文章目录

Update
- 语法:
set后面加列属性或者表达式
UPDATE table_name SET column = expr , column = expr ...WHERE ... ORDER BY ... LIMIT ...
- 案例
- 将孙悟空同学的数学成绩变更为 80 分
sql
update exam_result set math=80 where name = '孙悟空';- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
sql
update exam_result set math=60,chinese=70 where name='曹孟德';- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
sql
// 先查询总分最后三名同学的总分
select name,math+english+chinese as total from exam_result order by total asc limit 3;
// 让后三名同学的数学加上30分
// 先执行order by 再执行update 最后执行limit
update exam_result set math = math + 30 order by math+english+chinese asc limit 3;
// 再查询最后三名同学的总分
select name,math+english+chinese as total from exam_result order by total asc limit 3; 可能倒数3名同学会发生变化
- 如果update没有设置条件会进行全列的更改,没有where子句则更新全表,更新全表的语句慎用
将所有同学的语文成绩更新为原来的 2 倍
sql
update exam_result set chinese = chinese*2;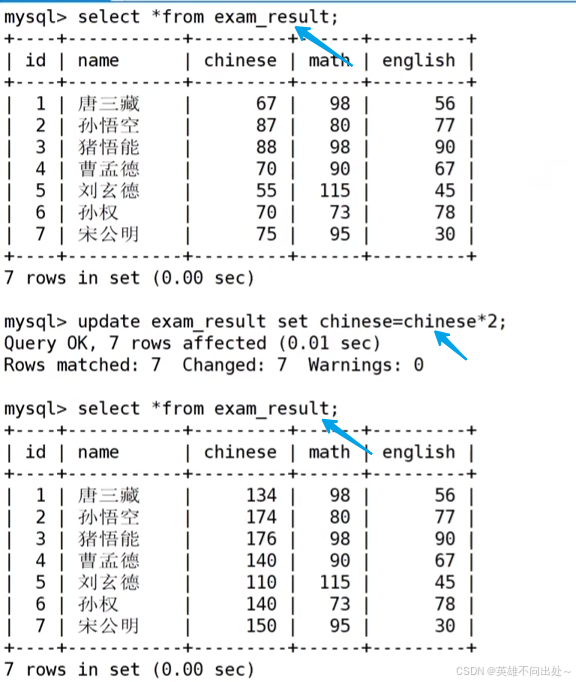
Delete
- 语法:
DELETE FROM table_name WHERE ... ORDER BY ... LIMIT ...
- 案例
- 删除孙悟空同学的考试成绩
sql
delete from exam_result where name='孙悟空';
// 删除全表的数据
delete from exam_result;- 删除倒数第一的人的成绩
sql
delete from exam_result order by math+english+chinese asc limit 1;- 清空表的数据
这种做法是不会让auto_increment的值置0的或者置空的
sql
delete from 表名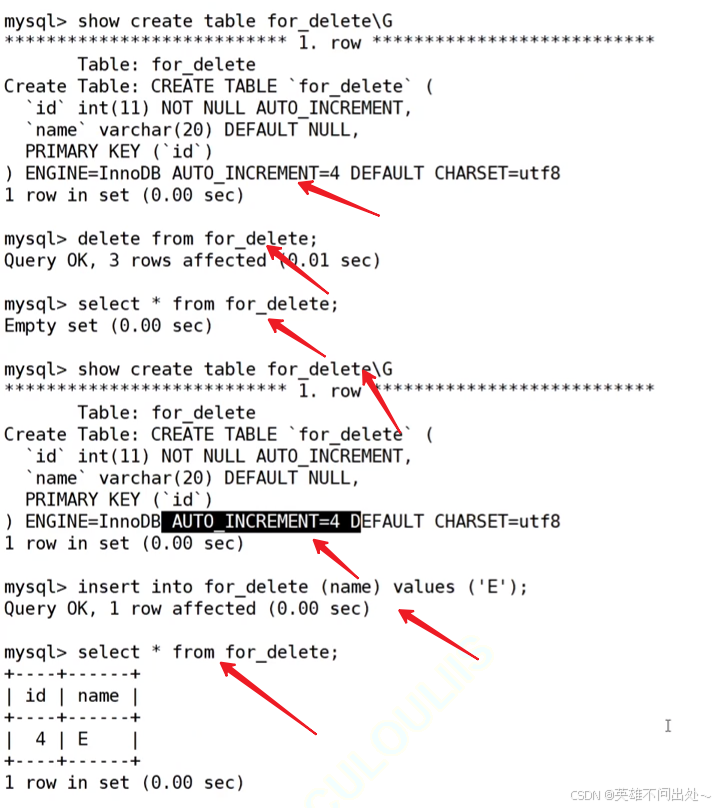
- 截断表
语法:
TRUNCATE TABLE table_name
sql
truncate table 表名- 会重置 AUTO_INCREMENT 项,删除表之后会重置auto_increment项,把它的值变为1
- truncate不会做更新日志的操作,delete from会做更新日志的操作
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事
物,所以无法回滚 - 只能对整表操作,不能像 DELETE 一样针对部分数据操作
- 三种日志:
<> bin log: 历史上操作过的sql语句优化之后保留下来------方便主从同步、备份、恢复
<> redo log:确保宕机、断电的时候数据不丢失(因为数据可能在内存中存着)------保证崩溃安全
<> undo log:做事务回滚、事务的隔离性

