1. 工具介绍
1.1. 简介
一个轻量级、高性能的数据可视化工具
- 官网:https://superset.apache.org/
- GitHub链接:https://github.com/apache/superset
- 官方文档:https://superset.apache.ac.cn/docs/intro/
1.2. 核心功能
- 丰富的可视化库:支持 40+ 预置可视化类型,包括折线图、柱状图、饼图、散点图、地图等,满足时序、地理信息等多种分析需求
- 强大的 SQL Lab:内置 Web 化 SQL 编辑器,支持多数据源查询和结果可视化,无需离开平台即可完成数据探索
- 自定义可视化插件:支持通过 JavaScript/TypeScript 编写可视化插件,实现企业级定制,满足特殊展现需求
2. 安装Superset
2.1. 系统依赖
ubuntu20.04 系统依赖,其他系统参考官方文档
bash
sudo apt-get install build-essential libssl-dev libffi-dev python-dev python3-pip libsasl2-dev libldap2-dev default-libmysqlclient-dev2.2. Python环境
- 建议单独为SuperSet创建一个虚拟环境,用这个环境将Superset进程后台执行
bash
conda create -n superset python=3.10
# python环境里安装superset
pip install --upgrade setuptools pip
pip install apache-superset marshmallow==3.26.12.3. Superset数据库配置
- 初始化数据库(底层的操作是建库,建表)
bash
# 添加环境变量
export FLASK_APP=superset
# flask是一个python web框架,superset使用的就是flask框架
# 生成随机的秘钥
openssl rand -base64 42
# 复制上面生成的秘钥
# 添加到环境变量(替换"openssl-secret-key"为上面生成的秘钥)
export SUPERSET_SECRET_KEY="openssl-secret-key"
bash
# 初始化数据库
superset db upgrade- 按照显示来设置用户名和密码
bash
superset fab create-admin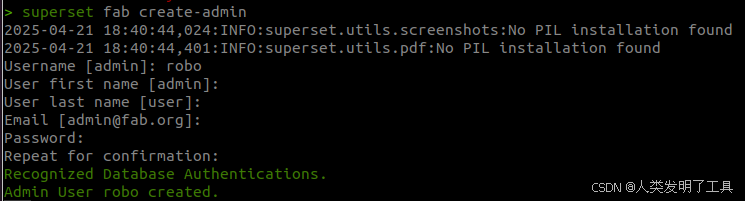
- Superset初始化
bash
superset init3. 使用Superset
3.1. 启动和停止
- Gunicorn:是一个用于UNIX系统的Python WSGI HTTP服务器,以其易用性、性能优越及与多种Python web框架的兼容性而被广泛应用于部署Python网络应用。
bash
pip install gunicorn
# 启动superset
gunicorn --workers 5 --timeout 120 --bind 127.0.0.1:8787 "superset.app:create_app()" --daemon--workers:指定进程个数
--timeout:worker进程超时时间,超时会自动重启
--bind:绑定本机地址 ,即为Superset访问地址
--daemon:后台运行
- 查看本机ip地址
bash
ifconfig根据自己的需求场景,选择合适的ip地址,进行bind配置:
| 场景 | 推荐 --bind 配置 |
说明 |
|---|---|---|
| 本地开发测试 | 127.0.0.1:8000 |
安全且仅本地访问 |
| 局域网/公网直接访问 | 公网ip地址:8000 |
绑定具体网卡IP,需开放防火墙端口 |
| 生产环境(Nginx代理) | 127.0.0.1:8000 + Nginx配置 |
高安全性和性能优化 |
| Docker容器内运行 | 0.0.0.0:8000 |
需映射容器端口到宿主机 |
- 关闭/杀死后台superset进程
bash
ps -ef |grep superset |grep -v grep |awk '{print $2}' |xargs kill -93.2. Web端配置使用
TODO