、对完整的查找匹配进行操作
rb
class XhtmlDocument < XmlDocument; end
class XhtmlTag < XmlTag; end假设想把它们改成下面这样:
rb
class XHTMLDocument < XMLDocument; end
class XHTMLTag < XMLTag; end| 按键操作 | 缓冲区内容 |
|---|---|
{start} |
 |
/\vX(ht)?ml\C<CR> |
 |
gU//e<CR> |
 |
//<CR> |
 |
. |
 |
//<CR>. |
 |
//<CR>. |
 |
三、替换
3.1、substitute 命令
语法:
bash
:[range]s[ubstitute]/{pattern}/{string}/[flags]标志位:
g使得 subsititute 命令可在全局范围内执行c让我们有机会可以确认或拒绝每一处修改n会抑制正常的替换行为,即让 Vim 不执行替换操作&仅仅用于指示 Vim 重用上一次 substitute 命令所用过的标志位
替换域中的特殊字符:
通过查询 :h sub-replace-special ,你可以找到完整的列表,
下表只是总结了其中的一部分常用符号:
| 符号 | 描述 |
|---|---|
\r |
插入一个换行符 |
\t |
插入一个制表符 |
\\ |
插入一个反斜杠 |
\1 |
插入第 1个子匹配 |
\2 |
插入第 2个子匹配(以此类推,最多到 \9) |
\0 |
插入匹配模式的所有内容 |
& |
插入匹配模式的所有内容 |
~ |
使用上一次调用 :substitute时的 {string} |
\={Vim script} |
执行 {Vim Script} 表达式;并将返回的结果作为替换 {string} |
3.2、在文件范围内查找并替换每一处匹配
When the going gets tough, the tough get going.
If you are going through hell, keep going.将所有单词 going 替换为 rolling:
bash
# 替换当前行第一个
:s/going/rolling
# 替换当前行所有
:s/going/rolling/g
# 全文替换
:%s/going/rolling/g 3.3、手动控制每一次替换操作
...We're waiting for content before the site can go live...
...If you are content with this, let's go ahead with it...
...We'll launch as soon as we have the content..."content"到"copy":
bash
:%s/content/copy/gcVim提示选项:
| 答案 | 用途 |
|---|---|
y |
替换此处匹配 |
n |
忽略此处匹配 |
q |
退出替换过程 |
l |
"last" ------ 替换此处匹配后退出 |
a |
"all" ------ 替换此处与之后所有的匹配 |
<C-e> |
向上滚动屏幕 |
<C-y> |
向下滚动屏幕 |
3.4、用寄存器的内容替换
实际上,我们不必手动输入完整的替换字符串。如果某段文本已在当前文档中出现,我们可以先把它复制到寄存器,再通过传值或引用的方式将寄存器的内容应用至替换域。
传值:
通过输入 <C-r>{register}, 我们可以将寄存器的内容插入到命令行。 假设我们已经复制了一些文本,如果要将它们粘贴到 substitute 命令的替换域,需要输入以下命令:
bash
:%s//<C-r>0/g当我们输入 0 时,Vim 会把寄存器 0 的内容粘贴进来,这意味着我们可以在执行 substitute 命令之前对其进行一番检查。在大多数情况下,它工作得都很好,但也引入了新的问题。