插入查询结果(select + insert)
- 语法
INSERT INTO table_name (column \[, column ...)] SELECT ...
- 案例
删除表中的的重复记录,重复的数据只能有一份
sql
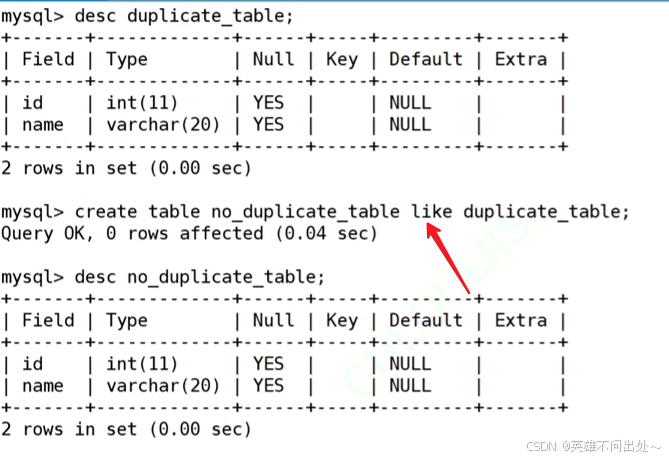
// 创建空表
create table no_duplicate_table like duplicate_table;
// 将去重之后的表插入到新表中
select distinct * from duplicate_table;
insert into no_duplicate_table select distinct * from duplicate_table;
// 查看no_duplicate_table得到去重之后的数据
select * from no_duplicate_table;
// 通过重命名表,实现原子的的去重操作
// 将原表重命名备份一下,然后把新表的名字改为原表的名字
rename table duplicate_table to old_duplicate_table;
rename table no_duplicate_table to duplicate_table;
// 查看最终的结果
select * from duplicate_table;-
只是打印去重,并没有修改原表中的数据

