"Sat2Density: Faithful Density Learning from Satellite-Ground Image Pairs",即从卫星-地面图像对中学习忠实的密度表示。论文的主要目标是开发一种能够准确表示卫星图像三维几何结构的方法,特别关注从卫星图像中合成具有3D意识的地面视图图像的挑战性问题。作者们提出了一种新的方法,称为Sat2Density,该方法受到体积神经渲染中使用的密度场表示的启发,利用地面视图全景图的属性来学习三维场景的忠实密度场。
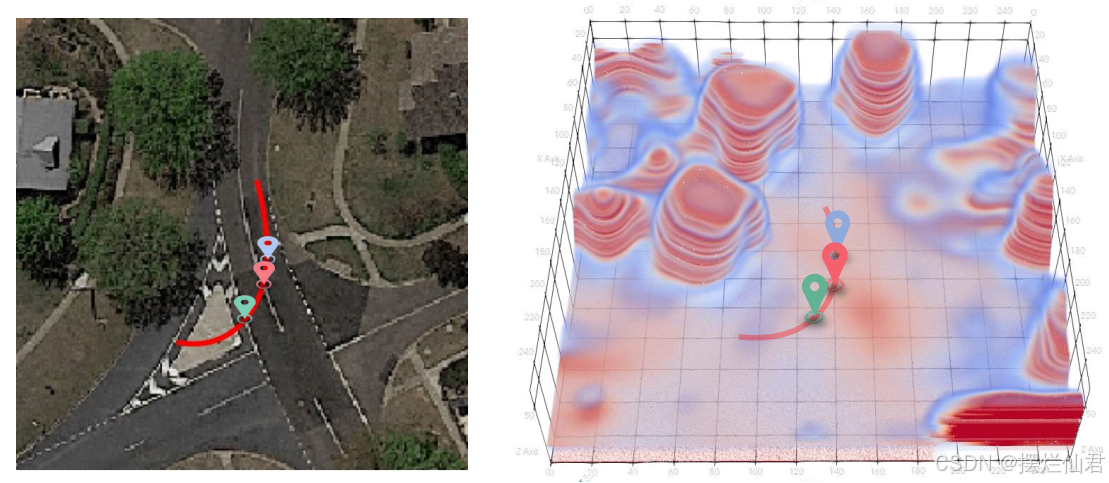
一、论文概述
论文的主要目标是开发一种能够准确表示卫星图像三维几何结构的方法,特别关注从卫星图像中合成具有3D意识的地面视图图像的挑战性问题。作者们提出了一种新的方法,称为Sat2Density,该方法受到体积神经渲染中使用的密度场表示的启发,利用地面视图全景图的属性来学习三维场景的忠实密度场。
1.深度信息
与其它需要在训练期间使用额外深度信息的方法不同,Sat2Density能够自动通过密度表示学习准确和忠实的3D几何结构,无需深度监督。
2.监督信号
为了解决几何学习中的挑战,如天空区域的无限性和不同地面图像之间的照明差异,作者提出了两种监督信号:非天空区域的不透明度监督和照明注入。
3.主要贡献
提出了一种几何方法Sat2Density,用于从卫星图像中端到端学习地面视图全景图合成。通过在密度场中显式建模具有挑战性的交叉视图合成任务,Sat2Density能够在不使用任何额外3D信息的情况下,为视频合成生成高保真全景图。
二、实施架构
1.输入
卫星图像:输入为高分辨率的卫星图像,表示为

其中H和W分别是图像的高度和宽度。
2.输出
地面视图全景图:输出为360°全景图,表示为
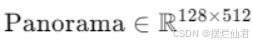
这是一个从地面视角合成的全景图像。
3.实施步骤
1. 密度场表示(Density Field Representation)
使用一个编码器-解码器网络(DensityNet),接收卫星图像作为输入,学习一个显式的体积密度场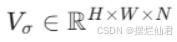 ,其中N是体积密度的层数。
,其中N是体积密度的层数。
2. 体积渲染(Volumetric Rendering)
利用体积渲染技术,通过查询射线上的点来渲染深度d和不透明度O。通过双线性插值从卫星图像中复制颜色,生成初始全景图。
3. RenderNet网络
RenderNet接收渲染的全景深度、不透明度和颜色的拼接张量作为输入,以合成高保真度的地面视图图像。
4. 监督信号
非天空不透明度监督(Non-Sky Opacity Supervision):使用天空分割模型获得训练全景图像的天空掩码,以监督密度场学习。
照明注入(Illumination Injection):从全景图的天空区域提取RGB直方图信息,并将其转换为固定维度的嵌入,以学习复杂的照明信息。
5. 损失函数
使用重建损失(包括感知损失、L1、L2损失)和对抗损失来训练Sat2Density。非天空不透明度监督和照明注入也通过特定的损失函数加入到训练过程中。
6. 训练和优化
使用Adam优化器进行端到端的训练,学习率设置为0.00005,β1=0,β2=0.999。训练过程中,模型通过最小化损失函数来优化网络参数。
7. 渲染和合成
在训练完成后,使用训练好的DensityNet和RenderNet网络,从新的卫星图像生成地面视图全景图。通过体积渲染技术,可以沿着任何视图方向渲染深度图和全景图。
三、代码详解
Sat2Density方法涉及到深度学习模型,包括DensityNet和RenderNet,以及体积渲染技术。
1. DensityNet网络
方法介绍: DensityNet是一个编码器-解码器网络,用于从卫星图像中学习显式的体积密度场。编码器逐步降低空间维度并增加特征维度,而解码器则逐步恢复空间维度并减少特征维度。最终输出是一个体积密度场,用于后续的体积渲染。
代码详解:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1), # 输入通道为3(RGB),输出通道为64
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, 2), # 下采样
# 可以添加更多的层
)
def forward(self, x):
return self.layers(x)
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.layers = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2), # 上采样
nn.ReLU(),
nn.Conv2d(64, 1, kernel_size=3, padding=1), # 输出通道为1,表示密度
nn.Sigmoid(), # 确保密度值在[0, 1]之间
)
def forward(self, x):
return self.layers(x)
class DensityNet(nn.Module):
def __init__(self):
super(DensityNet, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded2. RenderNet网络
方法介绍: RenderNet用于将渲染的全景深度、不透明度和颜色的拼接张量作为输入,以合成高保真度的地面视图图像。这个网络可以看作是一个图像到图像的转换网络,通常使用U-Net或类似的架构。
代码详解:
python
class RenderNet(nn.Module):
def __init__(self):
super(RenderNet, self).__init__()
self.upconv1 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.relu1 = nn.ReLU()
self.upconv2 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.relu2 = nn.ReLU()