如果寄存器 0 中的文本包含了在替换域中具有特殊含义的字符(例如 & 或~) ,我们必须手动编辑这段文本,对这些字符进行转义。另外,如果寄存器 0 包含多行文本,有可能在命令行上显示不全。
为了避免这些问题,我们可以在替换域中简单地引用某个寄存器,从而得到该寄存器的内容。
引用:
假设我们已经复制了多行文本,并存放于寄存器 0 中。我们现在的目标是在substitute 命令的替换域中使用这段文本。通过运行以下命令,可以做到这一点:
bash
:%s//\=@0/g替换域中出现的 \= 将指示 Vim 执行一段表达式脚本。在 Vim 脚本中,我们可以用 @{register} 来引用某个寄存器的内容。具体来说,@0 会返回复制专用寄存器的内容,而 @" 则返回无名寄存器的内容。因此,表达式 :%s//\=@0/g 表示 Vim 将会用复制专用寄存器的内容替换上一次的模式。
3.5、重复上一次 substitute 命令
有的时候,我们可能要修正 substitute 命令的执行范围。原因多种多样,有可能是由于在第一次尝试运行 substitute 命令时犯了错,也有可能是我们想在另一个缓冲区中再次运行相同的命令。我们可以利用一些快捷方式更容易地重复 substitute 命令。
在整个文件范围内重复面向行的替换操作:
假设我们刚刚执行完以下命令(其作用范围为当前行) :
bash
:s/target/replacement/g突然,我们意识到了失误,应该加上前缀 % 才对。幸好该命令没有造成什么不良后果。
接下来,我们只需输入 g& ,即可在整个文件的范围内重复这条命令。在效果上,它等同于以下命令:
bash
:%s//~/&修正 substitute 命令的执行范围:
js
mixin = {
applyName: function(config) {
return Factory(config, this.getName());
},
}假设我们想把它扩展成以下模样:
bash
mixin = {
applyName: function(config) {
return Factory(config, this.getName());
},
applyNumber: function(config) {
return Factory(config, this.getNumber());
},
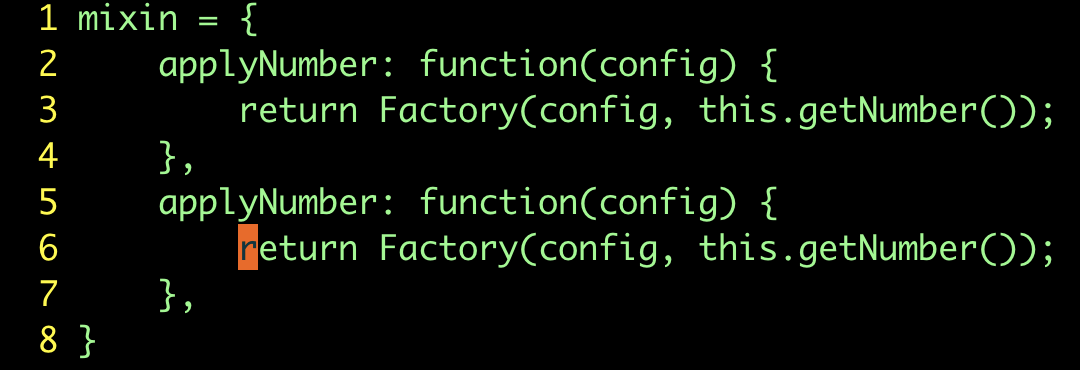
}采用符号 % 作为范围值,从而导致每一处"Name"都被改成了"Number" 。这样做显然不对,我们应该指定一个范围,限定
substitute 命令只作用于第二个函数(副本)中的那几行文本才对。
错误用法:
| 按键操作 | 缓冲区内容 |
|---|---|
{start} |
 |
Vjj |
 |
yP |
 |
:%s/Name/Number/g |
 |
重新指定范围:
| 按键操作 | 缓冲区内容 |
|---|---|
u |
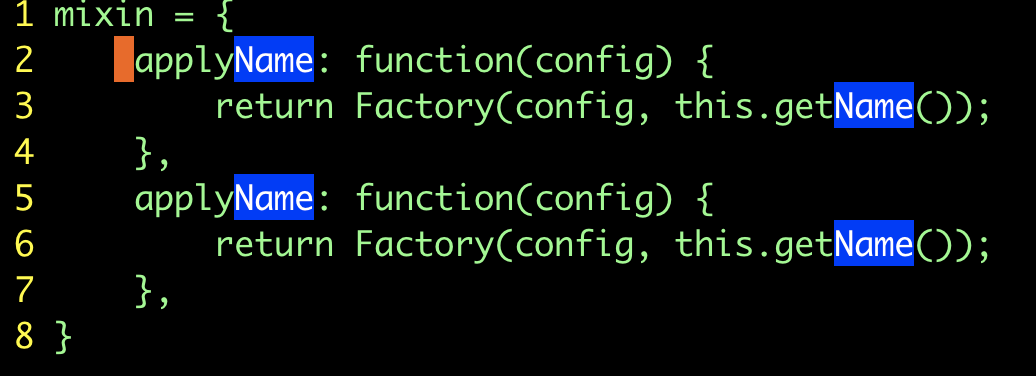 |
gv |
 |
:'<,'>&& |
 |
&& 命令,因为这两处 & 符号的含义有所不同。前一
个 & 作为 Ex 命令 :& 的组成部分, 用作重复上一次的 :substitute命令 ,而第二个 & 则会重用上一次 :s命令的标志位。
3.6、使用子匹配重排 CSV 文件的字段
假设有一个 CSV 格式的文件,其中包含了一份含有电子邮箱地址以及姓名的列表。
last name,first name,email
neil,drew,drew@vimcasts.org
doe,john,john@example.com现在假设我们想交换这些字段的次序,即把电子邮箱放到首列,其次是名字,最后一列为姓氏。通过使用以下 substitute 命令,我们可以做到这一点:
bash
/\v^([^,]*),([^,]*),([^,]*)$
:%s//\3,\2,\13.7、在替换过程中执行算术运算