-
create table no_duplicate_table like duplicate_table;创建像duplicate_table一样的表结构
4. 为什么最后是通过rename的方式进行的?
单纯就是想等一切都就绪了,然后统一放入、更新、生效等。因为我们的move操作和重命名操作实际上就是在文件系统里就是改这个文件所在的目录里面文件名和inode的映射关系,他相较于冗长地向表中插入和冗长的上传行为比起来非常轻 。很有可能我这个目录有很多文件包括正在操作的这个文件正在被外部的网站或者各种语言正在访问,所以我们不能着急动这个表而是应该先把这个表先传到临时目录然后再统一move过去,这是一种比较推荐的做法
聚合函数
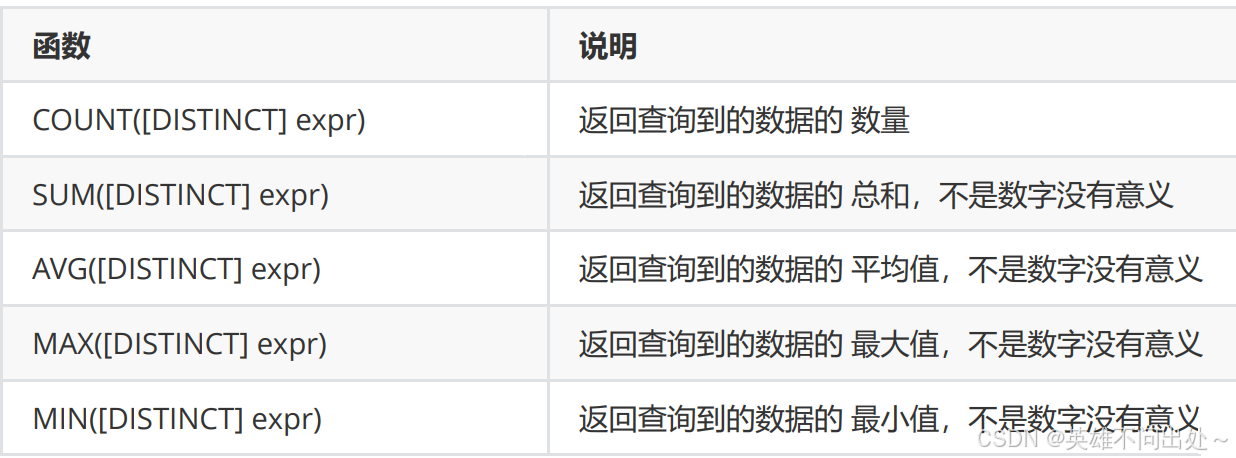
- 案例
统计班级共有多少同学- 用*做统计
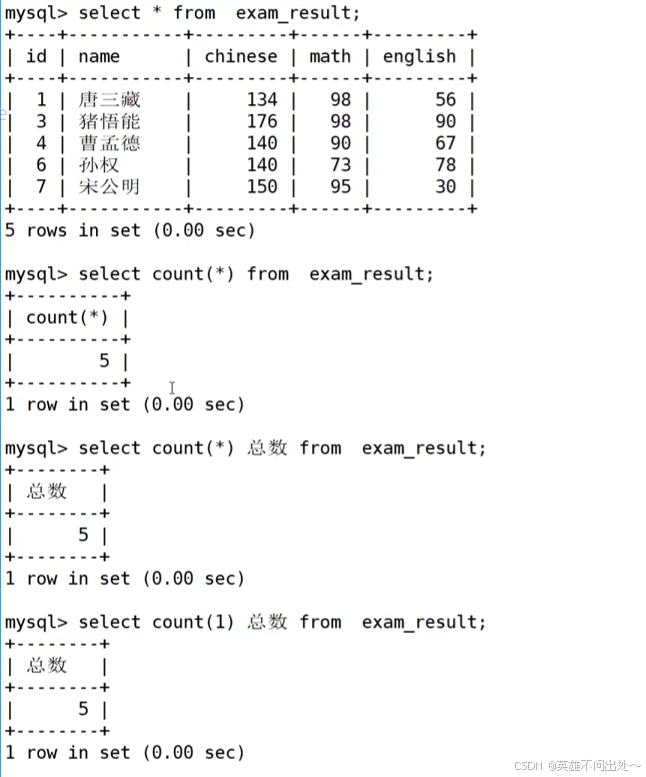
- 统计数学成绩有多少个
select count(math) as res from exam_result;
- 用*做统计
- 聚合函数会先算出后面表达式的结果,得到一个数字
统计去重后的数学成绩
select count(distinct math) from exam_result;
-
统计我们班数学的总分和平均成绩,英语的平均成绩
select sum(math) from exam_result
select sum(math)/count( * ) from exam_result
select sum(english)/count( * ) from exam_result -
统计数学成绩的平均分
select avg(math) from exam_result -
统计英语成绩的最高分
select max(english) from exam_result
7.返回 > 70 分以上的数学最低分
select min(math) from exam_result where math > 70;
总结:
1.只属于某一个人的信息是无法聚合的,比如名字和平均分在一起聚合就不行
分组聚合统计
- 分组的目的是为了进行分组之后进行每组的聚合统计
- 把数据拿出来(用select拿)再进行分组
- 语法:select column1, column2, ... from table group by column;
- 指定列名,实际分组,使用该列的不同行数据进行分组的

