认识BERT
目标
- 什么是BERT
- 掌握BERT的架构
- 掌握BERT的预训练任务
什么是BERT
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种基于Transformer架构的预训练模型。
BERT在及其阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩, 全部两个衡量指标上全面超越人类, 并且在11种不同的NLP测试中创出SOTA表现, 包括将GLUE基准推至更高的80.4%(改进了7.6%), MultiNLI准确率达到了86.7%(改进了5.6%), 成为NLP发展史上里程碑的模型成就
BERT的架构
总体架构
最左边的就是BERT的架构图, 采用了Transformer Encoder block进行连接, 因为是一个典型的双向编码模型
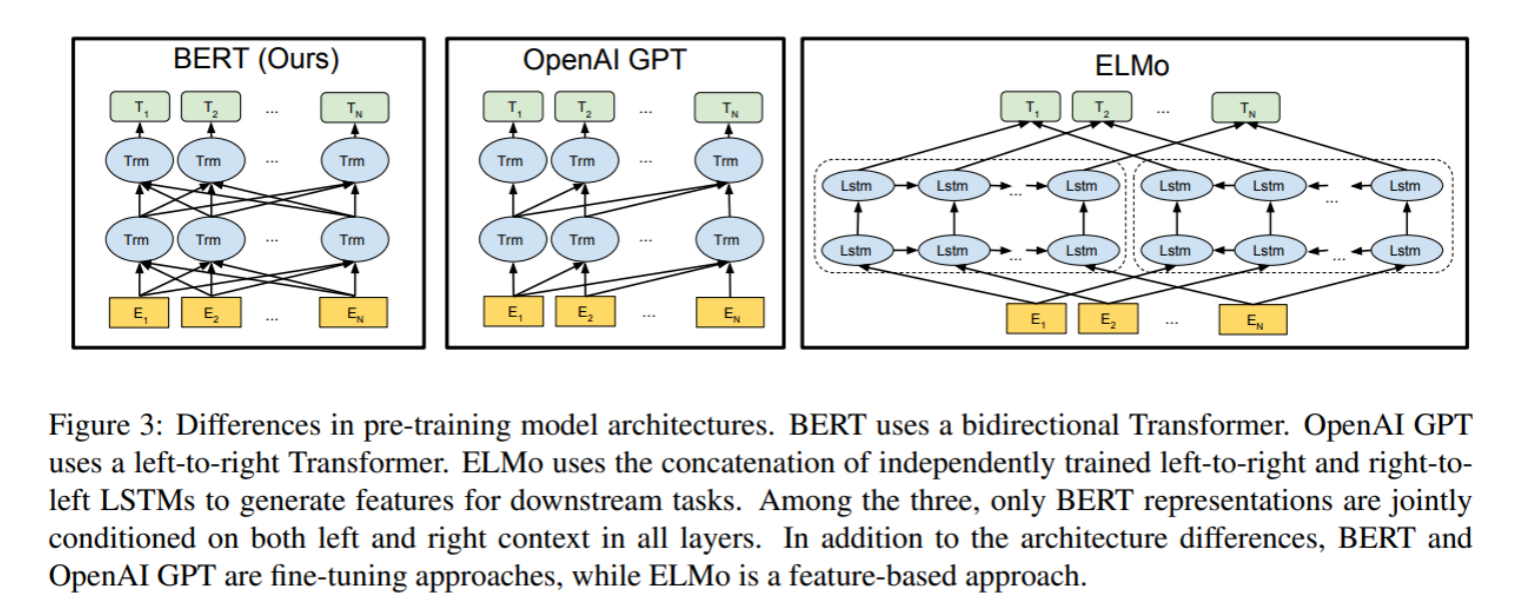
- BERT: 采用双向连接的结构
- GPT: 采用了从左向右(单向)的结构
- ELMo: 相互独立拼接的Lstm结构, 左边是预训练的Lstm结构, 右边是训练的Lstm结构, 最后将两块结构进行拼接输出
BERT架构说明
- 最底层黄色标记的是
Embedding模块 - 中间层蓝色标记的是
Transformer模块 - 最上层绿色标记的是预微调模型
Embedding模块
BERT中的模块是由三种Embedding共同组成而成
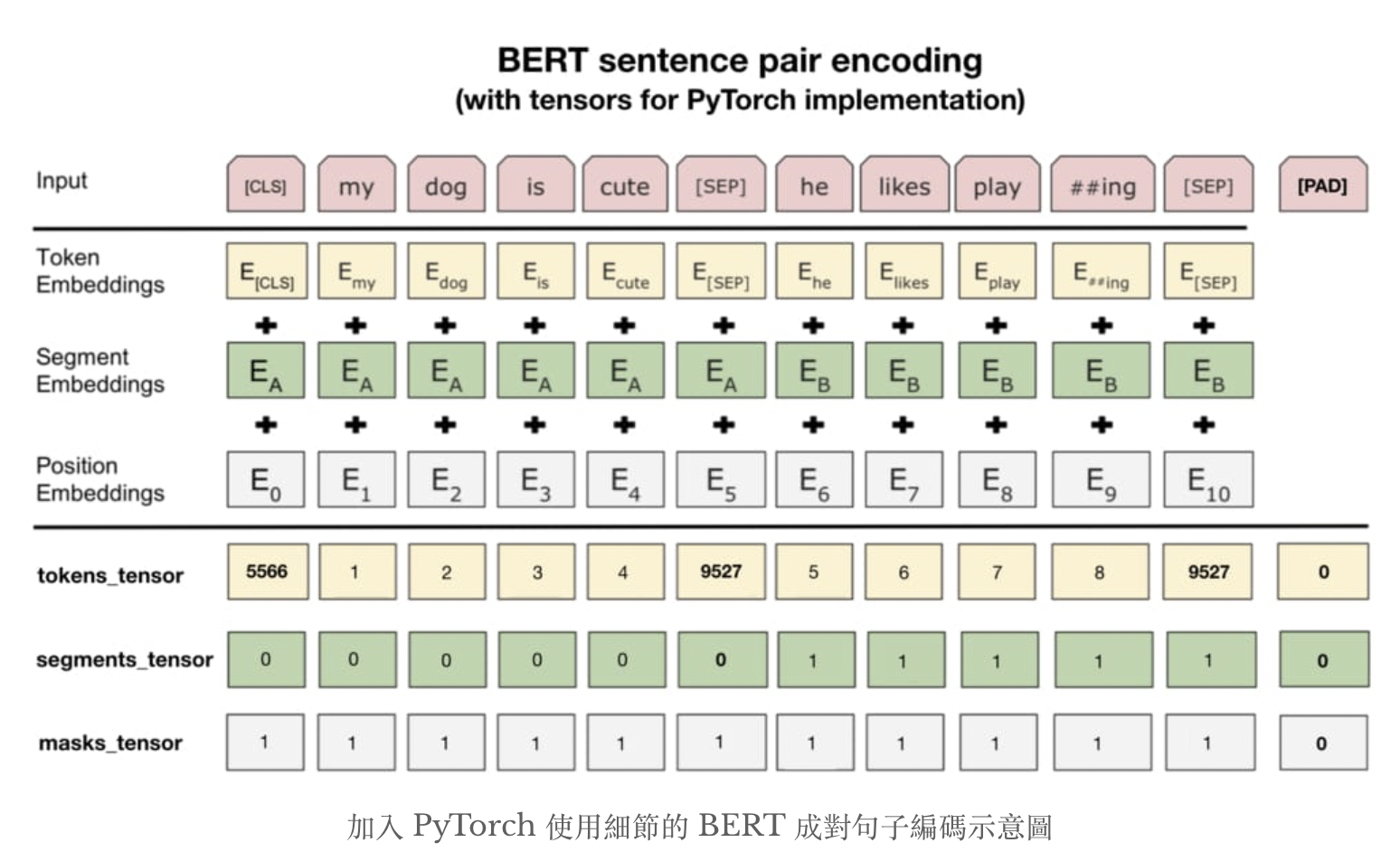
- Token Embeddings是词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务
- Segment Embeddings是句子分段嵌入张量, 是为了服务后续的两个句子为输入的预训练任务
- Position Embeddings是位置编码张量, 此处注意和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过学习得来的
- 整个Embedding模块的输出张量就是这三个张量直接相加的结果
双向Transformer模块
BERT中只是用了经典的Transformer架构中的Encoder部分, 完全舍弃了Decoder部分, 而量大预训练任务也集中体现在训练Transformer模块中