换域中的内容不一定非得是简单的字符串。 我们可以执行一段 Vim 脚本表达式,然后用其结果充当替换字符串使用。具体到本节而言,仅凭一条 substitute 命令,我们就可以提升文档中每一级 HTML 标题标签的层级。
html
<h2>Heading number 1</h2>
<h3>Number 2 heading</h3>
<h4>Another heading</h4>我们的目标是提升每一处标题的层级,将 <h2> 变为 <h1>,<h3> 变为 <h2>,以此类推。换言之,我们要将现有的 HTML 标题标签中的数字部分减 1。
bash
# 匹配紧跟在 <h或者 </h之后的数字
/\v\<\/?h\zs\d
# 替换
:%s//\=submatch(0)-1/g四、global命令
4.1、基本语法
bash
:[range] global[!] /{pattern}/ [cmd]- 首先,在缺省情况下,:global命令的作用范围是整个文件(%) ,这一点与其他大多数 Ex 命令(包括:delete、:substitute 以及 :normal)有所不同,这些命令的缺省范围仅为当前行(.) 。
- 其次,{pattern} 域与查找历史相互关联。这意味着如果将该域留空的话,Vim会自动使用当前的查找模式。
- 另外,cmd 可以是除 :global命令之外的任何 Ex 命令。
- 可以用
:global!或者:vglobal(v 表示 invert)反转 :global 命令的行为。两条命令将指示 Vim 在没有匹配到指定模式的行上执行 cmd。
4.2、删除所有包含模式的文本行
html
<ol>
<li>
<a href="/episodes/show-invisibles/">
Show invisibles
</a>
</li>
<li>
<a href="/episodes/tabs-and-spaces/">
Tabs and Spaces
</a>
</li>
<li>
<a href="/episodes/whitespace-preferences-and-filetypes/">
Whitespace preferences and filetypes
</a>
</li>
</ol>显而易见,所有列表项均由两部分数据构成:主题的标题及其 URL。接下来,我们将利用一条 :global命令分别取出这两组数据。
用 :g/re/d 删除所有的匹配行:
果我们只想保留 <a> 标签内的标题, 而把其他行删掉:
bash
/\v\<\/?\w+>
:g//d

用 :v/re/d 只保留匹配行:
bash
# 删除所有不包含 href的文本行
:v/href/d
4.3、将匹配项收集到寄存器
js
Markdown.dialects.Gruber = {
lists: function() {
// TODO: Cache this regexp for certain depths.
function regex_for_depth(depth) { /* implementation */ }
},
"`": function inlineCode( text ) {
var m = text.match( /(`+)(([\s\S]*?)\1)/ );
if ( m && m[2] )
return [ m[1].length + m[2].length ];
else {
// TODO: No matching end code found - warn!
return [ 1, "`" ];
}
}
}假设我们想把所有 TODO 项收集到一起。只需输入以下命令,这些信息就会变得一览无余:
bash
:g/TODO
# 结果 :print是 :global命令的缺省 [cmd] ,它只是简单地回显所有匹配单
词"TODO"的文本行
3 // TODO: Cache this regexp for certain depths.
