目录
[1.了解过 MySQL 死锁问题吗?](#1.了解过 MySQL 死锁问题吗?)
[2.1 什么是死锁:](#2.1 什么是死锁:)
[2.2 形成死锁的四个必要条件是什么?](#2.2 形成死锁的四个必要条件是什么?)
[2.3 如何避免线程死锁?](#2.3 如何避免线程死锁?)
[3. MySQL 怎么排查死锁问题?](#3. MySQL 怎么排查死锁问题?)
[5. 详细说一下 MySQL 数据库中锁的分类(重要)](#5. 详细说一下 MySQL 数据库中锁的分类(重要))
[7. 行锁什么时候会退化成表锁](#7. 行锁什么时候会退化成表锁)
1.了解过 MySQL 死锁问题吗?
分析:
解释 MySQL 死锁是如何发生的。
- **回答:**了解过。
- 在并发事务中、当两个事务出现循环资源依赖、这两个事务都在等待别的事务释放资源时、就会导致这两个事务都进入无限等待的状态、这时候就发生了死锁
2.什么是线程死锁?死锁相关面试题
2.1 什么是 死锁 :
- 死锁是指两个或两个以上的进程(线程)在执行过程中、由于竞争资源而造成的一种阻塞的现象、若无外力作用、它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁、这些永远在互相等待的进程(线程)称为死锁进程(线程)。
- 多个线程同时被阻塞、它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞、因此程序不可能正常终止。
2.2 形成 死锁 的四个必要条件是什么?
- 互斥条件:在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源、就只能等待、直至占有资源的进程用毕释放。
- 占有且等待条件:指进程已经保持至少一个资源、但又提出了新的资源请求、而该资源已被其它进程占有、此时请求进程阻塞、但又对自己已获得的其它资源保持不放。
- 不可抢占条件:别人已经占有了某项资源、你不能因为自己也需要该资源、就去把别人的资源抢过来。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
- (比如一个进程集合、A在等B、B在等C、C在等A)
总结:
产生死锁的四个必要条件:
- 互斥条件:多个线程不能同时使用一个资源
- 持有并等待条件:线程A在等待资源2的同时并不会释放自己已经持有的资源1
- 不可剥夺条件:在自己使用之前不能被其他线程获取
- 循环等待条件:两个线程获取资源的顺序构成了环形链
2.3 如何避免线程 死锁 ?