预微调模块
- 经过中间层Transformer处理后, BERT的最后一层根据任务的不同需求而做出不同的调整即可
- 比如对sequence-level的任务分类, BERT直接取第一个
[CLS] token的final hidden state再加上一层全连接层后进行softmax来预测最终的标签
不同任务的BERT架构图
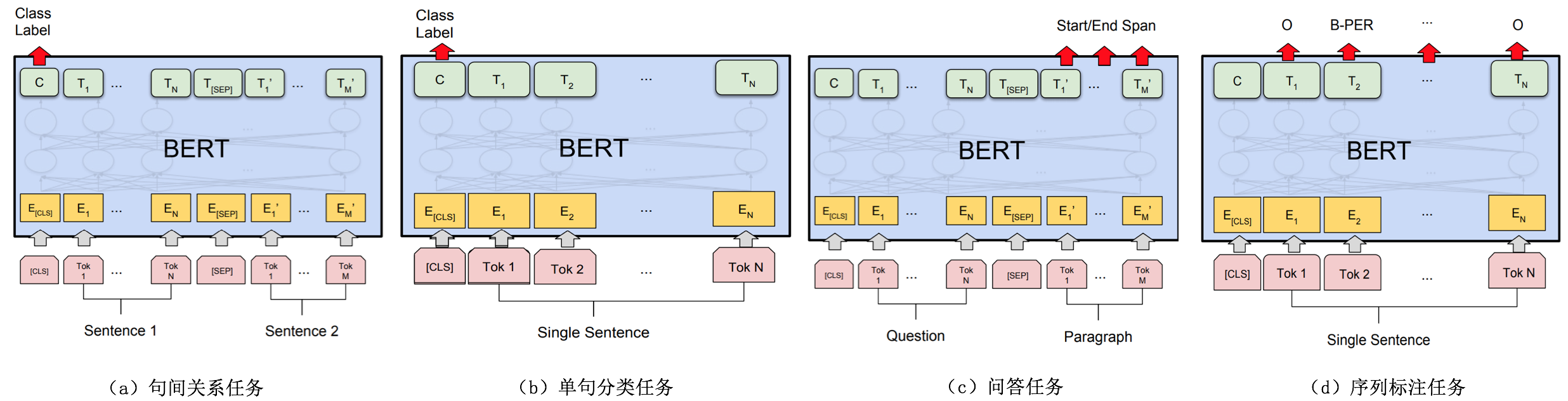
在面对特定任务时, 只需要对预微调层进行微调, 就可以利用Transformer强大的注意力机制来模拟很多下游的任务, 并得到SOTA结果
可选超参数建议
- Batch size: 16, 32
- Learning rate(Adam): 5e-5, 3e-5, 2e-5
- Epochs(鉴于Transformer的强大特征提取): 2, 3, 4
BERT的预训练任务
BERT的预训练任务有四种, 分别是Masked Language Model(MLM), Next Sentence Prediction(NSP), Sequence Classification(SC)和Token Classification(TC)
- MLM: 掩码语言模型, 预测被掩码的词
- NSP: 下一句预测, 预测当前句子是否为下一句
- SC: 序列分类, 预测当前句子的类别
- TC: 标记分类, 预测当前句子的标记
Masked LM(带mask的语言模型训练)
关于传统的语言模型训练, 都是采用left-to-right, 或者left-to-right + right-to-left结合的方式, 但是这种单向方式活着拼接的方式提取特征的能力有限, 为此BERT提出一个深度双向表达模型(deep bidirectional expression model), 采用MASK任务来训练模型
- 在原始训练文本中, 随机抽取15%的token作为参与MASK任务的对象
- 在这些被选中的token中, 数据生成器并不是把他们全部变成MASK, 而是由下面几种情况
- 80%的概率, 用MASK标记替换该token, 比如my dog is hairy -> my dog is MASK
- 10%的概率, 用随机的词替换该token, 比如my dog is hairy -> my dog is apple
- 10%的概率, 不做任何替换, 比如my dog is hairy -> my dog is hairy