11 // TODO: No matching end code found - warn!先将所有包含单词"TODO"的文本行复制到某个寄存器,再把寄存器的内容粘贴到其他文件中,以备不时之需。
bash
:qaq #清空寄存器
:reg a # 查看寄存器a
:g/TODO/yank A #将TODO行复制到寄存器中
:reg a4.4、为:global的cmd单独指定范围
当 Ex 命令与 :global一起组合使用时, 我们也可以为 cmd 单独指定范围。 Vim允许我们以 :g/{pattern} 为参考点,动态地设定范围。
css
html {
margin: 0;
padding: 0;
border: 0;
font-size: 100%;
font: inherit;
vertical-align: baseline;
}
body {
line-height: 1.5;
color: black;
background: white;
}假设我们想把每一组规则内的属性都按照字母顺序排序。借助 Vim 的内置命令 :sort,就可以实现这一功能。
对单条规则的属性进行排序:
| 按键操作 | 缓冲区内容 |
|---|---|
{start} |
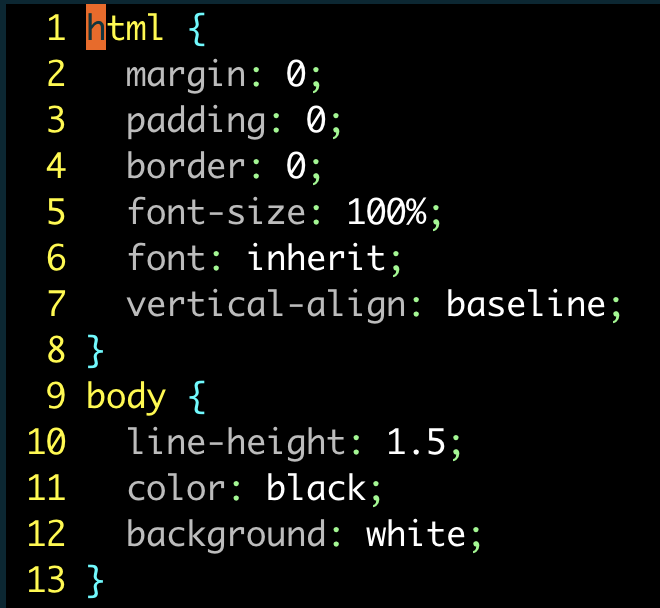 |
vi{ |
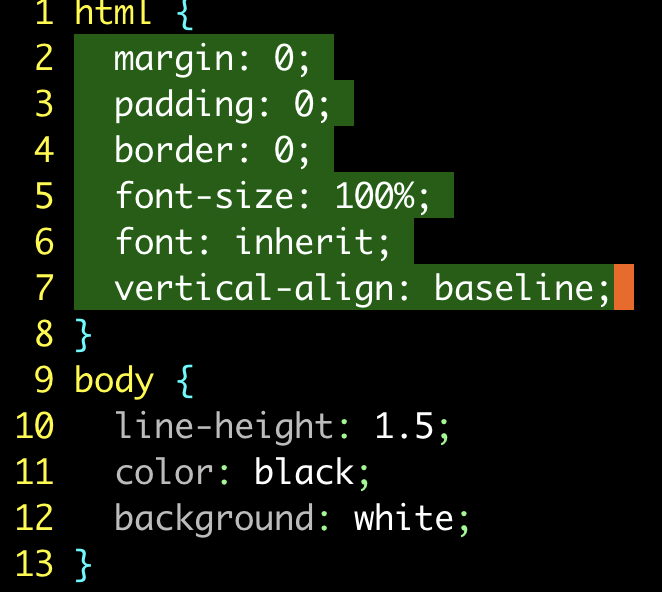 |
:'<,'>sort |