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
- 破坏互斥条件:这个条件我们没有办法破坏、因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
- 破坏请求与保持条件:一次性申请所有的资源
- 破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时、如果申请不到、可以主动释放它占有的资源。
- 破坏循环等待条件:靠按序申请资源来预防、按某一顺序申请资源、释放资源则反序释放。破坏循环等待条件。
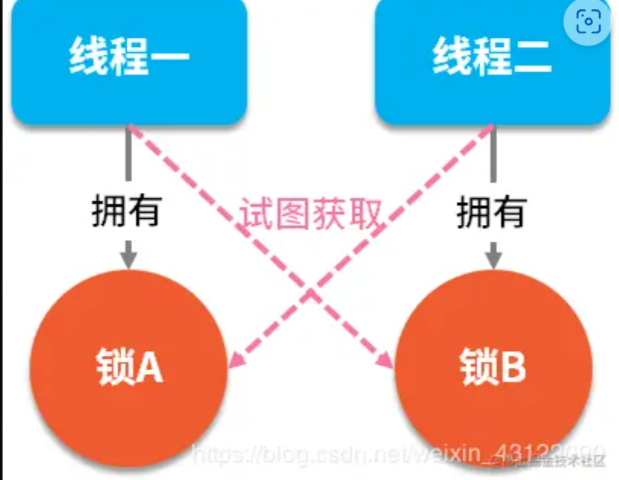
3. MySQL 怎么排查死锁问题?
**分析:**获取死锁日志、分析死锁日志
参考面试回答:
- 在遇到线上死锁问题时、我们应该第一时间获取相关的死锁日志。
- 我们可以通过
show engine innodb status命令来获取死锁信息。 - 然后就分析死锁日志。死锁日志通常分为两部分、上半部分说明了事务1在等待什么锁、下半部分说明了事务2当前持有的锁和等待的锁。
- 通过阅读死锁日志、我们可以清楚地知道两个事务形成了怎样的循环等待、然后根据当前各个事务执行的SQL分析出加锁类型以及顺序、逆向推断出如何形成循环等待、这样就能找到死锁产生的原因了
4.Java线上死锁问题如何排查
发生死锁的场景
循环等待 (Circular Wait): 这是最经典的死锁场景。也就是嵌套锁
-
线程 A 持有锁 1、并尝试获取锁 2。
-
线程 B 持有锁 2、并尝试获取锁 1。
-
结果:线程 A 和线程 B 都在等待对方释放锁、导致永久阻塞。
竞争不可剥夺资源:
两个进程都需要打印机和扫描仪。进程A先获得了打印机\进程B先获得了扫描仪。然后进程A请求扫描仪
进程B请求打印机 由于打印机和扫描仪都是不可剥夺的 两个进程都无法获得对方需要的资源 导致死锁。
可以简单概括如下:
-
识别 死锁 发生的现象: 确定应用是否表现出死锁的症状、如线程长时间处于阻塞状态。
-
获取线程堆栈信息: 通过工具(如
jstack)获取JVM线程堆栈、分析各线程的状态、尤其关注等待锁的线程。jstack+threaddump.txt、收集线程堆栈信息、threaddump.txt文件。 -
分析代码: 检查线程堆栈中的栈帧,定位发生死锁的代码区域。重点关注可能导致锁定的同步块或方法。在上一步生成的堆栈文件中查找
deadlock、waiting to lock、lock等有指向死锁的信息、确定代码中出现死锁的位置。 -
优化代码逻辑: 修复导致死锁的代码块,一般可以采用减少锁的粒度,使用非阻塞算法,或者重构为无锁设计。使用
ReentrantLock和tryLock()等机制避免长期持有锁等方式。 -
监控和测试: 持续监控应用运行时的线程情况,尤其是在高并发场景下。通过压力测试和代码审计尽早发现潜在的死锁问题。
面试回答:
- 首先就是命令
jps查看进程ID - 然后将进程ID对应的程序线程日志收集到文本中 方便后续分析
jstack -l 24360 > .wy.txt- 然后分析进程堆栈信息
- 打开 文件、搜索
deadlock、lock waiting to、locked关键字、以定位死锁或阻塞线程 - 然后优化代码逻辑
5. 详细说一下 MySQL 数据库中锁的分类(重要)
分析:
-
全局锁:通过
``flush tables with read lock语句会将整个数据库就处于只读状态了、这时其他线程执行以下操作、增删改或者表结构修改都会阻塞。全局锁主要应用于做全库逻辑备份、这样在备份数据库期间,不会因为数据或表结构的更新、而出现备份文件的数据与预期的不一样。 -
表级锁:MySQL 里面表级别的锁有这几种:
-
表锁:通过
lock tables语句可以对表加表锁、表锁除了会限制别的线程的读写外、也会限制本线程接下来的读写操作。 -
元数据锁:当我们对数据库表进行操作时、会自动给这个表加上 MDL、对一张表进行 CRUD 操作时、加的是 MDL 读锁、对一张表做结构变更操作的时候、加的是 MDL 写锁、MDL 是为了保证当用户对表执行 CRUD 操作时、防止其他线程对这个表结构做了变更。
-
意向锁:当执行插入、更新、删除操作、需要先对表加上「意向独占锁」、然后对该记录加独占锁。意向锁的目的是为了快速判断表里是否有记录被加锁。
-
-
行级锁:InnoDB 引擎是支持行级锁的、而 MyISAM 引擎并不支持行级锁。
-
记录锁:锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的、满足读写互斥、写写互斥
-
间隙锁:只存在于可重复读隔离级别、目的是为了解决可重复读隔离级别下幻读的现象。
-
Next-Key Lock 称为临键锁、是 Record Lock + Gap Lock 的组合、锁定一个范围、并且锁定记录本身。
-
插入意向锁、当插入位置的下一条记录有间隙锁、那么就会生成插入意向锁、然后进入阻塞状态
-
根据锁粒度的不同、MySQL 的锁可以分为全局锁、表级锁、行级锁。
-
我们熟悉的是表级锁和行级锁
-
比如我们对一张表结构进行修改的时候
-
MySQL 就会对这张表加一个元数据锁、元数据锁是属于表级锁的。
-
-
行级锁目前只有 InnoDB 存储引擎实现了、MyISAM 存储引擎是不支持行级锁的、只有表锁。
- InnoDB 存储引擎实现的行级锁主要有记录锁、间隙锁、临键锁、插入意向锁这些
-
当我们对表记录进行
select for update、或者增删改的时候、都会对记录加行级锁。 -
mysql的锁机制是数据库引擎锁的锁机制
-
间隙锁只在某些情况下才加:为了防止幻读
-
当前事务隔离级别是可重复隔离级别(MySQL默认)
