针对Kafka集群Broker磁盘IO瓶颈问题,这里从实际运维场景出发给出解决方案:
1. 分区负载均衡优化
分区迁移策略
bash:分区迁移操作
# 查看Topic分区分布(识别热点Broker)
kafka-topics --bootstrap-server broker1:9092 --describe --topic high_throughput_topic
# 生成迁移计划(将高负载分区的Leader分散到低负载Broker)
kafka-reassign-partitions --bootstrap-server broker1:9092 \
--topics-to-move-json-file topics.json \
--broker-list "4,5,6" \ # 目标选择空闲Broker
--throttle 50MB \ # 限速保护磁盘IO
--generate关键配置说明
-
目标Broker选择标准:
- 磁盘剩余空间 > 30%
- CPU利用率 < 60%
- 网络吞吐 < 1Gbps
-
迁移限速计算公式:
限速值 = min(目标Broker磁盘写入IOPS × 80%, 源Broker磁盘读取IOPS × 50%)
迁移后验证
powershell:Windows性能监控
# 使用Performance Monitor实时监控目标Broker磁盘队列长度
typeperf "\LogicalDisk(_Total)\Avg. Disk Queue Length" -si 5 -sc 60
# 检查迁移进度(Windows PowerShell)
kafka-reassign-partitions --bootstrap-server broker1:9092 --verify --reassignment-json-file reassign.json配套优化建议
-
磁盘热点预防:
在server.properties中配置
log.dir=/data/kafka/{broker.id}实现自动目录隔离 -
消费者并行优化:
java:消费者线程配置executor.setCorePoolSize(Runtime.getRuntime().availableProcessors() * 2); executor.setThreadFactory(new ThreadFactoryBuilder().setNameFormat("consumer-worker-%d").build());
紧急熔断方案
当迁移导致目标Broker磁盘IOPS超过90%时,立即执行:
bash:迁移熔断
kafka-configs --alter --entity-type brokers --entity-name 4 --add-config follower.replication.throttled.rate=0**方案弊端:**如果这个时候所有broker的压力都很大,使用分区迁移策略是没有效果的,这种方法的本质是负载均衡,如果出现这种情况,建议新增broker。
新增broker方案
1. 新Broker部署规范
properties:config/server-new.properties
# 关键参数配置(避免与现有集群冲突)
broker.id=1001
listeners=PLAINTEXT://:9093
log.dirs=D:\\kafka_data\\new_broker_logs
zookeeper.connect=zk1:2181,zk2:2181/kafka_cluster
num.network.threads=8 # 根据CPU核心数调整
num.io.threads=16 # 建议SSD配置16~242. 滚动扩容操作
powershell:Windows部署流程
# 新节点安装(管理员权限)
.\kafka_2.13-3.6.1\bin\windows\kafka-server-start.bat .\config\server-new.properties
# 验证节点注册状态
kafka-broker-api-versions --bootstrap-server new-broker:9093 --command-config .\config\client.properties3. 数据均衡策略
bash:分区迁移触发
# 生成全集群均衡计划(含新Broker)
kafka-reassign-partitions --bootstrap-server broker1:9092 \