- 模型在训练的过程中, 并不知道他将要预测哪些单词, 哪些单词是原始的样子, 哪些单词被遮掩成了MASK, 哪些单词替换成了其他单词, 正式这样一种高度不确定的情况, 倒逼模型快速学习token的分布式上下文的语义, 尽最大努力学习原始语言说话那样, 因为原始文本中只有15%参与了MASK, 所以并不会破坏原语言的表达能力
Next Sentence Prediction(下一句预测)
在NLP中有一类很重要的问题, 比如QA(Question-Answer),NLI(Natural Language Inference), 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务, 在BERT中引入的就是Next Sentence Prediction任务, 采用的方式是输入句子对(A, B)模型来预测句子B是不是句子A的真实的下一句话
- 所有参与任务训练的句子都被选中为句子A
- 其中50%的B式原始文本中真实跟随A的下一句话, 标记为IsNext, 代表证样本
- 其中50%的B式原始文本中随机选取一个句子, 标记为NotNext, 代表负样本
- 在任务二中, BERT模型可以在测试集上取得97%~98%的准确率
长文本处理
BERT预训练模型所接受的最大sequence长度为512,如果输入的序列长度超过512,则需要使用分词器进行分词,然后进行截断,截断后的序列长度为512。
如何截断
- head-only: 保留了长文本头部信息的截断方式, 具体为保存前510个token(要留两个位置给CLS和SEP)
- tail-only: 只保留长文本尾部信息的截断方式, 具体为保存前510个token(要留两个位置给CLS和SEP)
- head+only: 选择前128个token和最后382个token(总长度在800内), 或者前256个token和最后254个token(总长度大于800)
特点
优点
- 通过预训练加上Fine-tuning, 在11项NLP任务上都取得了最优结果
- BERT的根基源于Transformer, 相比传统的RNN更加高效, 可以并行化处理同时能捕获长距离的语义和结构依赖
- BERT采用了Transformer架构中的Encoder模块, 不仅仅获得了真正意义上的bidirectional context, 而且为后续微调任务留出了足够的调整空间
