配置历史服务
一、停止任务
进入/opt/module/spark-standalone/sbin, 运行命令:
./stop-all.sh
二、修改配置
进入 /opt/module/spark-standalone/conf/spark-default.conf.temple 先把名称改成spark-default.conf,再补充两个设置。如下所示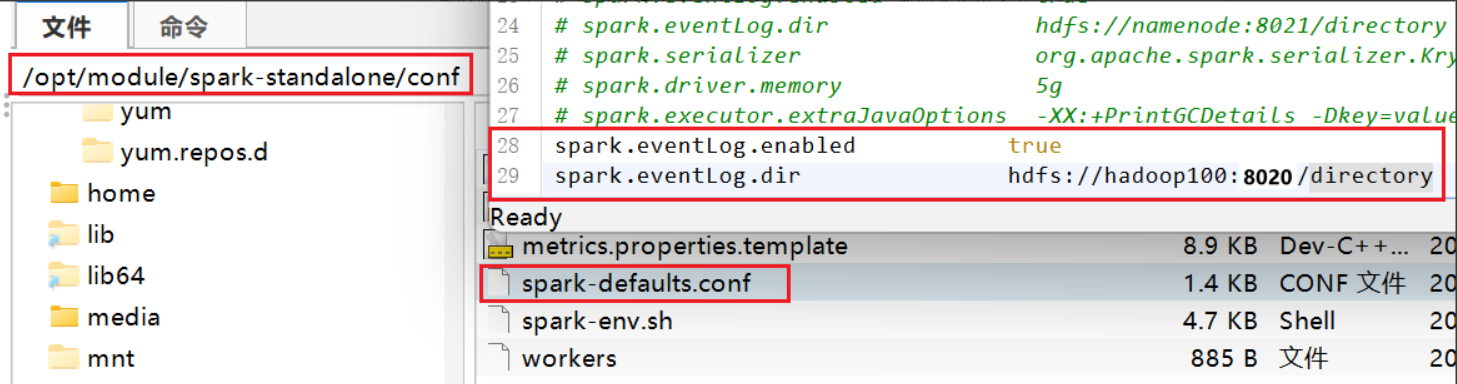 具体代码如下:
具体代码如下:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
三、创建目录
启动hadoop的hdfs服务(start-dfs.sh),并在根目录创建目录directory。可以通过命令行的方式来创建,也可以通过hadoop100:9870的页面操作来创建。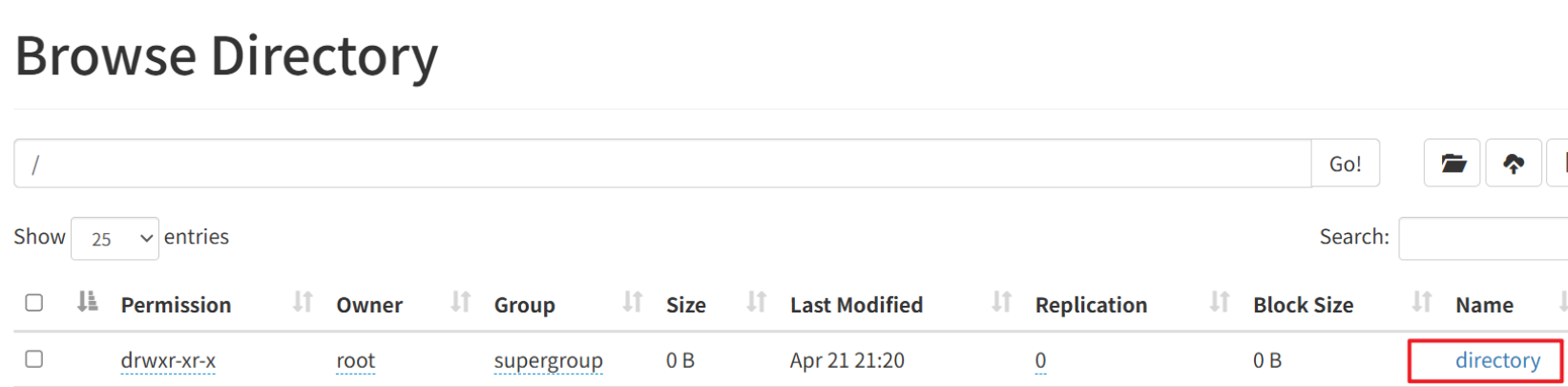
四、修改spark-env.sh文件
(注:4、5两步在上一条博客中直接一起配置了,所以这里可自行跳过)
添加一句设置:
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory"
五、分发配置文件
xsync /opt/module/spark-standalone/conf/
六、重启spark集群。
命令是 ./start-all.sh
七、启动历史服务器
命令是 ./start-history-server.sh