- 案例
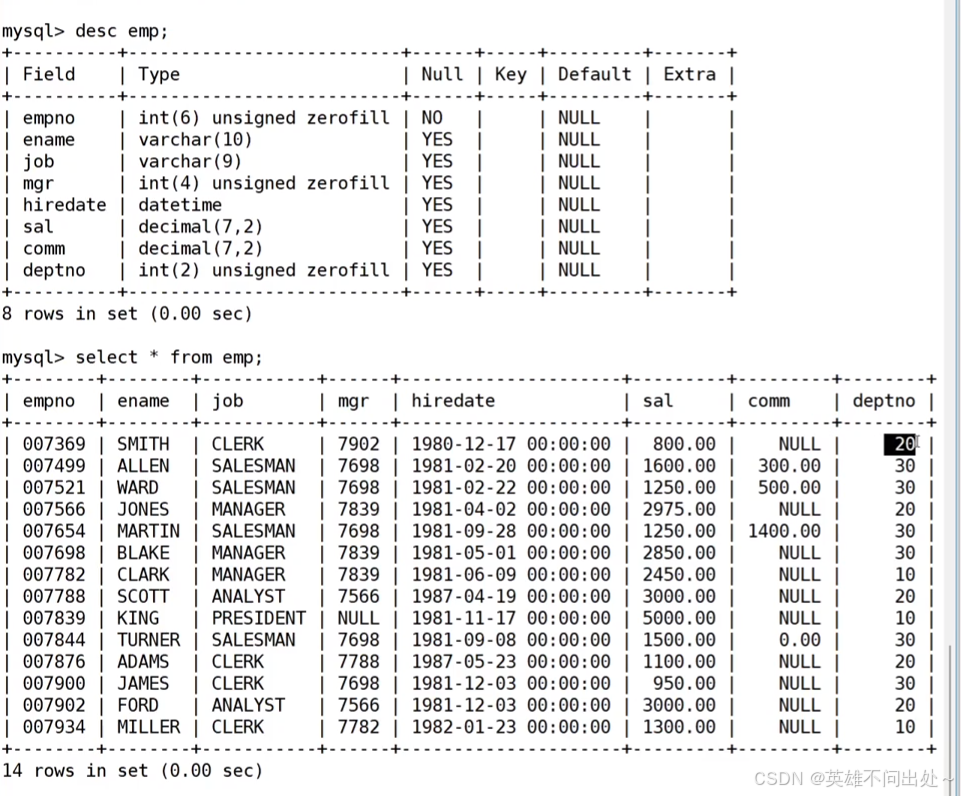
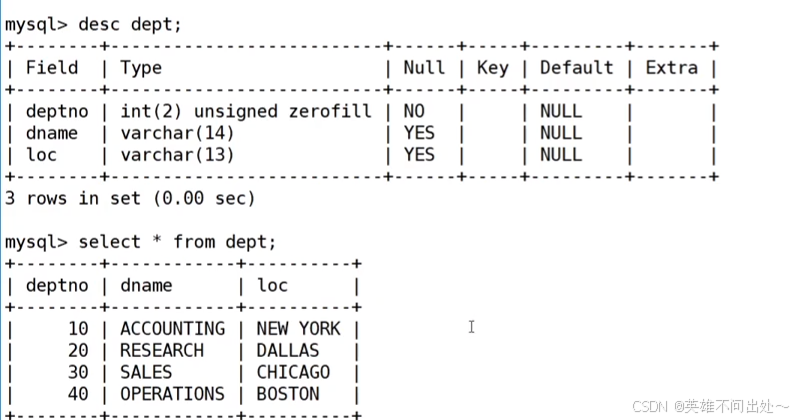
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
1、EMP员工表
2、DEPT部门表
3、SALGRADE工资等级表
sql
// 准备工作
//利用source将该备份文件恢复到数据库中
source /home/r/scott_data.sql;
use scott;
show tables;
emp
 dept
dept
salgrade
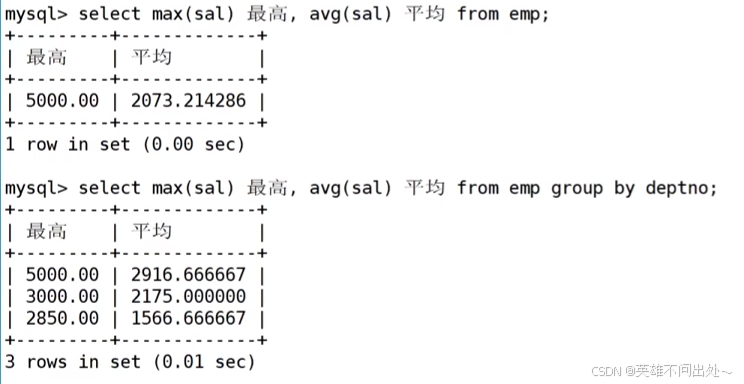
- 分组进行统计每个组的最高工资和平均工资