缺点
- 模型参数庞大, 参数太多, 不利于资源紧张的应用场景, 不利于线上实时处理
- 目前给出的中文模型中, 以字为基本token单位, 很多需要词向量的应用无法直接使用, 同时该模型无法识别很多生僻词, 只能以UNK代替
- 第一个预训练任务MLM中, MASk标记只在训练阶段出现, 而在预测阶段不会出现, 这就造成了一定的信息偏差, 因此训练时不能过多的使用MASK, 否则会影响模型的表现
- 按照BERT的MLM任务约定, 每个batch数据中只有15%的token参与了训练, 被模型学习和预测, 所以BERT收敛的速度比left-to-right的RNN慢很多, 需要的算力和时间都更多
MLM任务中为什么采用80%, 10%, 10% 的策略
BERT中的MLM(Masked Language Model)任务采用80%、10%、10%的策略,其核心设计理念是为了在预训练和微调阶段之间建立一致性,同时提升模型对上下文的鲁棒性。以下从设计理念、解决的问题和具体实现三个层面展开深度解析:
一、设计理念的核心逻辑
1. 缓解预训练与微调的数据分布差异
- 问题背景 :在传统的语言模型预训练中,如果直接使用
[MASK]标记替换所有被遮盖的token,模型会过度依赖[MASK]的存在。但在微调阶段,输入文本中没有[MASK],导致预训练和下游任务的数据分布不匹配。 - 解决方案 :通过仅以80%的概率将遮盖的token替换为
[MASK],其余20%的情况下采用其他策略(随机替换或保留原词),使模型在预训练阶段接触更多类似真实场景的输入,从而减少分布差异。
2. 提升模型对上下文的鲁棒性
- 随机替换(10%):将10%的遮盖token替换为随机词,迫使模型不能依赖被遮盖位置本身的局部信息(如词频或共现模式),而是必须通过更广泛的上下文理解语义。这种设计类似于对抗训练,增强了模型对噪声的容忍度。
- 保留原词(10%):剩余10%的遮盖token保持不变,模型需要在这种情况下预测正确的词(尽管输入未被修改)。这要求模型不仅要识别被遮盖的位置,还要验证当前输入的合理性,从而学习更精确的上下文表示。
3. 平衡训练效率与学习信号多样性
- 效率优先 :80%的
[MASK]策略直接提供明确的监督信号(预测原词),确保模型能高效学习语言结构。 - 多样性补充:10%的随机替换和10%的保留原词引入额外的学习目标,避免模型陷入局部最优,同时模拟真实场景中可能存在的错误或冗余信息。
