目录
- 前言
- [1 读取数据的流程](#1 读取数据的流程)
-
- [1.1 检查缓存是否命中](#1.1 检查缓存是否命中)
- [1.2 从数据库读取数据](#1.2 从数据库读取数据)
- [1.3 更新缓存](#1.3 更新缓存)
- [1.4 返回数据](#1.4 返回数据)
- [2 写入数据的流程](#2 写入数据的流程)
-
- [2.1 更新数据库](#2.1 更新数据库)
- [2.2 更新或删除缓存](#2.2 更新或删除缓存)
- [2.3 缓存失效](#2.3 缓存失效)
- [3 缓存与数据库的一致性问题](#3 缓存与数据库的一致性问题)
-
- [3.1 写穿(Write-through)策略](#3.1 写穿(Write-through)策略)
- [3.2 写回(Write-back)策略](#3.2 写回(Write-back)策略)
- [3.3 缓存失效策略](#3.3 缓存失效策略)
- [4. 总结与实践](#4. 总结与实践)
-
- [4.1 性能提升](#4.1 性能提升)
- [4.2 一致性挑战](#4.2 一致性挑战)
- [4.3 实践中的注意事项](#4.3 实践中的注意事项)
- 结语
前言
随着互联网应用的快速发展,数据访问的效率成为了许多系统设计中的核心问题之一。在大规模分布式系统中,数据库往往成为了性能瓶颈,尤其是当应用需要频繁地读取相同的数据时。为了提升系统性能,减少数据库的压力,缓存技术应运而生。缓存通过将频繁访问的数据存储在内存中,显著降低了读取延迟,提升了响应速度。但缓存的引入也带来了数据一致性的问题,需要精心设计缓存与数据库的交互流程。
本文将深入探讨缓存和数据库的读写流程,并分析它们的协作模式,帮助开发者更好地理解如何通过合理的缓存策略来提升系统性能和稳定性。
1 读取数据的流程
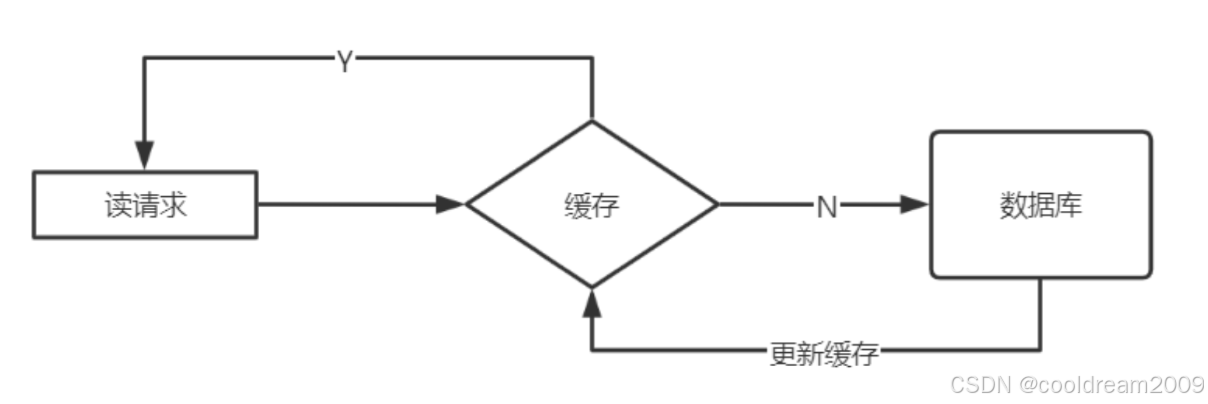
在引入缓存之后,读取数据的过程通常包括检查缓存、访问数据库和更新缓存等几个关键步骤。以下是缓存读取的详细流程。
1.1 检查缓存是否命中
当应用程序需要读取某一数据时,首先会去检查缓存中是否存在这条数据。缓存是一个快速的内存存储系统,它比传统的硬盘数据库访问速度快得多。常见的缓存技术包括 Redis、Memcached 等。在缓存中,每一条数据通常会根据某个唯一标识符(如数据的主键或唯一 ID)存储,这样在读取时只需通过标识符即可快速定位。
缓存的命中与否直接影响到读取的效率:
- 缓存命中:如果缓存中已经存在所需数据,那么应用直接从缓存中取出数据并返回。此时,数据库并未被访问,响应速度非常快。
- 缓存未命中:如果缓存中没有所需数据,那么应用需要访问数据库来获取数据。