- 显示每个部门的每种岗位的平均工资和最低工资

3. 跟在select 后面的必须是分组的列属性或者是聚合函数,因为这些属性有相同的,而下图中名字是每个人都不同的属性,无法分组

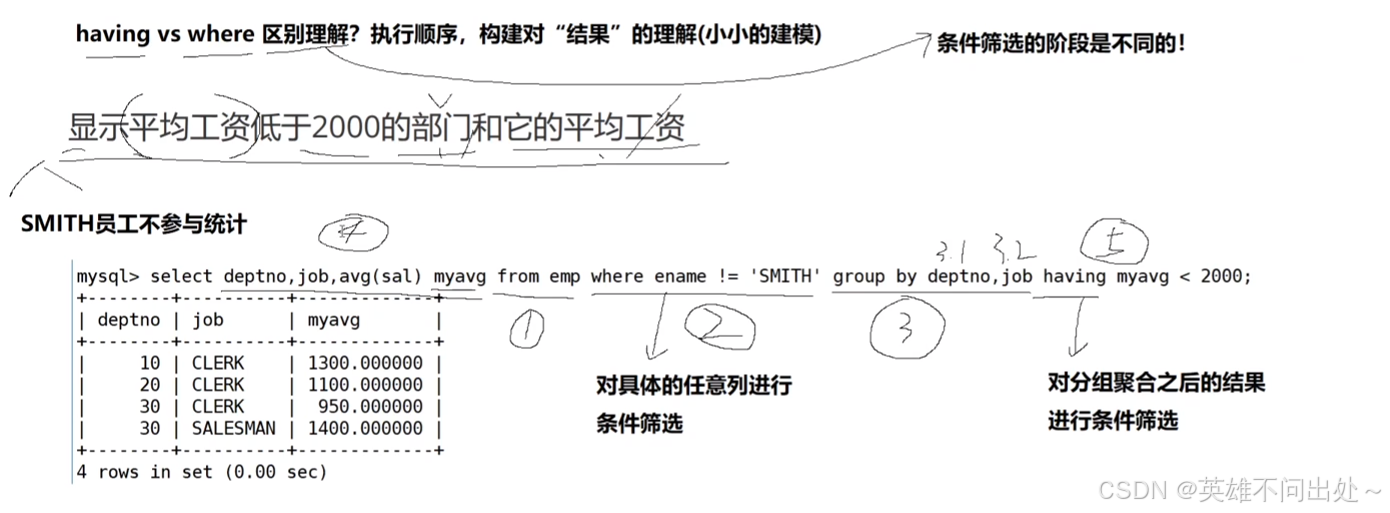
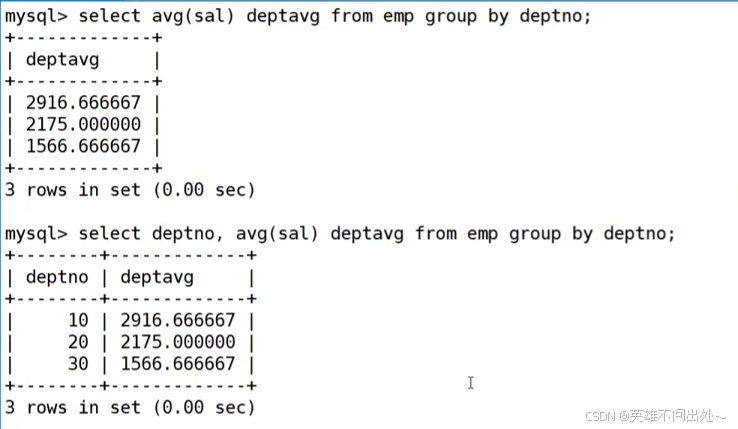
- 显示平均工资低于2000的部门和它的平均工资
先统计每个部门的平均工资,结果先聚合出来
select deptno,avg(sal) as 平均工资 from emp group by deptno;
再判断平均工资低于2000的部门再对聚合的结果进行判断
select deptno,avg(sal) as 平均工资 from emp group bydeptno having 平均工资<2000

5. having是对聚合后的统计数据进行条件筛选

- having 和 where 的区别
1,2,3,4,5表示顺序
MySQL中在逻辑上一切皆表