二、解决的关键问题
1. 预训练与微调的不一致性
- 传统方法的缺陷 :若预训练时始终用
[MASK]遮盖词,模型会将其作为唯一线索预测目标词,但微调时输入中没有[MASK],导致性能下降。 - BERT的改进 :通过混合策略,模型在预训练阶段学习从多种输入模式(
[MASK]、随机词、真实词)中提取信息,从而适应微调阶段的完整输入。
2. 对局部依赖的抑制
- 局部依赖问题 :若仅用
[MASK],模型可能依赖被遮盖词周围的局部共现模式(如"苹果"常出现在"手机"附近),而非全局语义。 - 随机替换的抑制作用:10%的随机词替换破坏了局部上下文,迫使模型通过更长距离的依赖关系(如句子级语义)进行推理。
3. 对冗余信息的鲁棒性
- 保留原词的意义:10%的未修改token要求模型即使面对完整输入,也能识别并验证关键信息。这模拟了实际任务中可能存在的冗余或无关信息(如拼写错误、重复表述),提升模型的容错能力。
三、设计背后的理论依据
1. 数据增强与对抗训练
- 数据增强视角:随机替换和保留原词可视为一种数据增强,通过引入噪声和多样化输入,增强模型的泛化能力。
- 对抗训练视角:随机替换相当于向输入注入对抗性扰动,模型需学习忽略无关干扰,聚焦于核心语义。
2. 隐式语言模型的双重目标
- 生成与判别结合:MLM本质上是生成任务(预测原词),但混合策略隐含判别任务(判断当前词是否正确)。这种双重目标使BERT兼具生成模型和判别模型的优势。
3. 信息瓶颈理论
- 信息压缩与保留 :通过遮盖、替换和保留操作,模型需在有限的输入信息(如
[MASK])和冗余信息(如随机词)中压缩并提取关键语义,从而学习到更紧凑的表示。
四、实验验证与效果
BERT论文中的消融实验表明:
- 纯
[MASK]策略:性能显著下降,验证了混合策略的必要性。 - 随机替换比例过高:可能导致训练不稳定,因过多噪声干扰语义学习。
- 保留原词比例过高:会削弱遮盖任务的挑战性,降低模型对上下文的依赖。
最终选择80-10-10的比例,是在训练效率、鲁棒性和任务难度之间达到平衡的经验结果。
五、总结
BERT的80-10-10策略是预训练任务设计的典范,其核心思想在于通过混合策略:
- 弥合预训练与微调的鸿沟;
- 增强模型对上下文的全局理解;
- 提升鲁棒性与泛化能力。
这一设计不仅解决了传统语言模型的局限性,还为后续预训练方法(如SpanBERT、ALBERT)提供了重要启示。