self.upconv3 = nn.ConvTranspose2d(64, 3, kernel_size=2, stride=2)
self.relu3 = nn.ReLU()
self.conv_last = nn.Conv2d(3, 3, kernel_size=1) # 最终输出通道为3(RGB)
def forward(self, x):
x = self.upconv1(x)
x = self.relu1(x)
x = self.upconv2(x)
x = self.relu2(x)
x = self.upconv3(x)
x = self.relu3(x)
x = self.conv_last(x)
return x3. 体积渲染
方法介绍: 体积渲染是一种计算机图形技术,用于从体积数据生成2D图像。在Sat2Density中,体积渲染用于从学习到的密度场生成深度和不透明度。
代码详解:
python
def volume_rendering(density_field, ray_origins, ray_directions, num_samples=100):
"""
简化的体积渲染函数
density_field: 密度场
ray_origins: 射线起点
ray_directions: 射线方向
num_samples: 采样点数
"""
colors = []
for i in range(num_samples):
t = i / (num_samples - 1)
ray = ray_origins + ray_directions * t
density = density_field(ray) # 假设density_field是一个可调用的函数
colors.append(density)
colors = torch.stack(colors, dim=0)
return torch.sum(colors, dim=0) / num_samples这些代码示例提供了一个基本的框架,用于理解Sat2Density方法中的关键组件。实际实现会更加复杂,涉及到更多的细节,如网络层的具体设计、损失函数的定义、数据加载和预处理等。
四、项目改进
1.改进思路
为了进一步发展和思考Sat2Density模型,我们可以探索以下几个方面:
- 改进网络架构:尝试不同的网络架构,比如引入注意力机制或者使用更深层的网络结构。
- 增强数据预处理:通过更复杂的数据增强技术来提高模型的泛化能力。
- 优化损失函数:尝试不同的损失函数组合,以更好地捕捉图像间的复杂关系。
- 多尺度特征融合:在RenderNet中引入多尺度特征融合,以提高细节捕捉能力。
- 实时渲染优化:探索实时渲染技术,以减少模型的推理时间。
2. 引入注意力机制
python
class AttentionBlock(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(AttentionBlock, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
return x * psi
# 在RenderNet中加入注意力模块
class RenderNetWithAttention(nn.Module):
def __init__(self):
super(RenderNetWithAttention, self).__init__()
self.attention_block = AttentionBlock(128, 64, 64)
# 其他层定义...
def forward(self, x, g):
# 其他层...
x = self.attention_block(g, x)
# 其他层...
return x分析:注意力机制可以帮助模型更好地聚焦于图像中的重要部分,从而提高合成图像的质量。
3. 多尺度特征融合
python
class FeatureFusionBlock(nn.Module):
def __init__(self):
super(FeatureFusionBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(256, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True)
)
def forward(self, features):
output = torch.cat(features, dim=1)
output = self.conv(output)
return output
# 在RenderNet中加入特征融合模块
class RenderNetWithFeatureFusion(nn.Module):
def __init__(self):
super(RenderNetWithFeatureFusion, self).__init__()
self.fusion_block = FeatureFusionBlock()
# 其他层定义...
def forward(self, x):
features = [self.layer1(x), self.layer2(x), self.layer3(x)]
fused_features = self.fusion_block(features)
# 使用融合的特征进行后续处理...
return fused_features分析:多尺度特征融合可以帮助模型在不同尺度上捕捉细节,增强特征的表达能力。
4.. 实时渲染优化
class FastRenderNet(nn.Module):
def __init__(self):
super(FastRenderNet, self).__init__()
self.conv1 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(64, 3, kernel_size=3, padding=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = torch.tanh(self.conv2(x))
return x分析:简化网络结构和使用更少的层可以减少模型的计算量,从而实现更快的渲染速度。