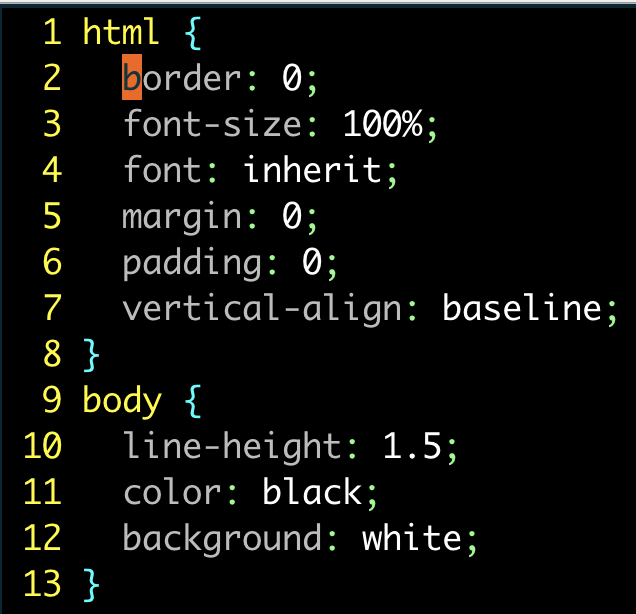 |
对所有规则的属性进行排序:
其实,我们可以用一条 :global 命令对文件中所有规则的属性进行排序。假设我们在本例的样式表中运行以下命令:
bash
:g/{/ .+1,/}/-1 sort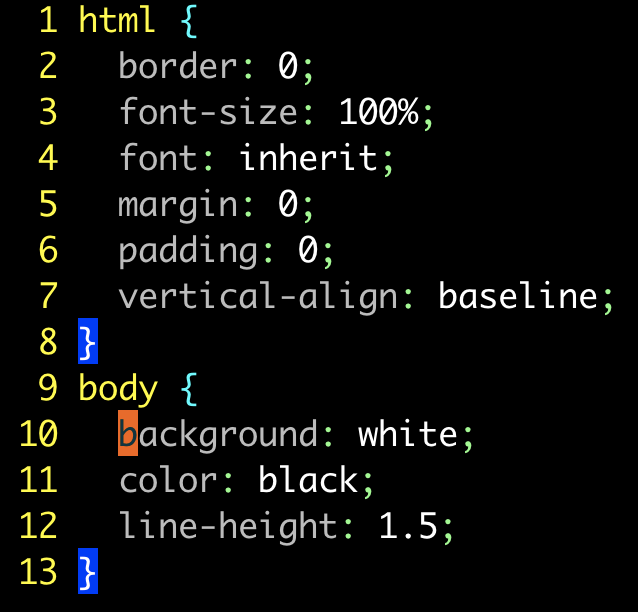
这条命令很复杂,但掌握其机理后,我们将会由衷地赞叹 :global 命令的强大。:global命令的标准格式如下所示:
bash
:g/{pattern}/[cmd]Ex 命令通常都会接受"范围"作为其参数。对于 :global命令内部的 cmd,该规则依然有效。因此,我们可以将命令的模板扩展成以下形式:
bash
:g/{pattern}/[range][cmd]实 际 上 , 我 们 可 以 用 :g/{pattern} 匹 配 作 为 参 考 点 , 动 态 设 置 cmd 的range。. 符号通常表示光标所在行,但在 :global 命令的上下文中,它则表示{pattern} 的匹配行。
bash
:g/{/ .+1,/}/-1 sort
# :g/{/ 匹配{
.+1,/}/-1 sort
# 去掉偏移,移值 +1 与 ---1 仅仅用于缩小操作范围
.,/}/
# 含义为从当前行开始,直到匹配到模式 /}/ 的那一行为止也就是说,我们只需将光标置于每个{} 块的起始位置,再运行
:.,/}/ sort命令,即可将其中的规则按照字母顺序重新进行排序了。