1.2 从数据库读取数据
如果缓存未命中,系统会查询数据库获取数据。此时,系统会根据请求的数据标识符向数据库发起查询。数据库查询通常会涉及 SQL 查询语句的执行,虽然数据库的查询性能相对较高,但由于其底层是硬盘存储,读写速度通常比内存缓存要慢。因此,频繁的数据库查询可能会导致系统的性能瓶颈。
1.3 更新缓存
从数据库成功读取到数据后,为了提高下次读取的效率,系统会将数据存储到缓存中。这样,下一次相同的请求就可以直接从缓存中获取,避免了再次访问数据库。缓存更新的策略可以是直接写入,也可以选择根据一定的规则对缓存进行更新。例如,可以选择为每条缓存数据设置一个过期时间,定期更新缓存中的数据。
1.4 返回数据
在数据成功读取并缓存后,系统将最终的数据返回给客户端,完成一次读取请求的处理。需要注意的是,缓存中的数据并不一定是最新的,尤其在写操作后,缓存可能会存在短时间的不一致。因此,在设计时需要特别注意缓存的一致性问题。
2 写入数据的流程
与读取数据的流程相比,写入数据的流程相对复杂,尤其在需要确保数据一致性时。写入数据时,缓存和数据库的更新必须同步进行,否则可能会出现缓存与数据库之间的数据不一致问题。写操作的主要流程可以分为以下几个步骤。
2.1 更新数据库
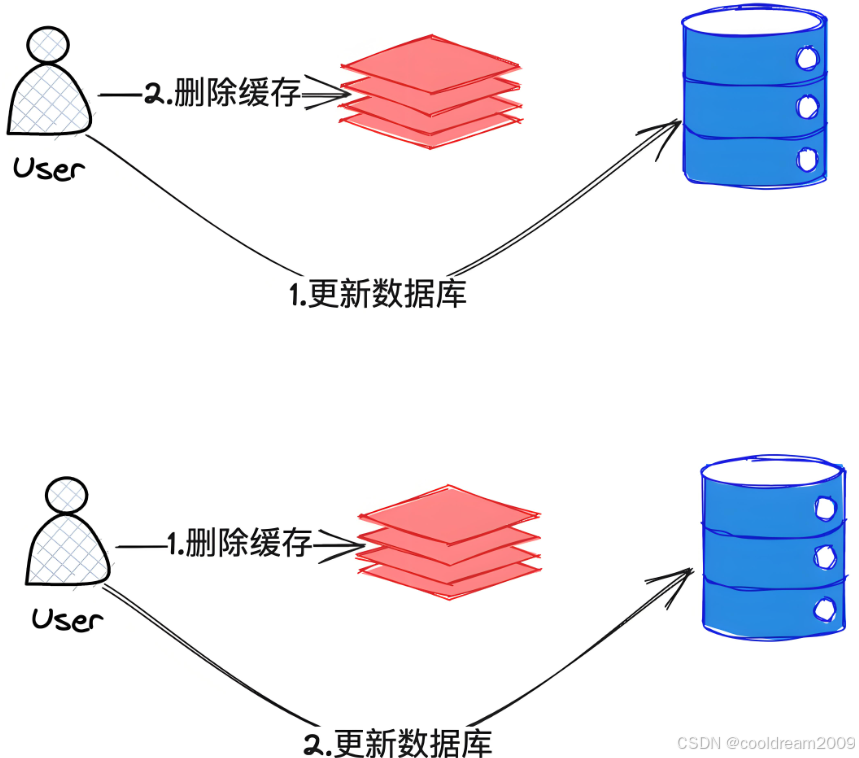
无论数据是否在缓存中,写操作的首要任务是确保数据库中的数据始终保持一致。因此,所有的数据修改都首先会写入数据库,确保数据的持久化。这是因为缓存并非持久化存储,可能会因服务器重启等原因丢失数据,而数据库通常是唯一的数据持久化存储。
2.2 更新或删除缓存
在更新完数据库之后,接下来就需要考虑如何更新缓存。对于缓存的更新,有两种常见的策略:
- 直接更新缓存:当数据更新完成后,直接将新的数据写入缓存。这样做可以确保缓存中的数据与数据库中的数据始终保持一致,适用于那些更新频繁、需要保证高一致性的场景。
- 删除缓存:如果不需要立即更新缓存,或者希望通过重新计算来获取最新的数据,可以选择删除缓存中的数据。这样,当下一次请求相同数据时,系统会重新从数据库中读取数据并更新缓存。这种方式在某些场景下能够减少缓存更新的复杂性。
2.3 缓存失效
另一种常见的处理方式是使用缓存过期机制。缓存中的数据通常会设置一个有效期(TTL),当数据过期后,缓存会自动失效,下一次请求时会重新从数据库中获取数据并更新缓存。这种方式在更新不频繁或对数据一致性要求不那么严格的场景下非常有效。
3 缓存与数据库的一致性问题
缓存和数据库的交互虽然能够显著提升系统性能,但在大规模应用中,缓存与数据库之间的一致性问题是不可忽视的。为了保持缓存与数据库的数据一致性,常见的解决策略有以下几种:
3.1 写穿(Write-through)策略
写穿策略是指每次数据写入时,都会同时更新数据库和缓存。这意味着,无论何时进行写操作,都会确保缓存和数据库的数据始终保持一致。写穿策略简单且易于实现,但其缺点是每次写操作都需要访问数据库,可能会导致一定的性能开销。
3.2 写回(Write-back)策略
写回策略与写穿策略不同,写回策略首先会将数据写入缓存,而数据库的更新则延迟一段时间,通常是异步的。这样,系统在高频写操作下能够提高性能,但也带来了数据一致性问题。为了确保最终一致性,通常需要定期将缓存中的数据同步到数据库,或者在数据写入后通过后台任务来更新数据库。
3.3 缓存失效策略
缓存失效策略是在数据更新时,主动将缓存中的数据标记为失效,或者删除缓存中的数据。这样,下一次请求时,数据就会重新从数据库中读取并更新缓存。这种策略相对简单,但需要保证缓存和数据库之间的数据同步和时效性。
4. 总结与实践
缓存技术在提高系统性能、减少数据库负担方面具有重要作用,但它也引入了缓存与数据库之间的一致性问题。在设计缓存和数据库的交互时,需要综合考虑性能、数据一致性、复杂度等因素。
4.1 性能提升
缓存的最大优势在于提升读取性能。通过将热点数据存储在内存中,缓存能够显著减少数据库的查询次数,从而降低延迟和响应时间,提高系统的整体吞吐量。在高并发场景下,缓存的引入能够有效分担数据库的负载,提升系统的可扩展性。
4.2 一致性挑战
尽管缓存能大幅提升性能,但缓存与数据库之间的数据一致性问题依然是不可忽视的挑战。在高并发场景中,缓存和数据库的同步更新往往是一个复杂的问题。开发者在选择缓存策略时,需要根据业务需求和实际场景做出权衡。例如,对于一些数据更新不频繁的应用,缓存失效策略可能是一个不错的选择;而对于需要高一致性的场景,写穿策略则可能更加适合。
4.3 实践中的注意事项
在实际开发中,缓存与数据库的协作是一个非常常见的场景。在实现时,开发者需要关注以下几个方面:
- 缓存的粒度:缓存的数据粒度不宜过大,否则会导致内存浪费。应根据业务需求合理规划缓存的粒度。
- 缓存的过期策略:合理的过期时间可以帮助保持数据的新鲜度,防止过期数据对系统性能产生负面影响。
- 缓存与数据库的同步策略:在写操作中,如何确保缓存和数据库的数据一致性,应该根据具体的业务需求和数据更新频率来选择合适的策略。
结语
缓存与数据库的交互是一个高效系统设计的核心部分,通过合理的缓存策略可以大大提升应用的性能。然而,缓存与数据库的同步、数据一致性等问题也需要开发者在设计时仔细考虑。随着技术的发展,我们可以借助各种工具和策略来优化这一过程,确保系统在提供高性能的同时,也能保持数据的一致性和可靠性。在未来的应用开发中,缓存技术仍将发挥越来越重要的作用。