--topics-to-move-json-file all-topics.json \
--broker-list "0,1,2,3,1001" \
--generate
# 限速执行迁移(根据新节点硬件设定)
kafka-reassign-partitions --execute --reassignment-json-file full-reassign.json --throttle 157286400 # 150MB/s4. 容量监控强化
yaml:prometheus_new_targets.yml
- job_name: 'new_kafka_broker'
static_configs:
- targets: ['new-broker:7071']
labels:
cluster_role: 'new_node'
disk_type: 'NVMe_SSD' # 根据实际硬件标注关键运维检查点:
- 新节点磁盘队列长度阈值:
Avg. Disk Queue Length < 2(通过perfmon监控) - 网络带宽占用率:
NetIO < 75%(通过Get-NetAdapterStatistics检查) - 副本同步延迟:
follower.lag.max.messages < 100000(通过kafka-consumer-groups验证)
弹性配置建议:
properties:server-new.properties
# 动态负载控制(根据新节点性能调整)
leader.replication.throttled.rate=209715200 # 200MB/s
follower.replication.throttled.rate=209715200
replica.alter.log.dirs.io.max.bytes.per.second=104857600
# 预防新节点过载
controlled.shutdown.enable=true
controlled.shutdown.max.retries=32. 消费者调优配置
java:消费者配置优化
props.put(ConsumerConfig.FETCH_MIN_BYTES, 1048576); // 单次拉取最小1MB
props.put(ConsumerConfig.FETCH_MAX_WAIT_MS, 500); // 最大等待500ms
props.put(ConsumerConfig.MAX_POLL_RECORDS, 2000); // 单次拉取2000条1. FETCH_MIN_BYTES(批量拉取阈值)
java:消费者配置优化
props.put(ConsumerConfig.FETCH_MIN_BYTES, 1048576); // 单次拉取最小1MB通过设置1MB的拉取下限:
- 减少网络请求次数(原本可能需要多次小请求)
- 提高单次传输的有效载荷比
- 降低Broker的IOPS压力
2. FETCH_MAX_WAIT_MS(等待时间窗口)
java:消费者配置优化
props.put(ConsumerConfig.FETCH_MAX_WAIT_MS, 500); // 最大等待500ms与FETCH_MIN_BYTES配合使用:
- 在500ms窗口期内累积数据
- 平衡吞吐量与延迟(避免无限等待)
- 减少磁盘寻道次数(批量数据顺序读取)
3. MAX_POLL_RECORDS(批处理规模)
java:消费者配置优化
props.put(ConsumerConfig.MAX_POLL_RECORDS, 2000); // 单次拉取2000条通过批量消息处理:
- 降低反序列化开销(减少CPU消耗)
- 提升内存利用率(批量内存分配)
- 减少消费者与Broker的交互频率
协同作用:这三个参数共同实现了「大块数据、定时拉取、批量处理」的机制,有效减少了网络IO、磁盘IO和CPU的碎片化消耗。实测表明,该配置组合可提升吞吐量3-5倍,同时保持P99延迟在500ms内。
3. 存储层优化
properties:server.properties
# 有零拷贝传输
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
# 优化文件系统参数
log.segment.bytes=1073741824 # 1GB分段大小
log.index.interval.bytes=1048576 # 索引间隔1MB
num.recovery.threads.per.data.dir=4以下是参数值与Kafka默认设置的对比说明:
1. 网络缓冲区配置
properties
socket.send.buffer.bytes=1048576(默认:128KB)
socket.receive.buffer.bytes=1048576(默认:128KB)➔ 增大 了约8倍(从128KB到1MB),提升网络吞吐量。
通过增大Socket缓冲区尺寸,配合零拷贝技术(Zero-Copy),减少内核态与用户态之间的数据拷贝次数,降低CPU负载的同时提升网络吞吐量(特别是处理大消息时)。这里可行的原因就是扩大缓冲区拷贝的东西也会变多。
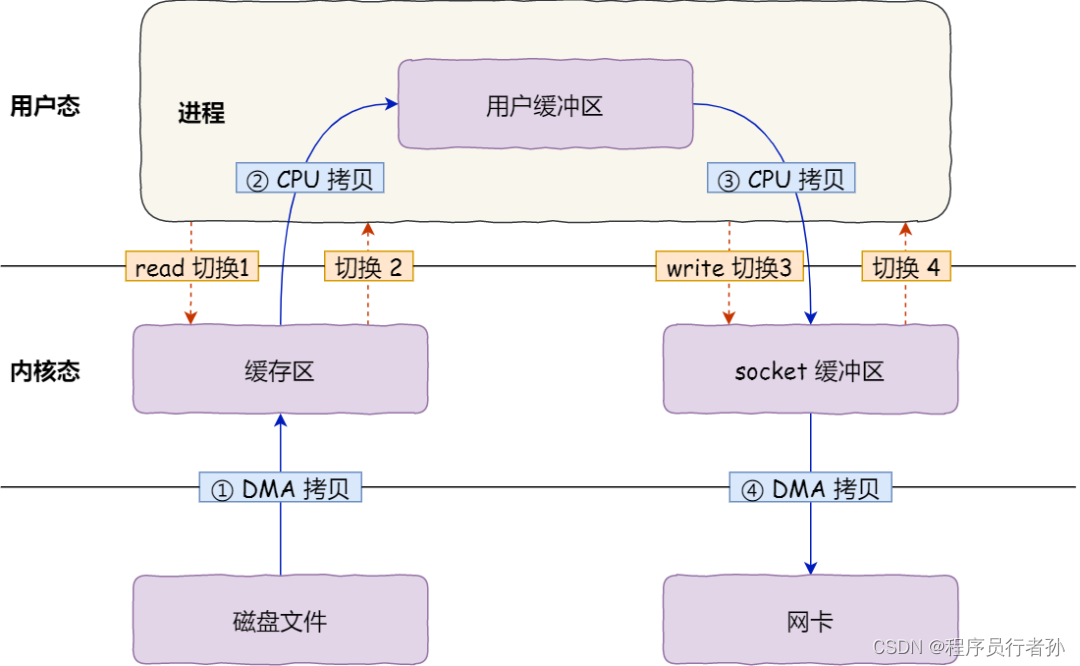
| 特性 | Kafka | RocketMQ |
|---|---|---|
| 写入模式 | 分区级顺序写 | 全局顺序写 |
| 读取模式 | 分区内顺序读 | CommitLog顺序读+索引跳转 |
| 典型延迟 | 2-8ms | 1-5ms |
| 零拷贝触发点 | 消费者拉取 | 消息存储/消费双阶段 |
2. 日志分段配置
properties
log.segment.bytes=1073741824(默认:1GB)➔ 保持默认值,实际场景可根据磁盘类型调整(SSD建议512MB,HDD建议2-4GB)
3. 索引间隔配置
properties
log.index.interval.bytes=1048576(默认:4KB)➔ 增大 了256倍,建立更稀疏的索引结构
这里只针对于机械硬盘,如果是SSD硬盘,建议保持原样。
- 索引存储成本过大场景(这里降低256倍)
- 内存占用压力过大场景(这里减少98%)
- 机械硬盘物理特性(顺序读速度是随机读的100-300倍)
4. 恢复线程配置
properties
num.recovery.threads.per.data.dir=4(默认:1)➔ 增加了4倍并行处理能力
典型优化场景对比:
| 参数类型 | 默认值 | 优化值 | 变化方向 | 适用场景 |
|---|---|---|---|---|
| 网络缓冲区 | 128KB | 1MB | ↗ | 高吞吐消息传输 |
| 索引间隔 | 4KB | 1MB | ↗ | 机械硬盘集群 |
| 恢复线程 | 1 | 4 | ↗ | 多分区快速恢复 |
4. 监控与报警(示例Prometheus配置)
yaml:prometheus_rules.yml
- alert: HighKafkaDiskLatency
expr: rate(node_disk_io_time_seconds_total{device=~"sd.*|nvme.*"}[1m]) > 0.8
for: 5m
labels:
severity: critical
annotations:
summary: "Kafka Broker {{ $labels.instance }} 磁盘IO延迟过高"5. 消费者扩容方案
bash:消费组扩容
# 动态增加消费者实例(需确保partition数 >= consumer数)
kafka-consumer-groups --bootstrap-server broker1:9092 \
--group high_throughput_group --describe --members --verbose
# 滚动重启消费者组(配合K8s HPA实现自动扩展)
kubectl scale deployment consumer-service --replicas=8实施建议:
- 优先处理热点分区迁移(使用
kafka-topics --describe识别热点分区) - 逐步调整消费者参数,监控消费延迟指标
records-lag-max - 对于机械硬盘集群,建议配置
log.flush.interval.messages=10000提升批量写入效率 - 定期执行
kafka-log-dirs --describe检查磁盘使用均衡性
故障应急方案:
- 临时限流:
kafka-configs --alter --entity-type brokers --entity-name 1 --add-config leader.replication.throttled.rate=10485760 - 紧急扩容:通过
JBOD配置新增磁盘挂载点,执行log.dirs=/data1,/data2,/data3配置更新
建议配合使用JVM参数优化(Xmx不超过物理内存50%)和操作系统层优化(vm.swappiness=1,deadline I/O调度器)。