-
查询使用了 FOR UPDATE 或 LOCK IN SHARE MODE
-
查询条件涉及范围查询 或 非唯一索引
-
在数据库使用非唯一索引 时、系统会使用间隙锁来防止其他事务在当前范围内插入新记录、确保当前事务的操作是可重复读 的。这是为了防止幻读现象(Phantom Read)、即一个事务在读取数据时、另一个事务可能插入了新的数据、使得前一个事务读取的数据不一致。
-
间隙锁会锁住一个范围的空白地带、这样即使在该范围内没有记录、其他事务也不能插入新的记录、从而避免了出现不一致的数据读取。
-
6.MySQL行级锁的原理是什么
行级锁是 MySQL 在存储引擎层(如 InnoDB)实现的、锁定的是表中某一行数据
首先行锁分为:
-
记录锁:锁住单个记录
-
间隙锁:这种锁锁定的是索引记录之间的"间隙",但不包括记录本身。例如如果索引上有值 10 和 20、间隙锁可以锁定 (10, 20) 这个开区间。它的主要目的是防止其他事务在这个间隙中插入新的记录、从而避免幻读问题。间隙锁只在可重复读(Repeatable Read)或更高的隔离级别下才生效。
-
Next-Key Lock 称为临键锁、是 Record Lock + Gap Lock 的组合、锁定一个范围、并且锁定记录本身。用于防止幻读、默认用于可重复度隔离级别。Next-Key Lock 是 InnoDB 在可重复读隔离级别下解决幻读问题的主要方式、是其默认的行锁算法
实现原理:
1. 实现原理核心 ------ 依赖索引:
InnoDB 的行级锁是通过给索引项加锁来实现的。这意味着当 InnoDB 更新、删除或(在某些情况下)查询一行数据、,它实际上是在这条记录对应的索引条目上施加锁。
关键点:
如果 SQL 语句的操作能够利用到索引(尤其是唯一索引或主键索引)、InnoDB 就会使用行级锁。
- 行锁什么时候会退化成表锁
如果 SQL 语句的条件没有命中任何索引、导致需要进行全表扫描、那么 InnoDB 通常会退化为对整个表加锁(表级锁)、或者锁定所有扫描过的行、这会极大地降低并发性能。
行锁分为:
- 记录锁:锁住单个记录
- 间隙锁:这种锁锁定的是索引记录之间的"间隙",但不包括记录本身。例如如果索引上有值 10 和 20、间隙锁可以锁定 (10, 20) 这个开区间。它的主要目的是防止其他事务在这个间隙中插入新的记录、从而避免幻读问题。间隙锁只在可重复读(Repeatable Read)或更高的隔离级别下才生效。
- Next-Key Lock 称为临键锁、是 Record Lock + Gap Lock 的组合、锁定一个范围、并且锁定记录本身。用于防止幻读、默认用于可重复度隔离级别。Next-Key Lock 是 InnoDB 在可重复读隔离级别下解决幻读问题的主要方式、是其默认的行锁算法
行锁的模式 (并发控制):
- 当一个事务获取了某行的锁后、这个锁会有不同的模式、决定了其他事务能否以及如何访问这行数据:
- 共享锁 (S Lock): 允许多个事务同时读取同一行数据。一个事务获取了某行的S锁后、其他事务也可以获取该行的S锁来读取、但任何事务都不能获取该行的排它锁来进行修改、直到所有S锁被释放。通常通过
SELECT ... LOCK IN SHARE MODE获取。 - 排它锁 (X Lock): 如果一个事务获取了某行的X锁、那么其他任何事务都不能再获取该行的S锁或X锁、直到第一个事务释放X锁。这意味着获取X锁的事务可以独占地读取和修改这行数据。通常通过
SELECT ... FOR UPDATE、或者在INSERT、UPDATE、DELETE操作中隐式获取。
加锁方式是:
-
执行如 SELECT ... FOR UPDATE、UPDATE、DELETE 语句时、InnoDB 会为匹配行加排它锁
-
SELECT ... LOCK IN SHARE MODE 则会加共享锁
7. 行锁什么时候会退化成表锁
一句话面试回答:
-
如果 SQL 语句的条件没有命中任何索引、导致需要进行全表扫描
-
那么 InnoDB 通常会退化为对整个表加锁(表级锁)、或者锁定所有扫描过的、,这会极大地降低并发性能
-
分析:
-
InnoDB 行锁的基础:锁定索引记录。我们首先要记住、InnoDB 实现行级锁的机制是在索引记录上加锁。当我们说锁住某一行时、InnoDB 实际上是在这一行数据对应的索引条目上施加了锁。
-
无索引时的全表扫描
- 如果一个
UPDATE或DELETE语句的WHERE子句中的列没有建立索引、或者优化器因为某种原因(比如索引选择性不高、数据量小等)决定不使用索引、那么 InnoDB 为了找到符合条件的行、就必须逐行扫描整个表的数据。
- 如果一个
-
全表扫描时的加锁行为
-
InnoDB 的行为通常是:它会在扫描过程中、对它访问到的每一行数据都尝试加上行级锁(通常是排他锁 X Lock)。
-
即使某一行最终不符合
WHERE条件、在它被扫描和判断的过程中、也可能被短暂地加锁。对于最终符合条件的行、锁会一直持有直到事务提交或回滚。
-
-
退化成表锁的实际效果
-
当 InnoDB 对全表扫描过程中接触到的几乎所有行都加上了行级锁时、尽管从机制上讲仍然是多个行锁,但其最终效果就非常类似于对整个表加了一个表锁。
-
这是因为:如果一个事务锁住了表中的大部分或所有、,其他需要访问这些行(即使是不同的行)的事务都会被阻塞,等待这些行锁被释放。此时并发性会急剧下降、就好像整个表被锁住了一样。
-
-
为什么不直接用一个表锁
-
InnoDB 的设计是尽可能提供细粒度的并发控制。即使是全表扫描、它也是在行级别上进行判断和加锁、这在某些特定情况下
-
(例如如果扫描的表非常小、或者符合条件的行很快被找到并锁定而、其他行的锁能快速释放)可能仍然比一个粗暴的表锁要好一点点、或者至少在内部机制上保持一致性。但对于用户感知到的并发性能而言、效果往往等同于表锁
-